【今日CV 计算机视觉论文速览 第134期】Fri, 21 Jun 2019
今日CS.CV 计算机视觉论文速览
Fri, 21 Jun 2019
Totally 34 papers
?上期速览✈更多精彩请移步主页

Interesting:
?基于多任务度量学习的三维实例分割, 提出了一个基于体素的实例分割方法。其主要目的是从数据中提取个体的形状信息,以及物体间的相关性和遮挡等。研究人员提出多任务方法解决这一问题,一方面学习特征空间将同一实例的体素进行聚类,第二个目标是学习估计实例中每个体素相对于质心的朝向信息,用于寻找实例的边界。(from KAUST ETHZ )
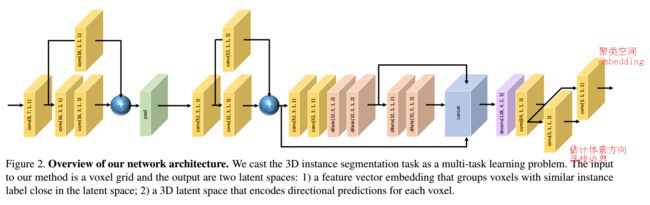
嵌入空间的聚类和方向预测:

研究人员还合成了数据进行训练:


最后聚类分割的结果:

真实数据集上的表现:
datset: ScanNet 3d:[4] A. Dai, A. X. Chang, M. Savva, M. Halber, T. Funkhouser,and M. Nießner. Scannet: Richly-annotated 3d reconstructionsof indoor scenes. In Proc. International Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
ref:Via the ScanNet [4] benchmark we further compare against recent submissions: Mask R-CNN proj [17], SGPN [37], GSPN [53], 3D-SIS [18],MASC [30], PanopticFusion [34], Occipital-SCS, and3D-BoNet [52].
author: Jean Lahoud , Bernard Ghanem, Marc Pollefeys, Martin R. Oswald
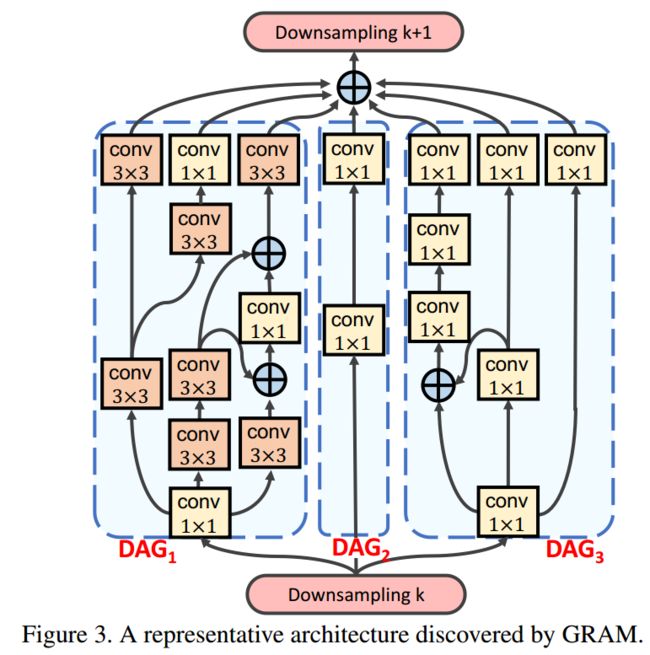
?SwiftNet基于图传播和元知识搜索高表达能力的网络架构GRAM, 提出了一种基于图传播作为元知识的搜索方法来适应细粒度的搜索,不断积累知识并更新元知识图的迭代过程。(from 杜克大学)
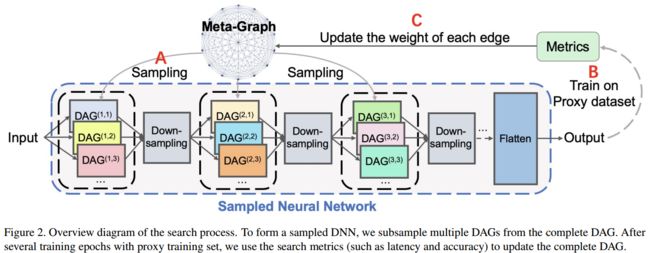
一种搜索出的高表达能力的架构以及与其他方法比较的结果:

?行人重识别的新基准和新结构BNNect, 提出了一种简单方法实现高效的行人重识别,利用ResNet50的特征作为输出并使用一系列技巧达到了最优的行人重识别效果,加入了各种技巧提升的模型精度:Warm up learning rate,Random erasing augmentation,Label smoothing,Last stride,BNNeck,Center loss。网络中在全局池化层后加入了一种新的批归一化neck层,将度量和分类损失分离到了不同的特征空间中去。(from 浙江大学)

BNNeck的结构变化:

各种训练技巧带来的性能提升:
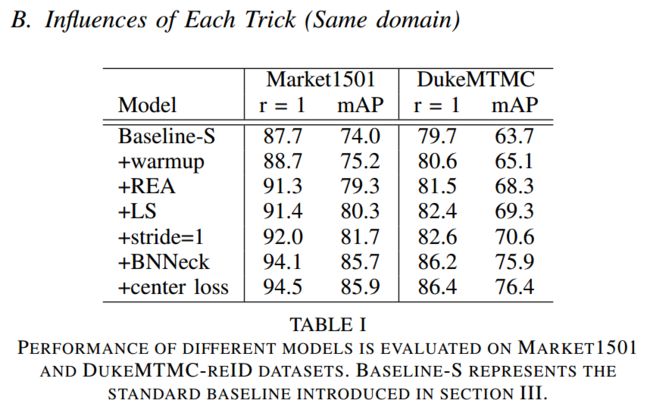
dataset:Market1501 DukeMTMC-reID
code:https://github.com/michuanhaohao/reid-strong-baseline
Daily Computer Vision Papers
| ***在线RGB-D相机定位问题Let's Take This Online: Adapting Scene Coordinate Regression Network Predictions for Online RGB-D Camera Relocalisation Authors Tommaso Cavallari, Luca Bertinetto, Jishnu Mukhoti, Philip Torr, Stuart Golodetz ***许多应用程序需要在线重新定位摄像机,而无需在目标场景上进行昂贵的离线培训。虽然关键帧和稀疏关键点匹配方法都可以在线使用,但前者常常远离训练轨迹,而后者可能在无纹理区域中挣扎。相比之下,场景坐标回归SCoRe方法推广到新颖的姿势,并且可以利用密集的对应来提高鲁棒性,最近的工作已经展示了如何在场景之间调整SCoRe森林,允许他们在线利用他们的最新技术性能。但是,因为它们使用手工制作的室内使用功能,所以它们不能很好地适用于较难的户外场景。虽然用神经网络替换森林并且学习适合户外使用的特征是可能的,但是难以将用于在场景之间调整森林的技术转移到网络环境中。在本文中,我们通过提出一种利用在一个场景上训练的网络来预测另一个场景中的点的新方法来解决这个问题。我们的方法用一个两步过程替换回归林的分支结构执行的外观聚类,该过程首先使用网络预测原始场景中的点,然后使用这些预测点从新场景中查找点簇。我们通过实验证明,我们的在线方法在7场景和剑桥地标数据集上实现了最先进的性能,同时在300毫秒以下运行,使其在现场场景中非常有效。 |
