verilog实现简单的三级加法流水线
引言
pipeline流水线设计是一种典型的面积换性能的设计。一方面通过对长功能路径的合理划分,在同一时间内同时并行多个该功能请求,大大提高了某个功能的吞吐率;另一方面由于长功能路径被切割成短路径,可以达到更高的工作频率,如果不需要提高工作频率,多出来的提频空间可以用于降压降功耗,进可攻退可守。今天这篇文章将小小总结一下流水线设计的一些关键点。
流水线设计是完美的时间并行。因为流水线上每一级的处理都是一个时钟周期的延时,并且一动则全动,每一级的延时可以完美的掩盖起来,最高实现与流水级数相同数量的请求并行度。
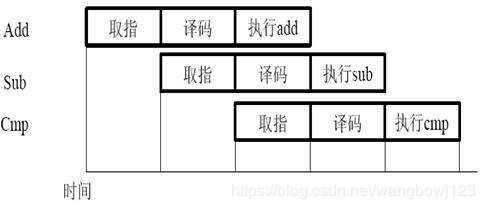
如上图所示,在现代经典的cpu处理中,流水线级数被广泛应用,cpu的各个处理环节可以看作流水线上的一个stage。在单发射单处理单元的最简单处理器中,同一时间内最高同时可以支持5条指令的执行。如果没有指令冲突,资源冲突等可能导致断流的场景,基本可以认为每一个时钟周期都可以完成一条指令的处理。
当然,除了CPU,只要是一个周期无法完成的功能,在性能优先的设计中,为了提高吞吐率,都可以采用流水线技术来对功能路径进行切分,比如乘法器等。
流水线的stage划分
我们知道,流水线的分割线是一组寄存器,这条分割线放在哪个位置完全由设计者决定。一般来说,划分流水线的时候主要有以下三点考虑:
-
如果流水线切割的子功能抽象层次较高,最好按完整的功能来进行流水线划分,比如CPU的各个执行环节。
-
流水线最好划分在数据通路上位宽较小的地方,以节省寄存器数量和面积。在流水线上可以有许多的数据路径,数据路径会有中间结果和最终结果。那么这个时候就可以选择性地进行切割。比如一个1024bit 2选1的数据选择器,如果将流水线划分划在选择器的输入端,那么将占用2x1024=2048bit的寄存器以及1个1bit的选择信号。而如果将流水线划分在选择器的输出端,那么只需要1024bit的寄存器,显然面积的收益十分巨大。
-
流水线每一级的关键路径延时最好接近,这样利于获得最大的timing margin,频率可以跑到最高。这点很好理解,假设一条关键路径在切割流水线之前延时为a,时钟周期近似为a,将其切割成2级流水线。假设切割之后的新关键路径仍然在该关键路径上,那么新的时钟周期将取决于切割后的关键路径延时。很明显,a/2是最小的,如果不是均分,那么总有一级大于a/2,那么时钟周期将大于a/2。当然,也有可能切割流水线之前的关键路径被切割之后不再是关键路径。假设一条非关键路径b,在切割之后变成1/3b和2/3b。并且2/3b >1/2a,那么2/3b将会成为新的关键路径,新的时钟周期将接近2/3b。这种情况下,如果对于路径b的这种切割不是必要的(比如出于功能完整性和面积考虑),那么完全可以将b切成1/2b和1/2b,1/2b<1/2a<2/3b,时钟频率依然可以以1/2a为准。
流水线设计的简单例子
那么怎么设计一个流水线呢?其实从结构上来讲,流水线很简单,无非是一个原本完整的功能,中间插了几级寄存器,每级寄存器的输出做不一样的功能,每一拍都进行一次更新,把上一级的结果打到下一级。比如一个最简单的例子,假设一个周期只能完成一个1bit加法,那么要实现3个操作数加法s=a+b+c,并且保证每个周期都有一个结果寄存器输出,可以使用3级流水实现:
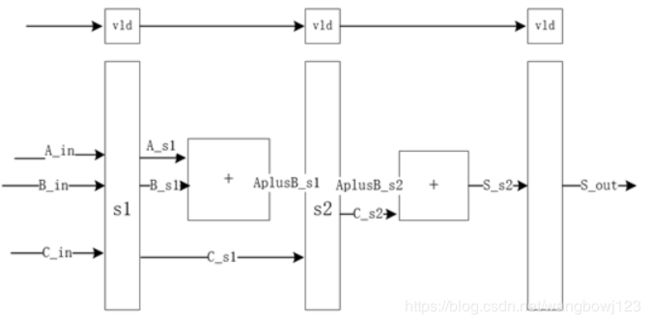
实现代码如下:
`timescale 1ns / 1ps
//==================================================================================================
// Filename : pipeline.v
// Created On : 2020-07-08 18:34:17
// Last Modified : 2020-07-08 19:05:15
// Revision : 1.6
//
// Description :
//
//
//==================================================================================================
module PIPELINE_ADDER#(
parameter DATA_WIDTH = 16
)
(
input clk,
input rst_n,
input [DATA_WIDTH-1:0] a_in ,
input [DATA_WIDTH-1:0] b_in,
input [DATA_WIDTH-1:0] c_in ,
