深度学习赋能视频编码

深度学习赋予了诸如计算机视觉等领域新的研究契机,其应用也获得了视频编码领域的诸多关注。在LiveVideoStack线上分享中北京大学信息技术学院 助理研究员王苫社详细介绍了当下深度学习在视频编码中的应用,以及其在视频编码标准中的前景。
文 / 王苫社
整理 / LiveVideoStack
直播回放
https://www2.tutormeetplus.com/v2/render/playback?mode=playback&token=edc99c13b9a24a2093486239dbac8785
大家好,我是来自北京大学的王苫社,本次带来的分享主要是从神经网络视频编码历史和基于深度学习的视频编码进展两方面来与大家探讨关于深度学习与视频编码中的一些问题。
1. 神经网络视频编码历史
1.1 起源
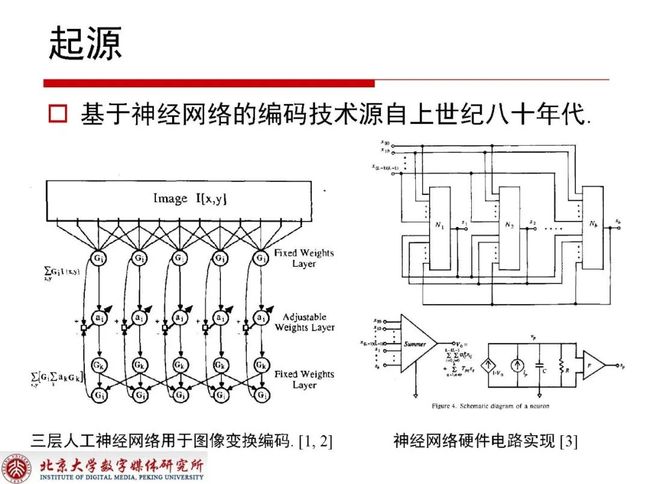
基于神经网络来做视频编码相关的内容最早可以追溯到上世纪八十年代,那时已经有人将三层人工神经网络用于图像变换编码,甚至有人在尝试神经网络硬件电路的实现。
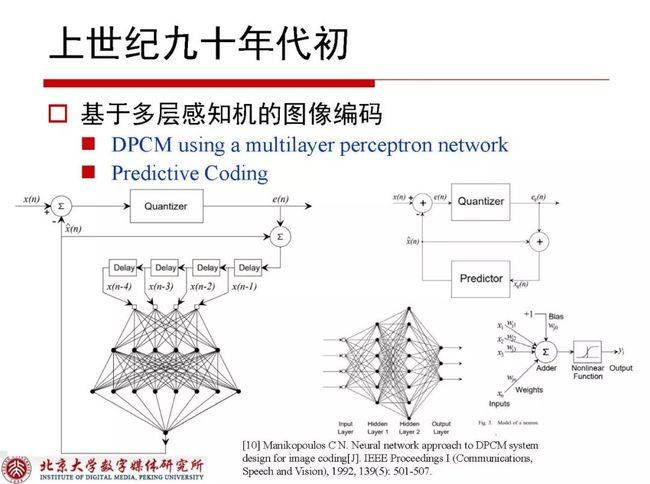
到上世纪九十年代初,学界已经出现了基于多层感知机的图像编码,他们使用多层感知机的结构来做DPCM编码,这也是预测技术使用网络结构的第一篇Paper。
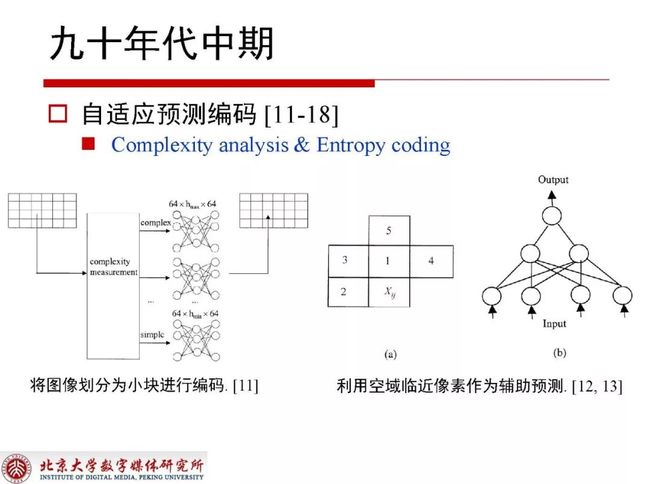
到九十年代中期的时候已经有了自适应预测编码,当时主要采用的是将图像划分为小块进行编码,同时也出现了利用空域临近像素作为辅助预测的方式。