| **Deep-Learning-Based Aerial Image Classification for Emergency Response Applications Using Unmanned Aerial Vehicles Authors Christos Kyrkou, Theocharis Theocharides 配备有摄像头传感器的无人驾驶飞行器无人机可以促进许多应急响应和灾难管理应用的态势感知,因为它们能够在远程和难以进入的区域进行操作。此外,通过利用嵌入式平台和深度学习,无人机可以自动监测受灾地区,实时分析图像,并在出现各种灾难(如倒塌的建筑物,洪水或火灾)时发出警报,以便更快地减轻其影响关于环境和人口。为此,本文重点介绍了无人机上灾难事件的自动空中场景分类。具体地,介绍了用于紧急响应AIDER应用的专用航空图像数据库,并且执行了对现有方法的比较分析。通过这种分析,开发了一种轻量级卷积神经网络CNN架构,能够在嵌入式平台上高效运行,与现有型号相比,具有最低内存要求,与现有技术相比精度下降不到2倍,性能提高3倍。这些初步结果为使用无人机的应急响应应用的实时航空图像分类的进一步实验提供了坚实的基础。 提出了航拍的自然灾害数据集:https://sites.google.com/site/chriskyrkou/ |
| Homogeneous Vector Capsules Enable Adaptive Gradient Descent in Convolutional Neural Networks Authors Adam Byerly, Tatiana Kalganova 胶囊是Geoffrey Hinton给矢量值神经元的名称。神经网络传统上为激活的神经元产生标量值。另一方面,胶囊产生值的矢量,Hinton认为该矢量对应于单个复合特征,其中矢量分量的值指示特征的属性,例如变换或对比度。我们提出了一种参数化和训练胶囊的新方法,我们称之为均质载体胶囊HVCs。我们通过实验证明,与使用单个最终完全连接层的CNN相比,改变卷积神经网络CNN以使用HVC可以实现优异的分类准确度而不增加其架构中的参数或操作的数量。此外,HVC的引入使得能够使用自适应梯度下降,从而降低了模型可实现的精度对非自适应优化器的精细调整的超参数的依赖性。我们使用两个神经网络架构演示了我们的方法和结果。首先,一个非常简单的单片CNN,当使用HVC时,在前1个分类准确度方面取得了63项改进,在基线架构方面实现了前5个分类准确度的35项改进。其次,CNN架构被称为Inception v3,无论是否有HVC,都能达到相似的精度。此外,使用HVC时的简单单片CNN在超过300个时期后未显示过度拟合,而基线在30个时期后显示过度拟合。我们在两个网络中使用ImageNet ILSVRC 2012分类挑战数据集。 |
| Performance Evaluation Methodology for Long-Term Visual Object Tracking Authors Alan Luke i , Luka ehovin Zajc, Tom Voj , Ji Matas, Matej Kristan 提出了长期视觉对象跟踪性能评估方法和基准。通过遵循长期跟踪定义来设计性能测量,以最大化分析探测强度。新措施在解释潜力方面优于现有措施,并更好地区分不同的追踪行为。我们表明这些措施概括了短期绩效指标,从而将两个跟踪问题联系起来。此外,新测量对于时间注释稀疏性非常稳健,并且允许对序列的注释比当前数据集中的数百倍长,而不增加手动注释劳动。提出了一个具有许多目标消失的精心挑选序列的新挑战数据集。提出了一种新的跟踪分类法,用于在短期长期频谱上定位跟踪器。该基准包含对最大数量的长期攻击者的广泛评估,并与最先进的短期跟踪器进行比较。我们分析了跟踪架构实现对长期性能的影响,并探讨了各种重新检测策略以及视觉模型更新策略对长期跟踪漂移的影响。该方法被集成到VOT工具包中,以自动化实验分析和基准测试,并促进长期跟踪器的未来发展。 |
| ***3D Instance Segmentation via Multi-task Metric Learning Authors Jean Lahoud, Bernard Ghanem, Marc Pollefeys, Martin R. Oswald 我们提出了一种新颖的方法,例如密集的3D体素网格的标签分割。我们针对已经使用深度传感器或多视图立体方法获取并且已经使用语义3D重建或场景完成方法处理的体积场景表示。主要任务是学习有关单个对象实例的形状信息,以便准确地分离它们,包括连接和未完全扫描的对象。我们使用多任务学习策略解决3D实例标签问题。第一个目标是学习一个抽象的特征嵌入,它将具有相同实例标签的体素分组,彼此接近,同时将具有不同实例标签的集群彼此分开。第二个目标是通过为每个体素密集地估计实例质量中心的方向信息来学习实例信息。这对于在聚类后处理步骤中查找实例边界以及对第一个目标的分段质量进行评分特别有用。合成和现实世界的实验都证明了我们的方法的可行性。我们的方法在ScanNet 3D实例分割基准上实现了最先进的性能。 |