input vld_in,
output reg [DATA_WIDTH-1:0] s_out ,
output reg vld_out
);
// 这里没有必要都定义成reg类型
wire [DATA_WIDTH-1:0] plus_s1 ;
reg [DATA_WIDTH-1:0] plus_s2 ;
wire [DATA_WIDTH-1:0] plus_out ;
// stage 1
reg [DATA_WIDTH-1:0] a_reg ;
reg [DATA_WIDTH-1:0] b_reg ;
reg [DATA_WIDTH-1:0] c_reg ;
// stage 2
reg [DATA_WIDTH-1:0] c_reg_s2 ;
reg vld_s1, vld_s2;
// control path
always @(posedge clk or posedge rst_n) begin
if (!rst_n) begin
// reset
vld_s1 <= 1'b0;
vld_s2 <= 1'b0;
vld_out <= 1'b0;
end
else if (rst_n) begin
vld_s1 <= vld_in;
vld_s2 <= vld_s1;
vld_out <= vld_s2;
end
end
// input data -> stage1
always @(posedge clk or posedge rst_n) begin
if (rst_n) begin
if (vld_in) begin
// vld_in is true
a_reg <= a_in;
b_reg <= b_in;
c_reg <= c_in;
end
end
else begin
a_reg <= 16'd0;
b_reg <= 16'd0;
c_reg <= 16'd0;
end
end
// stage1 -> stage2
assign plus_s1 = a_reg + b_reg;
always @(posedge clk or posedge rst_n) begin
if (rst_n) begin
if (vld_s1) begin
plus_s2 <= plus_s1;
c_reg_s2 <= c_reg;
end
end
else begin
plus_s2 <= 16'd0;
c_reg_s2 <= 16'd0;
end
end
// stage2 -> out
assign plus_out = plus_s2 + c_reg_s2;
always @(posedge clk or posedge rst_n) begin
if (rst_n) begin
if (vld_s2) begin
s_out <= plus_out;
end
end
else
s_out <= 16'd0;
end
endmodule
上面这个例子可以保证如果每一拍都有新的a_in, b_in, c_in输入,那么在经过了2拍的延时后每一拍都可以输出一个s_out。
仿真文件编写如下:
`timescale 1ns / 1ps
//==================================================================================================
// Filename : pipeline.v
// Created On : 2020-07-08 18:34:17
// Last Modified : 2020-07-08 19:05:15
// Revision : 1.6
//
// Description : test batch
//
//
//==================================================================================================
module tb;
parameter DATA_WIDTH = 16;
reg clk;
reg rst_n;
reg vld_in;
reg [DATA_WIDTH-1:0] a_in;
reg [DATA_WIDTH-1:0] b_in;
reg [DATA_WIDTH-1:0] c_in;
wire vld_out;
wire [DATA_WIDTH-1:0] s_out;
always
begin
clk = 0;
#10;
clk = 1;
#10;
end
initial
begin
rst_n = 0;
vld_in = 0;
#20;
rst_n = 1;
vld_in = 1;
a_in = 16'd3;