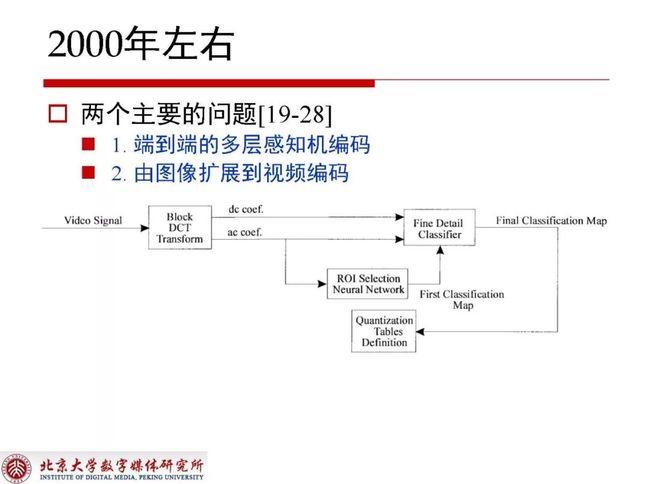
到2000年左右关于编码出现了端到端的多层感知机编码和有图像扩展到视频编码两个主要问题。
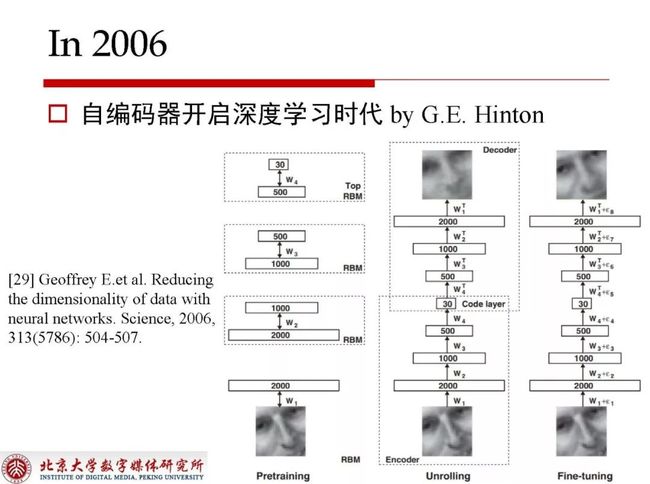
自编码器在2006年开启了深度学习时代。
2. 基于深度学习的视频编码进展

接下来我将从预测增强、环路滤波和深度学习与视频编码标准三个方面来为大家介绍基于深度学习的视频编码到目前为止的进展。
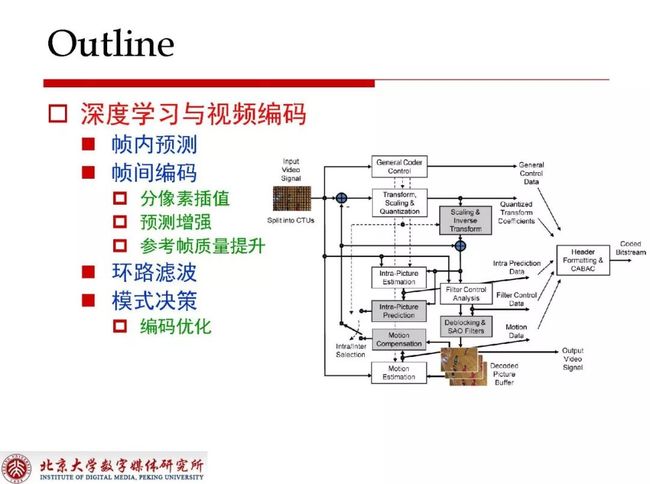
首先为大家描述一下深度学习在视频编码框架中都应用到了哪些环节。早期在VVC的前身JEM中就已经有人提出了帧内预测的方案,帧间编码里需要重点关注分像素的插值、预测增强和参考帧质量提升三个方面,环路滤波无论在哪一代标准里使用基于深度学习的方式都能提升预测性能,模式决策在编码优化中能够通过牺牲一定性能来获得很好的编码加速,基于神经网络的部分也有人提出由神经网络直接决策RDO中的一系列划分和模式选择的问题。
2.1 帧内预测
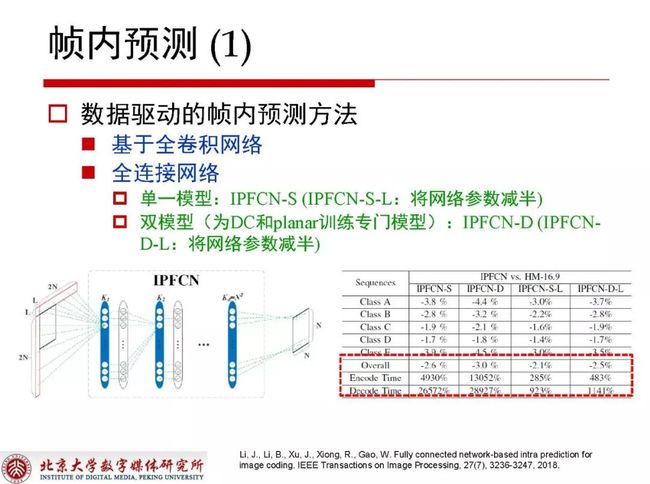
帧内预测基本可以总结为是一种数据驱动的帧内预测方法,工作中是使用对应块周围的左侧一列和上面一行,甚至可能使用周围左侧两列或者上面两行来对当前所对应的块进行预测,这其中的工作是基于网络复杂度较高的全卷积网络,分为低复杂度和全复杂度两种情况。