| Learning Generalized Transformation Equivariant Representations via Autoencoding Transformations Authors Guo Jun Qi 学习变换等变量表示TER旨在通过与应用变换等效的表示来捕捉图像的内在视觉结构。它假定转换应该在转换之前和之后从图像的表达表示中解码。它极大地扩展了em平移等价的范围,指出了卷积神经网络CNN成功开发出一类通用的em变换等变表示。与限制于离散变换或线性变换等效的组等变卷积不同,我们提出了一种更灵活,易处理的AutoEncoding Transformation AET模型,可以处理各种类型的变换。提出了确定性AET和概率自动编码变分变换AVT模型。虽然前者通过直接重建应用的变换来训练变换等变表示,但后者通过最大化表示和变换之间的联合互信来训练。它通过使得它们能够捕获转换视觉结构的更复杂模式超出变换组的线性TER,从而导致广义TERs GTER以更一般的方式等同于变换。我们将进一步表明,通过联合最大化关于输入标签和变换的学习表示中的互信息,可以将所呈现的方法扩展到半监督模型。遵循标准评估方案的实验结果证明了所提出的模型对于文献中的无监督和半监督方法的现有技术的优越性能。 |
| BGrowth: an efficient approach for the segmentation of vertebral compression fractures in magnetic resonance imaging Authors Jonathan S. Ramos, Carolina Y. V. Watanabe, Marcello H. Nogueira Barbosa, Agma J. M. Traina 医学图像的分割是一个关键问题,分析和分类的几个过程依赖于这种分割。随着越来越多的人出现背痛和与之相关的问题,骨折椎体的自动或半自动分割成为一项具有挑战性的任务。一般来说,这些裂缝呈现出几个非均匀强度的区域,暗区与附近的结构非常相似。为了克服这一挑战,本文提出了一种半自动分割方法,称为平衡生长BGrowth。在102个压碎和89个正常椎骨的数据集上的实验结果表明,我们的方法明显优于文献中众所周知的方法。我们已经达到了高达95的精度,同时保持了可接受的处理时间性能,这相当于现有技术的状态。此外,即使使用粗略的手工注释种子点,BGrowth也能提供最佳效果。 |
| Companion Surface of Danger Cylinder and its Role in Solution Variation of P3P Problem Authors Bo wang, Hao Hu, Caixia Zhang 传统上,危险气缸与P3P问题中的溶液稳定性密切相关。在这项工作中,我们表明危险气缸也与多重解决现象密切相关。更具体地说,我们展示了当光学中心位于危险圆柱体上时,在3种可能的P3P解决方案中,即一种双解决方案,以及另外两种解决方案,双解决方案的光学中心仍然位于危险圆柱体上,但光学中心其他两种解决方案的中心不再位于危险气缸上。当光学中心在危险圆柱体上移动时,相应P3P问题的另外两个解的光学中心形成一个新的表面,其特征在于光学中心坐标中12度的多项式方程,称为危险伴随面。气缸CSDC。这意味着危险气缸总是有一个伴侣表面。对于CSDC的重要性,我们表明当光学中心通过CSDC时,P3P问题的解决方案的数量必须改变2.这意味着CSDC充当P3P解空间的定界表面。这些新发现为P3P多解决方案现象提供了新的亮点,这是PnP研究中的一个重要问题。 |
| **历史文献中模式定位问题Pattern Spotting in Historical Documents Using Convolutional Models Authors Ignacio beda, Jose M. Saavedra, St phane Nicolas, Caroline Petitjean, Laurent Heutte 模式定位包括使用图像查询在历史文档图像的集合中搜索图形对象的出现。与对象检测相反,没有给出关于查询的先验信息或预定义类,因此训练对象的模型是不可行的。在本文中,提出了一种卷积神经网络方法来解决这个问题。我们使用RetinaNet作为特征提取器来获取文档区域的多尺度嵌入以及查询。在DocExplore数据集上进行的实验表明,我们的提议更好地定位模式,并且需要比现有技术系统更少的存储索引图像,但是在检索包含多个查询实例的页面时失败了。 |
| vireoJD-MM at Activity Detection in Extended Videos Authors Fuchen Long, Qi Cai, Zhaofan Qiu, Zhijian Hou, Yingwei Pan, Ting Yao, Chong Wah Ngo 本笔记本文件概述和比较分析了我们的系统,用于扩展视频中的活动检测ActEV PC在ActivityNet Challenge 2019中。具体来说,我们利用空间级别的人员车辆检测和时间级别的动作定位来监控视频中的动作检测。研究了不同小管生成的机理和模型分解方法。最后通过融合每个组分的结果来预测检测结果。 |
