MySQL索引使用策略和优化
在前面的文章里,我们介绍了MySQL索引的原理。那么在实际开发中,应该如何去使用索引以及如何去优化呢?
什么时候不应该使用索引?
索引并不都是有效的。有些场合,可能我们并不需要使用索引,甚至使用了索引反而会影响性能。
- 查询很少用到的列
如果某些列在查询时很少用到,那加不加索引的速度其实是差不多的。而增加索引会增加系统维护索引的开销,所以不值得创建索引。
- 表的数据量很少
如果在测试数据库里只有几百条数据记录,它们往往在执行完第一条查询命令之后就被全部加载到内存里,这将使后续的查询命令都执行得非常快,不管有没有使用索引。只有当数据库里的记录超过了1000条、数据总量也超过了MySQL服务器上的内存总量时,数据库的性能测试结果才有意义。
- 列的取值范围太小
列的取值范围太小,比如“性别”列。本来查询的结果集合占表中的数据行很大的比例,相当于全表查询了,所以没有必要建立索引。
- 有大量重复的列
这个其实跟上述条件类似。如果有某列在很多行数据里都有重复值,那不管是不是用索引,查询出来的结果集合都会占全表中的数据行很大的比例,所以也不需要建立索引。
- 读少写多的场景
由于索引会降低写的性能,增加读的性能。所以并不适合读少写多的场景。创建和维护索引是需要消耗系统资源的,所以不适合使用索引。
什么时候应该使用索引?
- 主键
主键会自动建立“主键”索引,它也是一个唯一索引。
- 作为查询和排序条件的列
经常作为查询条件在WHERE或者ORDER BY语句中出现的列要建立索引。同理,作为排序的列也应该建立索引。从前面的文章中我们知道,基于BTree及其变种的引擎在排序时,使用基于索引的排序会大大提升性能。
- 外键
与其它表的关联字段,往往会经常在查询中用到,所以也建议使用索引。
- 聚合函数用到的列
用于聚合函数的列可以建立索引,例如使用了max(column_1)或者count(column_1)时的column_1列就需要建立索引。
什么时候索引会失效?
建立索引后,如果不注意索引的原理,有时候查询可能会不能使用索引。下面列出一些常见的索引失效的场景。
- 组合索引中的NULL
在组合索引(即多列索引)中不能有列的值为NULL,如果有,那么这一列对组合索引就是无效的。
- 一个查询只使用一次
在一个SELECT语句中,一个索引只能使用一次。比如如果在WHERE中使用了,那么在ORDER BY中就不会再使用了。
- LIKE操作
LIKE操作中,’%xxx%'不会使用索引,也就是索引会失效,但是’xxx%'可以使用索引。
- OR连接多个条件
在查询条件中使用OR连接多个条件会导致索引失效,除非OR连接的每个条件都加上索引,这时应该改为多次查询,然后用UNION ALL连接起来。
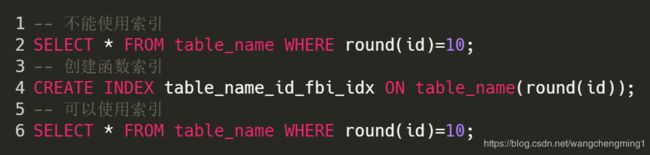
- 使用表达式或者函数
使用MySQL内部函数导致索引失效,对于这样情况应当创建基于函数的索引。比如:
- 结果集太大
如果MySQL估计使用全表扫描要比使用索引快,则不使用索引。MySQL会使用一个叫基于数据访问路径的CBO成本计算模型来估计它。
- 多个范围查询
对于范围条件查询,MySQL无法再使用范围列后面的其它索引列了。但是对于“多个等值条件查询”则没有这个限制。这里有一个小技巧,如果范围不大,可以使用IN来代替。如下代码:
索引的优化
- 最左前缀
索引的最左前缀和和B+Tree中的“最左前缀原理”有关,举例来说,如果设置了组合索引col1,col2,col3那么以下3中情况可以使用索引:col1,col1,col2,col1,col2,col3,其他情况都是不能使用索引的。
根据最左前缀原则,我们一般把排序分组频率最高的列放在最左边,以此类推。
- 模糊查询优化
在上面已经提到,使用LIKE进行模糊查询的时候,’%aaa%'不会使用索引,也就是索引会失效。如果是这种情况,只能使用全文索引来进行优化。之前的文章也提到了,目前版本的MySQL InnoDB引擎已经支持全文索引,但不支持中文,可以通过使用ngram插件开始支持中文。
使用全文索引后,相应的查询语句也需要修改,不再是WHERE了,而是全文索引查询的关键字MATCH和ANGAINST。
- 使用短索引
对字符串列进行索引,如果可能应该指定一个前缀长度。例如,如果有一个CHAR(255)的列,如果在前10个或20 个字符内,多数值是唯一的,那么就不要对整个列进行索引。短索引不仅可以提高查询速度而且可以节省磁盘空间和I/O操作。
参考书籍
《高性能MySQL》