低复杂度是将网络参数减半,从数据中分析可以得出网络参数减半对性能没有明显地下降,复杂度却降低了很多,一般情况下可以认为性能提升的空间和复杂度的降低之间能够寻找到非常好的treat off。对于帧内预测而言,DC和planar在双模型的结构里是比较特殊的模式,所以要为DC和planar训练专门的模型,其余的帧内预测在使用相同的网络结构后可以使性能得到进一步的提升。从数据当中可以知道,无论怎样使用数据网络和降低参数量,网络复杂度依旧不能达到预期。
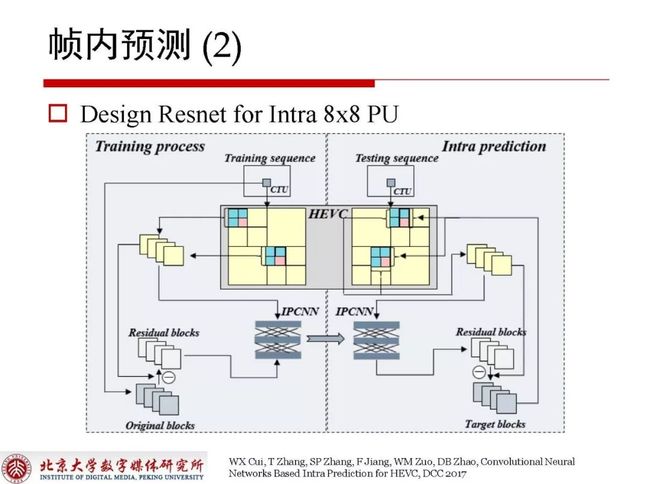
关于帧内预测还可以对Intra 8x8 PU 做进一步的残差去除。
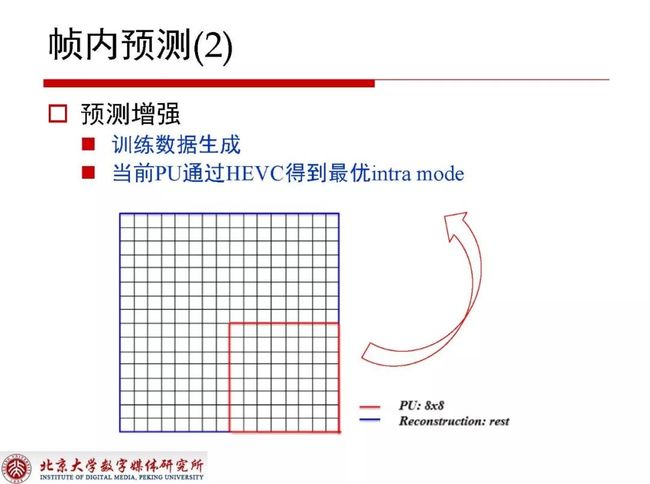
如上图所示,右下角如果是一个8x8 PU,在获取到HEVC最右的Intra mode之后,再使用它周围的残差空间相关性进一步对产生的残差进行学习,残差结合已经获取到的重建值最终得到输出结果。
2.2 基于深度学习的分像素插值

基于深度学习的分像素插值分为针对1/2和1/4像素设计神经网络两个工作。上图左侧是只针对1/2像素设计神经网络,右侧是结合图像的超分辨率技术把1/4像素涉及神经网络也考虑在内。传统技术在视频编码获得3%的增益十分困难,但基于深度学习的插值方式可以做到这一点。
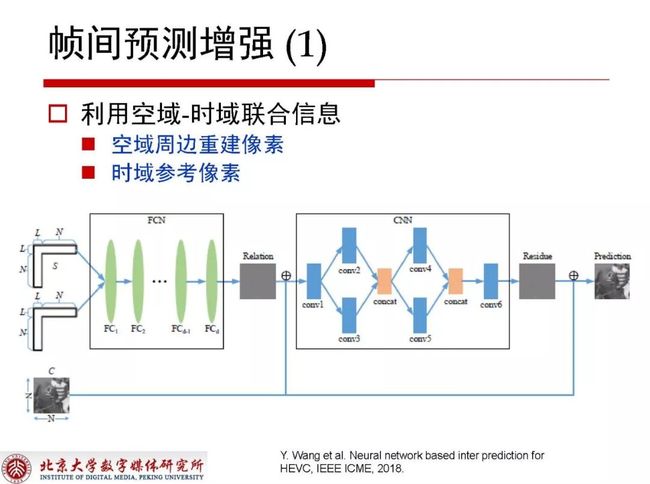
帧间预测增强的技术需要利用空域和时域的联合信息去构建网络结构,通过周围重建像素和时域参考像素结合输入,输出是对当前帧间提升的预测。时域参考往往在应用中有一些方式技巧,比如对当前块在参考帧上做粗略的运动估计,对应块和当前块相关性更强,更有利于帧间预测的工作。