| **From Zero-Shot Learning to Cold-Start Recommendation Authors v Li, Mengmeng Jing, Ke Lu, Lei Zhu, Yang Yang, Zi Huang 零射击学习ZSL和冷启动推荐CSR分别是计算机视觉和推荐系统中的两个具有挑战性的问题。一般而言,他们在不同的社区中独立调查。然而,本文揭示了ZSL和CSR是同一意图的两个扩展。例如,它们都试图预测看不见的类并涉及两个空间,一个用于直接特征表示,另一个用于补充描述。然而,从ZSL的角度来看,没有现成的方法可以解决CSR问题。这项工作首次将CSR作为ZSL问题制定,并提出量身定制的ZSL方法来处理CSR。具体来说,我们提出了一种低秩线性自动编码器LLAE,它挑战了三个关键点,即域移位,伪相关和计算效率。 LLAE由两部分组成,低秩编码器将用户行为映射到用户属性,而对称解码器从用户属性重建用户行为。对ZSL和CSR任务进行的大量实验验证了所提出的方法是一个双赢的方案,即,与几种传统的现有技术方法相比,不仅可以通过ZSL模型处理CSR,而且可以显着提高性能,但是CSR的考虑也可以使ZSL受益。 |
| Multiple-Identity Image Attacks Against Face-based Identity Verification Authors Jerone T. A. Andrews, Thomas Tanay, Lewis D. Griffin 面部验证系统易受中毒攻击的影响,该中毒攻击利用多个身份图像MII面对存储在类似于多个人的数据库中的图像,使得任何组成人的新图像被验证为匹配MII的身份。对这种攻击模式的研究主要集中在通过检测进行防御,没有解释为什么存在漏洞。提出了新的定量结果,支持根据验证系统使用的表示空间的几何形状进行解释。在这些空间的球面几何形状中,匹配和非匹配的面部表示对的角距离分布仅适度地分开,分别以90度和40度60度为中心。这对于正常数据的开放式验证已足够,但却为MII攻击提供了机会。我们的分析考虑了理想的MII算法,证明如果可以实现,它们将从其组成面提供大约45度的面,因此被归类为匹配它们。我们研究了MII生成图库搜索,图像空间变形和表示空间反演这三种方法的性能,并表明后两者实现了理想,足以产生有效的攻击,而前者可以成功,但只有一个令人难以置信的大型画廊搜索。图库搜索和反转MII依赖于访问面部比较器,以进行优化,但我们的结果表明,这些攻击在攻击不同的比较器时仍然有效,因此保护部署的比较器是不充分的防御。 |
| PointNLM: Point Nonlocal-Means for vegetation segmentation based on middle echo point clouds Authors Jonathan Li, Rongren Wu, Yiping Chen, Qing Zhu, Zhipeng Luo, Cheng Wang 覆盖一个或几个对应点的中间回波是由多回波激光扫描仪获取的特定类型的3D点云。在本文中,我们提出了一种利用LiDAR点云的中间回波信息进行树木自动分割的新方法。首先,使用卷积分类方法,从所有点云中识别由中间回波反射的所提出的点云类型。中间回波点云与第一个和最后一个回波区分开来。因此,可以从大量的点云中快速检测到树冠位置。其次,为了准确地从所有点云中提取树木,我们提出了一种3D深度学习网络PointNLM,用于语义分割树冠。 PointNLM通过非局部分支捕获点云之间的长距离关系,并通过应用于无序点的最大池来提取高级特征。使用Semantic 3D简化测试集评估整个框架。树点云分割的IoU达到0.864。此外,使用Paris Lille 3D数据集测试语义分割网络。平均IoU表现优于其他几种流行方法。实验结果表明,该算法为LiDAR点云的植被分割提供了一种很好的解决方案。 |
| **目标检测GAN-Knowledge Distillation for one-stage Object Detection Authors Wei Hong, Jingke Yu 卷积神经网络在目标检测的准确性方面具有显着的改进。随着卷积神经网络变得更深,检测的准确性也明显提高,需要更多的浮点计算。许多研究人员使用知识蒸馏方法,通过在对象检测中将知识从越来越大的教师网络转移到小型学生网络来提高学生网络的准确性。大多数知识蒸馏方法需要设计复杂的成本函数,它们针对的是两阶段目标检测算法。本文提出了一种清洁有效的一阶段目标检测知识蒸馏方法。由教师网络和学生网络生成的特征图分别用作真实样本和假样本,并为两者生成对抗训练,以提高学生网络在一阶段对象检测中的性能。 智云视图zeusee:http://www.zeusee.com/index.html 奇点云startdt:https://www.startdt.com/ |