b_in = 16'd5;
c_in = 16'd8;
#10;
a_in = 16'd6;
end
PIPELINE_ADDER pipeline(
.clk(clk),
.rst_n(rst_n),
.a_in(a_in),
.b_in(b_in),
.c_in(c_in),
.vld_in(vld_in),
.s_out(s_out),
.vld_out(vld_out)
);
endmodule
但是实际场景中流水线的最终结果输出并不一定是每一拍都需要的。假设s_out的下游有反压信号,如果流水线还是每拍都流水,那么s_out的结果将会每拍都刷新一次,在下游存在反压的情况下会有有效数据被流水冲刷掉,那么将会导致结果的错误。因此对于这种下游有反压的场景,不能简单地每拍都进行一次流水。而要考虑进下游的反压。
在上面的例子中,假设下游的反压信号是rdy_in,因为流水线反压一级则前级均被反压,因此每一级都需要一个反压信号,而流水线最后一级的反压信号将参与到前面每一级流水的反压信号生成中。代码中控制逻辑增加反压:
// control path
wire rdy_s1, rdy_s2, rdy_in;
wire ena_s1, ena_s2, ena_out;
wire handshake_s1, handshake_s2, handshake_out;
// input data -> stage1
assign rdy_s1 = ena_s2;
assign handshake_s1 = rdy_s1 & vld_s1;
assign ena_s1 = handshake_s1 | ~vld_s1;
always @(posedge clk or posedge rst_n) begin
if (!rst_n) begin
// reset
vld_s1 <= 1'b0;
end
else if (ena_s1) begin
vld_s1 <= vld_in;
end
end
// stage 1 -> stage 2
assign rdy_s2 = ena_out;
assign handshake_s2 = rdy_s2 & vld_s2;
assign ena_s2 = handshake_s2 | ~vld_s2;
always @(posedge clk or posedge rst_n) begin
if (!rst_n) begin
// reset
vld_s2 <= 1'b0;
end
else if (ena_s2) begin
vld_s2 <= vld_s1;
end
end
// stage 2 -> out
assign handshake_out = rdy_in & vld_out;
assign ena_out = handshake_out | ~vld_out;
always @(posedge clk or posedge rst_n) begin
if (rst_n) begin
// reset
vld_out <= 1'b0;
end
else if (ena_out) begin
vld_out <= vld_s2;
end
end
流水线的逐级反压串扰
从上面的例子可以看到,最后一级的流水输出vld_out需要与下游的反压信号rdy_in完成握手之后,上一级s2才可以更新到out。只有s2更新到out,s1才能更新到s2。只有s1更新到s2,in才能更新到s1,这样一来,我们注意到ena_s1,也就是第一级流水的更新使能信号,其实可以拆解到rdy_in这个最后一级的反压信号。由此可见rdy_in串扰到了最前面一级,形成了逐级反压串扰。这只是一种最简单的场景,如果rdy_in信号的生成逻辑较复杂,并且流水线级数较多,每一级的rdy信号除了下一级的握手成功,还有别的条件,比如资源冲突,数据冲突等,那么这条从最后一级反压信号开始的组合逻辑路径将会很长,成为流水线中的关键路径,必要时需要一些特殊的手段进行处理。
解决这个问题的办法就是切割这种逐级握手机制。有以下2种做法,这里就不一一展开:
-
使用乒乓buffer。
-
使用旁路缓存。这种方法比较常见。即在流水线的某一级加入一个buffer,该级的rdy信号直接使用buffer的非满信号,这样就能切割该级与后面流水线的握手联系,通过buffer非满信号来决定是否可以流水到这一级。当流水流到这一级之后,再根据下游是否握手成功决定是要写入旁路缓存还是直接bypass缓存。
除了来自最后一级流水的逐级反压,每一级流水都有可能单独被反压的可能。这取决于具体的设计。比如经典流水线CPU设计中的RAW, WAW问题,运算单元资源冲突问题,总线带宽资源限制问题等等。而无论是哪一级被反压,都要逐级反压前面的流水