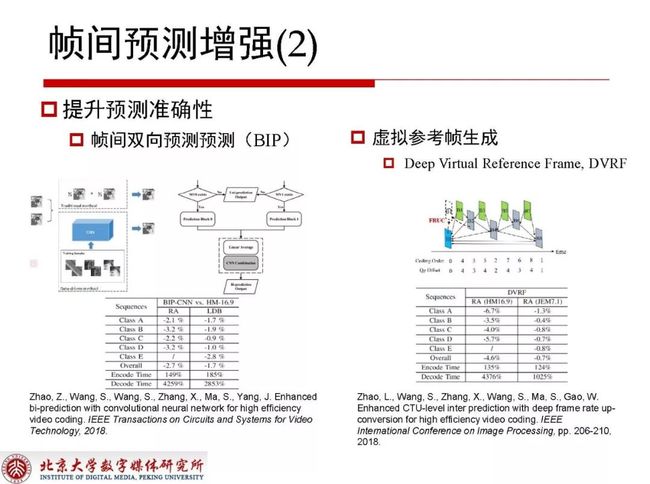
在帧间预测提升预测准确性方面还有两个工作分别是帧间双向预测(BIP)和虚拟参考帧生成,双向预测对于B帧编码块来说有前向和后向预测,双向预测在average之后就可以拿到块对应的预测值。对于双向预测部分,我们基于前后向预测的权重分配设计了一个网络结构,利用前向后向生成当前所预测块的预测值,性能提升接近3%,在LDB情况下最高也可以获得1.7%的增益,虽然对性能的提升效果非常明显,但同时也提高了编解码的复杂度。对于RA结构下,最高层帧的前向参考集合和后向参考集合会出现重复的参考帧,采用预定的方式拿掉之后使用前向和后向的参考帧生成虚拟参考帧,使当前参考帧的前向参考集合和后向参考集合都是完全不同的帧,对性能的提升也非常可观。但在运动剧烈的情况下会导致性能下降,在此方法基础上进行改进之后可以不直接替换参考帧,而是将虚拟参考帧直接放到尾端,同时编码新的Reference index,这样做也可以在性能上获得比较明显的增益,最终在HEVC上性能增益达到4.6%,而JEM7.1上性能增益不到1%,这是由于JEM本身对于帧间预测的提升技术做了很多工作,预测准确性有很大的提高。
2.3 环路滤波
2.3.1 基于整帧的处理
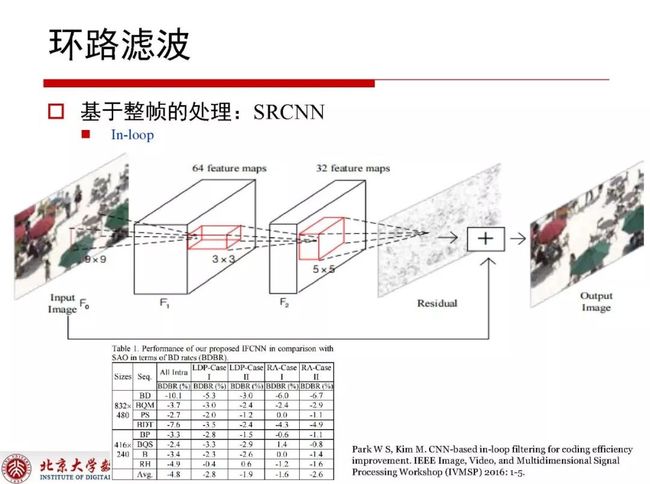
环路滤波基于整帧的处理是整帧拿到网络结构里进行滤波之后再使用网络结构进行一遍滤波,这时会收到很明显的增益,对于网络结构的设计也要有一定技巧。整帧本身帧内内容相关性很强,不同内容会在滤波方式选择上存在差异。