| Nested Network with Two-Stream Pyramid for Salient Object Detection in Optical Remote Sensing Images Authors Chongyi Li, Runmin Cong, Junhui Hou, Sanyi Zhang, Yue Qian, Sam Kwong 由于光学遥感图像RSI中的各种物体类型和尺度,不同的成像方向和杂乱的背景,很难直接将自然场景图像的显着物体检测的成功扩展到光学RSI。在本文中,我们基于网络体系结构的形状提出了一种名为LV Net的端到端深度网络,它以纯数据驱动的方式检测来自光学RSI的显着对象。所提出的LV网络由两个关键模块组成,即,两个流金字塔模块L形模块和具有嵌套连接V形模块的编码器解码器模块。具体地,L形模块通过使用两流金字塔结构分层地提取一组互补信息,这有利于感知显着对象的不同尺度和局部细节。 V形模块通过嵌套连接逐渐将编码器细节特征与解码器语义特征相结合,旨在抑制杂乱的背景并突出显着的对象。此外,我们构建了第一个公开可用的用于显着物体检测的光学RSI数据集,包括具有不同空间分辨率的800个图像,不同的显着性类型和像素明智的基础事实。对该基准数据集的实验表明,所提出的方法在性质和数量上都优于现有技术的显着对象检测方法。 |
| Improving the robustness of ImageNet classifiers using elements of human visual cognition Authors A. Emin Orhan, Brenden M. Lake 我们研究了ImageNet规模的图像识别模型的鲁棒性,该模型具有受人类视觉启发的两个特征,一个明确的情景记忆和一个形状偏差。正如之前的工作所报告的那样,我们表明,在一些威胁模型下,一个明确的情景记忆提高了图像识别模型对小规范对抗性扰动的鲁棒性。然而,它不能提高对更自然,通常更大的扰动的鲁棒性。在第二种意义上,在训练期间学习更强大的特征似乎对于鲁棒性是必要的。我们展示了从鼓励学习全局,基于形状的表示的模型得到的特征Geirhos等,2019不仅提高了对抗自然扰动的鲁棒性,而且当与情景记忆结合使用时,它们还提供了额外的鲁棒性。对抗性扰动。最后,我们针对情景记忆存储器大小,存储器的维度和检索方法提出了三个重要的设计选择。我们表明,为了使情景记忆更紧凑,最好通过聚类来减少记忆的数量,而不是减少它们的维度。 |
| A Strong Baseline and Batch Normalization Neck for Deep Person Re-identification Authors Hao Luo, Wei Jiang, Youzhi Gu, Fuxu Liu, Xingyu Liao, Shenqi Lai, Jianyang Gu 本研究探索了一个简单但强大的人员识别ReID基线。具有深度神经网络的人ReID近年来取得了进步并取得了很高的性能。然而,许多最先进的方法设计复杂的网络结构并连接多分支特征。在文献中,一些有效的训练技巧简要地出现在几篇论文或源代码中。本研究收集和评估这些有效的培训技巧亲自ReID。通过组合这些技巧,该模型仅使用ResNet50的全局特征,在Market1501上实现了94.5等级1和85.9平均精度。性能超过所有现有的全球和部分基线亲自ReID。我们提出了一种名为批量标准化颈部BNNeck的新型颈部结构。 BNNeck在全局池层之后添加批量规范化层,以将度量和分类损失分成两个不同的特征空间,因为我们观察到它们在一个嵌入空间中不一致。扩展实验表明,BNNeck可以提高基线,我们的基线可以提高现有技术方法的性能。我们的代码和型号可在 |
| **光场数据集基于lytro光场相机Light Field Saliency Detection with Deep Convolutional Networks Authors Jun Zhang, Yamei Liu, Shengping Zhang, Ronald Poppe, Meng Wang 由于CNN具有突出的特征表示能力,已经证明基于CNN的方法对于RGB图像的显着性检测很有效。然而,当在高度杂乱或类似背景中检测到多个显着区域时,它们的性能会降低。为了解决这些问题,在本文中,我们采用光场成像,记录每个像素的颜色强度以及入射光线的方向,因此可以提高由于空间和角度的使用而进行显着性检测的性能。在光场图像中编码的图案。然而,使用基于CNN的方法对光场图像进行显着性检测并非易事,因为这些方法不是专门设计用于处理光场输入,并且当前光场数据集不足以训练CNN。为了克服这些问题,我们首先提出了一个新的Lytro Illum数据集,其中包含640个光场及其相应的微透镜图像,中心观察图像以及地面真实显着图。与当前光场显着性数据集相比,Li14,Zhang17,新数据集更大,质量更高,包含更多变化和更多类型的光场输入,适用于训练更深层次的网络以及更好的基准算法。此外,我们提出了一种新颖的端到端CNN基于光场显着性检测的框架及其几种变体。我们系统地研究不同变体的影响,并将光场显着性与常规2D显着性与所提出的网络的性能进行比较。我们还进行了广泛的实验比较,这表明我们的网络在提议的数据集上明显优于最先进的方法,并且在其他现有数据集上具有所需的泛化能力。code:https://github.com/pencilzhang/LFNet-light-field-saliency-net |