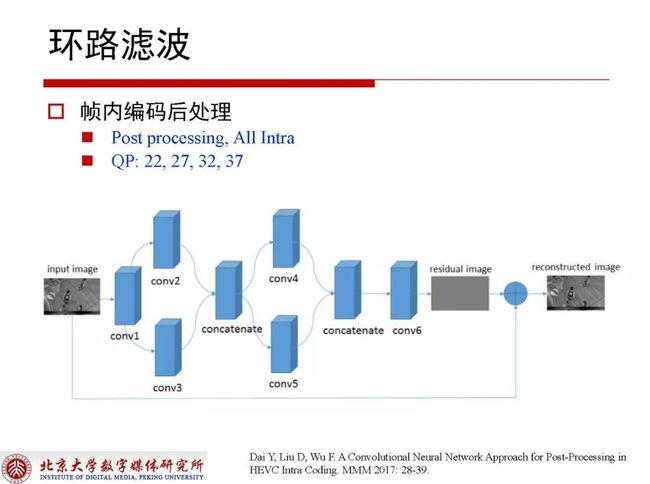
帧内编码不会用于后续的参考,所以用网络结构可以提升当前帧所对应的质量。在不同QP下需要训练不同的网络结构,完成所有编码之后可以得到残差,再使用滤波处理对残差进一步降低。
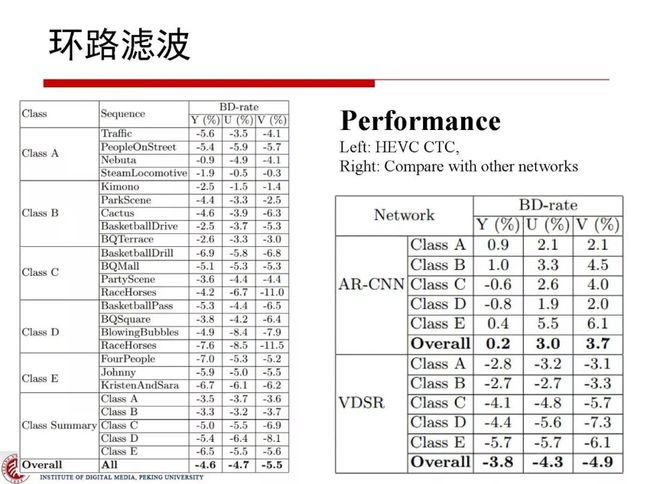
2.3.2 基于内容特性的神经网络环路滤波
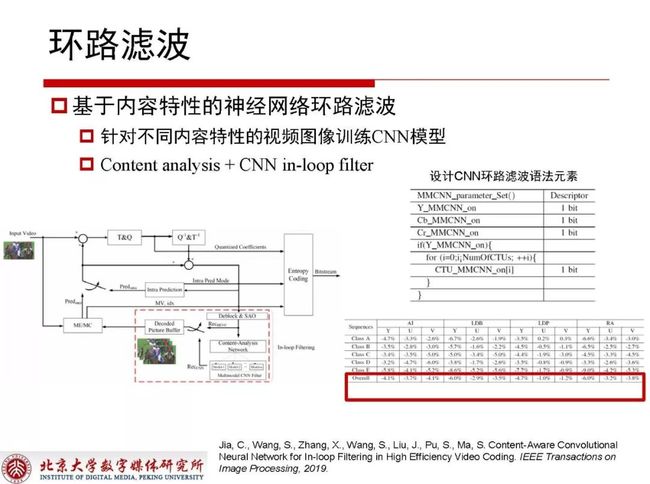
整帧是比较大的粒度,在实验中不得不考虑到其对应的内容差异性,针对不同内容特性的视频图像训练CNN模型,在考虑到内容的自适应特性情况下,我们将CTU分为不同的内容类别,不同的类别使用不同的CNN模型,这样做在RA情况下可以获得6%的增益。网络结构设计考虑到受到复杂度约束,层数限制在9-10层,有人在此基础做了些拓展,层数增加到十几层甚至三十几层,最终会收获接近10%的增益甚至更高。
2.3.3 智能编码与VVC(JVET-N0110)
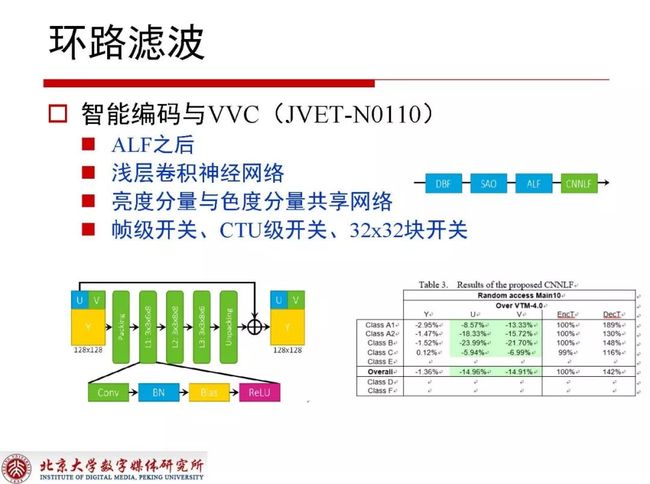
JVET-N0110这个提案在ALF之后放了一个浅层的神经网络,为了降低复杂度使亮度分量与色度分量共享网络,又为了进一步提升性能且考虑到比较小的内容自适应特性,在帧级、CTU和32x32块上都放了开关。对于编码端来讲它的复杂度没有发生改变,这是因为在测试中经常会遇到CPU太差但GPU很好的情况,这时运行VVC的参考软件GPU的速度相比CPU就显得不是很慢了。1.36%的性能增益在解码端只有47%的复杂度增加,大体还是在允许范围内的。
2.3.4 智能编码与VVC(JVET-N0133)
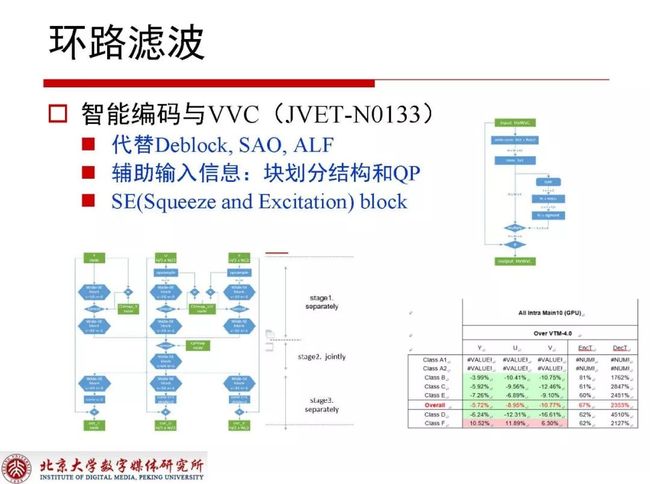
JVET-N0133这个提案里也提到了网络结构,但它是将所有滤波包括Deblock、SAO、ALF全部替换,在设计之中充分考虑到了块划分结构和QP。
2.3.5 智能编码与VVC(JVET-N0169)
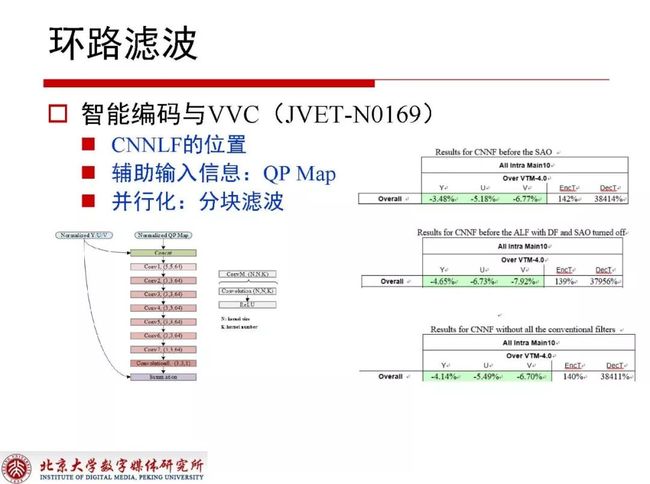
JVET-N0169提案表示不同位置下神经网络获取的性能的差异还是存在的,QP和块划分结构必须作为很重要的辅助信息输入,本提案为了进一步提速而分块进行滤波,这样就可以充分利用GPU上的并行资源提升并行化程度。
2.3.6 智能编码与VVC(JVET-N0254)
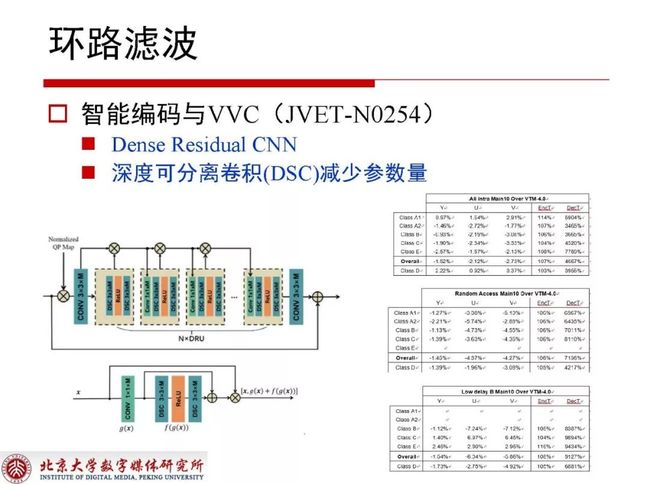
在JVET-N0254网络结构里提出了一种深度可分离卷积,它可以有效减少网络结构的参数量,降低网络复杂度的提升,编码端编码复杂度没有太多改变,但解码复杂度提升幅度很大。
2.3.7 智能编码与AVS3
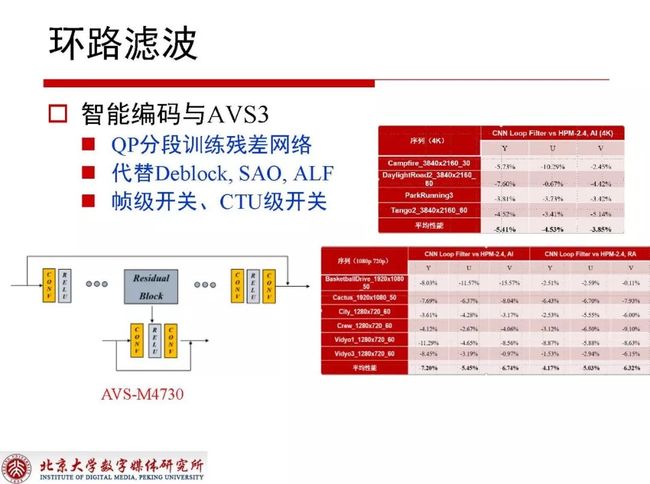
在国内的AVS3标准中对于深度学习与视频编码的探索也有很多提案,其中代表性的提案内容是对QP进行分段,一段QP使用一个网络结构。同样在替换所有滤波之后发现深度学习的方式依然可以带来非常可观的性能增益。
3. 帧内编码模式决策
3.1 基于CNN的CU模式决策