| Learning the Sampling Pattern for MRI Authors Ferdia Sherry, Martin Benning, Juan Carlos De los Reyes, Martin J. Graves, Georg Maierhofer, Guy Williams, Carola Bibiane Sch nlieb, Matthias J. Ehrhardt 压缩传感理论的发现使人们认识到,即使测量不完整,也可以解决许多反问题。这在磁共振成像MRI中特别有趣,其中长采集时间可限制其使用。在这项工作中,我们考虑了学习稀疏采样模式的问题,该模式可用于最佳地平衡采集时间与重建图像的质量。我们使用监督学习方法,假设我们的训练数据足以代表新数据采集。我们证明情况确实如此,即使训练数据只包含5对训练对象和地面实况图像,训练集大小为192×192,例如,其中一个学习模式样本只有32然而,在相似图像的测试集上,k空间的结果导致具有平均SSIM 0.956的重建。拟议的框架足以学习任意采样模式,包括笛卡尔,螺旋和径向采样等常见模式。 |
| An Improved Trade-off Between Accuracy and Complexity with Progressive Gradient Pruning Authors Le Thanh Nguyen Meidine, Eric Granger, Madhu Kiran, Louis Antoine Blais Morin 虽然深度神经网络NN在许多视觉识别任务中已经达到了最先进的精度,但是网络的计算复杂性和能量消耗的增长仍然是一个问题,特别是对于资源有限且需要实时处理的平台上的应用。最近,信道修剪技术显示出压缩卷积NN CNN的有希望的结果。然而,这些技术可能导致低精度和复杂的优化,因为有些仅在训练CNN之后进行修剪,而其他技术通过整合稀疏性约束或修改损失函数在训练期间从头开始修剪。渐进式软滤波器修剪技术提供了更高的训练效率,但其软修剪策略无法实现更好优化所需的后向通过。本文提出了一种新的渐进式梯度修剪PGP技术,用于训练过程中的迭代通道修剪。它依赖于衡量改善现有渐进修剪的信道权重变化的标准,以及在后向传播过程中适应动量张量的有效硬和软修剪策略。在MNIST和CIFAR10数据集上训练各种CNN后获得的实验结果表明,与现有技术的通道修剪技术相比,PGP技术可以在分类精度和网络时间与内存复杂度之间实现更好的权衡。 |
| Clustering and Classification Networks Authors Jin mo Choi 在本文中,我们将描述一种网络体系结构,该体系结构展示了各种大小的数据集的高性能。为此,我们将通过将完全连接的层划分为现有网络架构中的三个级别来执行架构搜索。第一步是学习现有的CNN层和现有的完全连接层1个时期。第二步是通过将L1距离应用于Softmax的结果来聚类相似的类。第三步是使用聚类类掩码重新分类。我们通过顺序地或递归地执行上述三个步骤来完成现有技术的结果。该技术在Cifar 100上记录了11.56的误差。 |
| **隐私区域识别加密Reversible Privacy Preservation using Multi-level Encryption and Compressive Sensing Authors Mehmet Yamac, Mete Ahishali, Nikolaos Passalis, Jenni Raitoharju, Bulent Sankur, Moncef Gabbouj 通过无处不在的摄像机进行安全监控及其在智能建筑中的更多扩展,可以从信号处理和机器学习的进步中获益。虽然这些创新和突破性的应用程序可以被视为一种福音,但同时它们也引发了重大的隐私问题。事实上,最近的GDPR通用数据保护法规已经突出并成为隐私保护解决方案的激励因素。典型的隐私保护视频监控方案通过匿名敏感数据来解决这些问题。然而,这些方法受到一些限制,因为它们通常是不可逆的,不提供多级解密并且计算成本高。在本文中,我们提供了一种新的隐私保护方法,该方法是可逆的,支持多个隐私级别的识别,并且通过将多级加密与压缩感知相结合,可以有效地执行数据采集,加密和数据隐藏。已经使用重建质量的良好性和面部的强烈匿名化来验证所提出的方法在保护用户身份方面的有效性。 |