基于CNN的CU模式决策是一个相当系统性的工作,首先它需要实现FastCUMode,并且应用在HEVC Intra硬件编码器的实现里。
3.2 HEVC Intra硬件编码器实现
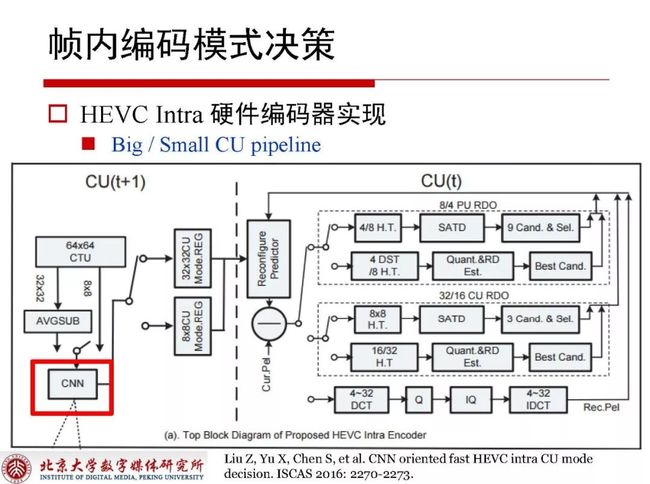
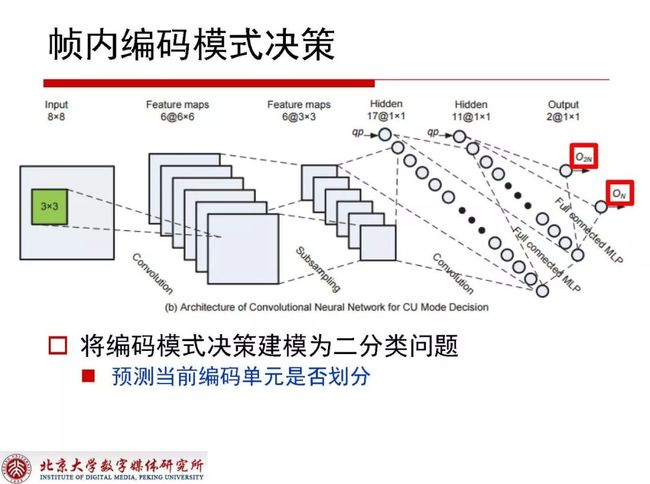
HEVC Intra硬件编码器的实现使用类似LeNet结构,QP在其中作为必要考虑因素。关于模式决策是将编码模式决策建模为二分类问题,预测当前编码单元是否划分直接当做分类问题对待。
3.3 VLSI设计CNN加速模块
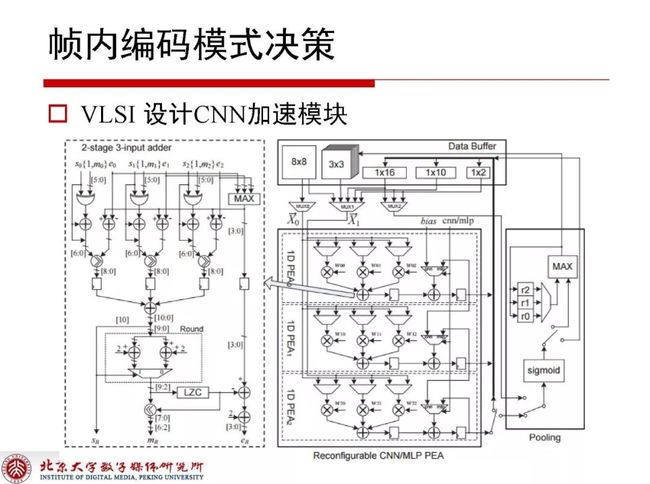
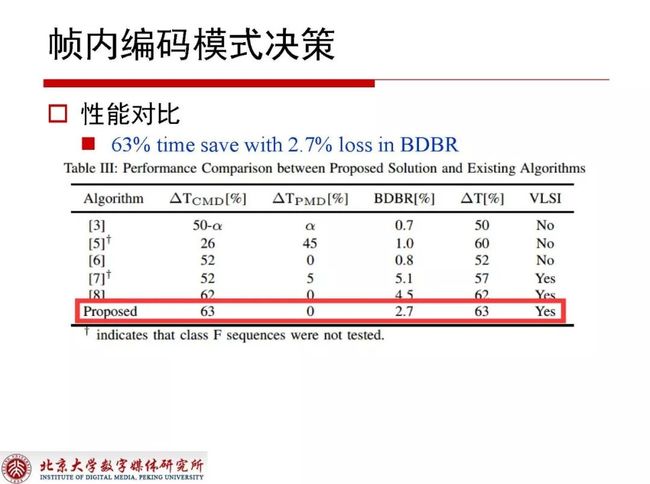
通过硬件设计的加速模块可以看到63%的时间节省,同时降低2.7%的编码性能,相对传统技术来讲性价比不是特别高,但考虑到这种方法已经在硬件化世界做了一些实现,综合各方面还是比较好的选择。
4. 帧内编码模式决策
4.1 CTU级处理
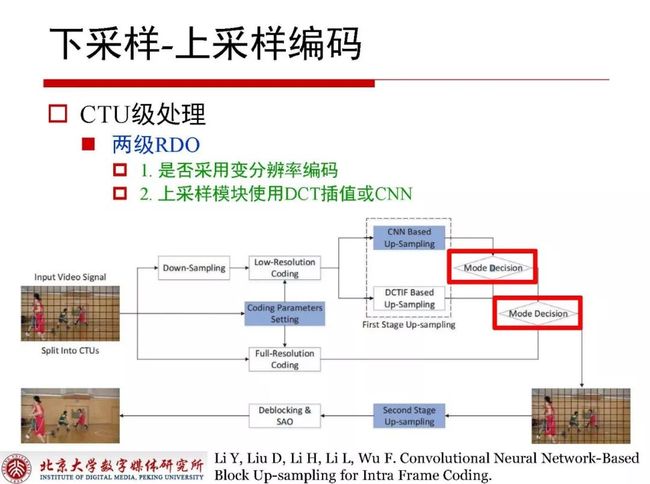
对于视频编码而言,有时直接采用下采样编码然后对于重构部分直接上采样返回的质量也很可观,CTU级处理思路是指采用全分辨率编码,上采样模块使用DCT插值或CNN,首先用RDO决策上采样方式,之后再做一次RDO来决定是否采用下采样方式。
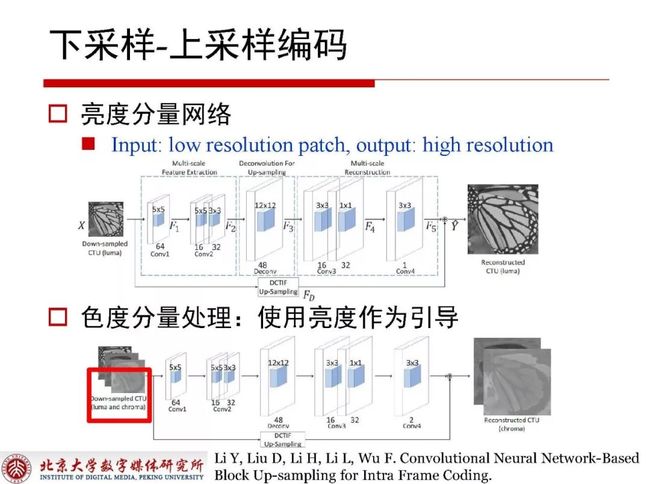
下采样-上采样编码中有很多技巧性的设计,比如亮度分量网络和色度分量处理,其中色度分量网络处理是使用亮度作为引导,这一切都是为了提升编码效率。
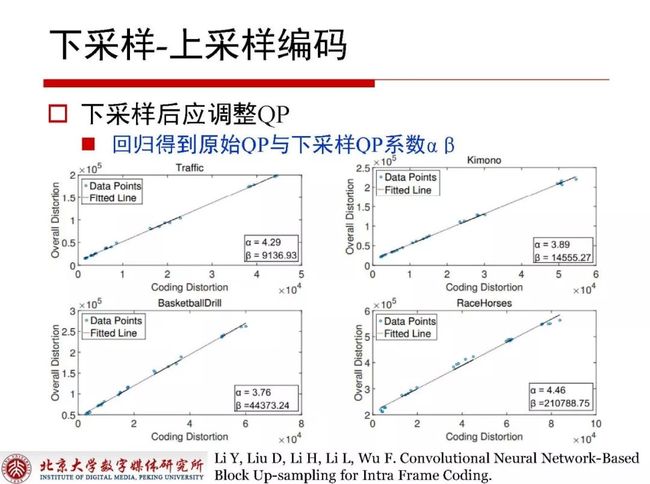
对当前块做了下采样之后对应QP便不再适用,此时需要对QP进行调整,通过拟合的方式可以得到原始QP与下采样QP之间存在着线性关系,这种线性关系可以保证在下采样之后的编码效率。
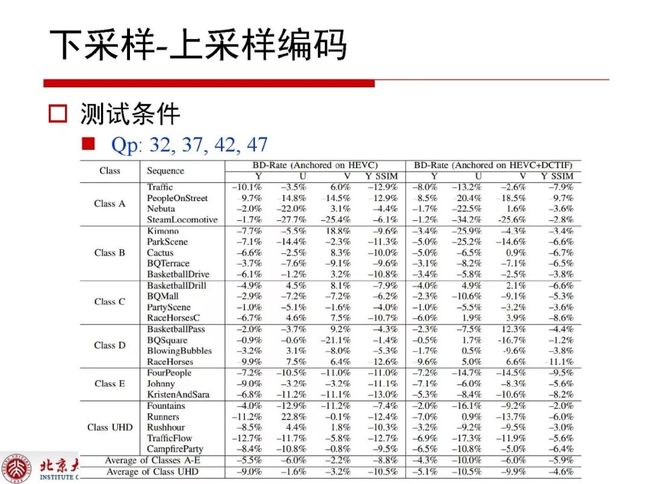
上图所述,不同QP情况下所对应的编码效率提升非常明显,其中特别给出的UHD超高清分辨率下的性能增益是9%,对于大分辨序列来讲,先下采样之后再上采样返回,对码率的节省至少在某些区域上看来是非常明显的,这点也可以在classes A和E上的到证实。

在算法命中率方面,相当大比例的区域都和传统方式差不多,与深度学习的方式吻合。

从个人的角度,就目前看来,借助深度学习将视频编码的性能提升10%,甚至更多还是非常有可能的,但于此同时整体的复杂度也必然是需要重点关注与研究的问题。目前,基于深度学习的端到端的视频编码也已经有了一些新的成果。而对于为什么深度学习能够带来明显的视频编码性能提升?这个问题迄今为止尚未有人能够提供细致、清楚的理论依据。虽然深度学习为视频编码性能的提升提供了许多的思路,但距离其在视频编码标准当中的应用,仍需要很长的一段时间来进行探索。

更多精彩内容:人物专访(行业趋势解读)、LiveVideoStackCon 大会演讲内容回顾及线上分享内容回顾(+线上分享PPT资料下载),=>>点击【阅读原文】!