| The Limited Multi-Label Projection Layer Authors Brandon Amos, Vladlen Koltun, J. Zico Kolter 我们提出有限多标签LML投影层作为端到端学习系统的新原始操作。 LML层提供了建模多标签预测的概率方法,该预测仅限于具有精确的k个标签。我们为该层导出了有效的前向和后向传递,并显示了如何使用该层来优化具有不完整标签信息的多标签任务的前k调用。我们评估顶级k CIFAR 100分类和场景图生成中的LML层。我们证明LML层增加了可忽略不计的计算开销,严格改善了模型的表示能力,并提高了准确性。我们还重新考虑截断的顶部k熵方法作为前k分类的竞争基线。 |
| Back to Simplicity: How to Train Accurate BNNs from Scratch? Authors Joseph Bethge, Haojin Yang, Marvin Bornstein, Christoph Meinel 二元神经网络BNN在降低计算和存储器成本方面显示出有希望的进展,但与大规模数据集(例如ImageNet)上的实值对应物相比,遭受了实质性的准确度降低。以前的工作主要集中在减少权重和激活的量化误差,从而提出了一系列近似方法和复杂的训练技巧。在这项工作中,我们提出了一些挑战传统智慧的观察。我们重新审视了一些常用的技术,例如缩放因子和自定义渐变,并表明这些方法对于训练表现良好的BNN并不重要。相反,我们根据所获得的见解为BNN提出了几个设计原则,并证明可以通过简单的培训策略从头开始训练高度准确的BNN。我们提出了一种新的BNN架构BinaryDenseNet,它可以在没有技巧的情况下显着超越ImageNet上现有的所有1位CNN。在我们的实验中,BinaryDenseNet相对于着名的XNOR网络和目前最先进的Bi Real Net,在ImageNet上的前1个精度方面分别实现了18.6和7.6的相对改进。 |
| A Segmentation-Oriented Inter-Class Transfer Method: Application to Retinal Vessel Segmentation Authors Chengzhi Shi, Jihong Liu, Dali Chen 视网膜血管分割作为眼科疾病或糖尿病患者的主要非侵入性诊断方法,由于需要像素标签而遭受数据稀缺。在本文中,我们提出了一种方便的基于补丁的两阶段转移方法。首先,基于信息瓶颈理论,我们为任务特定的特征空间插入一维降维层。接下来,进行半监督聚类以从不同来源数据库中选择具有特征空间中的相似性的实例。令人惊讶的是,我们凭经验证明来自不同类别的图像具有相似性,有助于比一些同类实例更好的性能。拟议的框架分别在DRIVE,STARE和HRF上实现了97,96.8和96.77的精度,优于当前的方法和独立的人类观察者DRIVE 96.37和STARE 93.39。 |
| Efficient two step optimization for large embedded deformation graph based SLAM Authors Jingwei Song, Fang Bai, Liang Zhao, Shoudong Huang, Rong Xiong 基于嵌入变形节点的公式已广泛应用于可变形几何和图形问题。虽然在基于立体声或RGBD传感器的SLAM应用中很有前景,但是当模型变大时,在变形节点参数估计中保持恒定速度仍然具有挑战性。在实践中,处理时间根据地图的扩展而快速增长。在本文中,我们提出了一种在大规模密集可变形SLAM中解耦变形图节点并使估计时间保持不变的方法。我们观察到图中只有部分可变形节点连接到可见点。基于这一事实,利用原始Hessian矩阵的稀疏性在两个独立的步骤中分割参数估计。利用这种新技术,我们实现了更快的参数估计,并且摊销的计算复杂度从O n 2减少到闭合O 1。结果,随着地图的不断增长,计算成本几乎没有增加。基于我们的策略,将大大减轻基于大规模嵌入变形图的应用中的计算瓶颈。通过实验验证有效性,具有大规模变形情景。 |
| Predicting Motion of Vulnerable Road Users using High-Definition Maps and Efficient ConvNets Authors Fang Chieh Chou, Tsung Han Lin, Henggang Cui, Vladan Radosavljevic, Thi Nguyen, Tzu Kuo Huang, Matthew Niedoba, Jeff Schneider, Nemanja Djuric 在检测和跟踪交通参与者之后,对其未来运动的预测是自驾车辆SDV技术的下一个关键组成部分,使SDV能够在其环境中安全有效地运行。这对于易受伤害的道路使用者VRU尤其重要,例如行人和骑自行车者。这些参与者需要特别小心处理,因为受伤的风险增加,以及他们的行为比机动演员的行为更难以预测。为了解决这个问题,在本文中,我们提出了一种用于预测VRU运动的基于深度学习的方法,其中我们将高清晰度地图和演员的环境光栅化为用作深度卷积网络的输入的鸟瞰图像。此外,我们提出了一种适用于实时推理的快速架构,并提供了各种光栅化选择的详细消融研究。结果有力地表明了在准确性和等待时间方面使用所提出的VRU运动预测方法的益处。 |
| Adversarial Regularization for Visual Question Answering: Strengths, Shortcomings, and Side Effects Authors Gabriel Grand, Yonatan Belinkov 视觉问题回答VQA模型已被证明过度依赖于VQA数据集中的语言偏差,盲目地回答问题而不考虑视觉上下文。对抗正则化AdvReg旨在通过一个对手子网络解决这个问题,鼓励主模型学习问题的无偏差表示。在这项工作中,我们研究了AdvReg的优点和缺点,目的是更好地理解它如何影响VQA模型中的推理。尽管在VQA CP上实现了新的技术水平,但我们发现AdvReg会产生几种不良副作用,包括不稳定的梯度和域示例中的性能急剧下降。我们证明在培训期间逐步引入正规化有助于缓解但不能完全解决这些问题。通过错误分析,我们观察到AdvReg改进了二元问题的泛化,但却损害了异构答案分布问题的性能。定性地,我们还发现正则化模型倾向于过度依赖视觉特征,而忽略了问题中的重要语言线索。我们的研究结果表明AdvReg需要进一步完善才能被认为是VQA的可行偏倚缓解技术。 |
| 2D Linear Time-Variant Controller for Human's Intention Detection for Reach-to-Grasp Trajectories in Novel Scenes Authors Claudio Zito, Tomasz Deregowski, Rustam Stolkin 为操纵任务设计机器人辅助设备具有挑战性。这项工作涉及提高半自动机器人的准确性和可用性,例如人工操纵机器人或外骨骼。关键的洞察力是开发一个系统,该系统考虑了上下文和用户意识,以便在如何帮助用户方面做出更好的决策。通过使系统能够自动生成一组候选抓取并达到在新颖,混乱的场景中掌握轨迹来实现情境感知。用户意识被实现为线性时变反馈控制器,以促进朝向最有希望的掌握的运动。我们的方法在一个简单的2D示例中进行了演示,其中要求参与者掌握杂乱场景中的特定对象。我们的方法还通过仅在x和y轴上提供控制来减少用户的可控尺寸的数量,同时由系统推断末端执行器的方向和其手指的姿势。实验结果表明了我们的方法在纯手动控制方面的准确性和执行时间方面的优势。 |
| **SwiftNet: Using Graph Propagation as Meta-knowledge to Search Highly Representative Neural Architectures Authors Hsin Pai Dave Cheng, Tunhou Zhang, Yukun Yang, Feng Yan, Shiyu Li, Harris Teague, Hai Helen Li, Yiran Chen 为边缘设备设计神经架构受到准确性,推断等待时间和计算成本的限制。传统上,研究人员手动制作深度神经网络以满足移动设备的需求。神经架构搜索NAS被提议用于自动化神经架构设计,而无需广泛的领域专业知识和重要的手动工作。最近的工作利用NAS来设计移动模型,其中考虑了硬件约束并且通过在乘法累加MAC中测量的较少参数和较少计算成本实现了现有技术精度。为了找到高度紧凑的神经架构,现有的工作依赖于预定义的单元并直接应用宽度乘数,这可能会限制模型的灵活性,减少有用的特征图信息,并导致精度下降。为了克服这个问题,我们提出GRAM GRAph传播作为元知识,采用细粒度节点智能搜索方法,并将更新中学到的知识积累到元图中。因此,GRAM可以实现更灵活的搜索空间并实现更高的搜索效率。在没有预定义单元或块的约束的情况下,我们提出了一种新的结构级修剪方法来去除神经架构中的冗余操作。 SwiftNet是GRAM发现的一组模型,其性能优于MobileNet V2,精度高2.15倍,速度提高2.42倍。与FBNet相比,SwiftNet将搜索成本降低了26倍,精度密度提高了2.35倍,加速度提高了1.47倍,同时保持了相似的精度。 SwiftNet可在ImageNet 1K上获得63.28的前1精度,仅有53M MAC和2.07M参数。 Google Pixel 1上相应的推理延迟仅为19.09 ms。 |
| ***Training on test data: Removing near duplicates in Fashion-MNIST Authors Christopher Geier MNIST和Fashion MNIST在机器学习领域非常受欢迎。时尚MNIST通过引入更难的问题,增加测试集的多样性以及更准确地代表现代计算机视觉任务来改进MNIST。为了提高FashionMNIST的数据质量,本文研究了训练集和测试集之间的近似重复图像。测试和训练集之间几乎重复,人为地提高了机器学习模型的测试精度。本文在Fashion MNIST中识别出近似重复的图像,并提出了一个删除了近似重复的数据集。 |
| Chinese Abs From Machine Translation |
Papers from arxiv.org
更多精彩请移步主页

pic from pexels.com