注:终于写到最激动人心的部分了。假设检验应该是统计学中应用最广泛的数据分析方法,其中像"P值"、"t检验"、"F检验"这些如雷贯耳的名词都来自假设检验这一部分。我自己刚开进入生物信息学领域,用的最多的就是"利用t检验来判断某个基因在实验组和对照组中表达量的差异是否显著"。此外,对"P值"真正含义的探究也开启了自学概率论与数理统计之路。因此无论是应用价值,还是对我学习统计学的影响,这部分的内容都是意义非凡的。
下面是两篇相关的文章,分别写于2011年和2016年,仅供参考:
- 生物学中P值的意义,2011
- 显著性检验——费舍尔与“女士品茶”,2016
1. 假设检验
从样本到总体的推理被称为统计推断。应用统计学家费舍尔认为常用的统计推断有三种基本形式:抽样分布、参数估计和假设检验。
对于假设检验,从字面意思来看,"假设"这个词在这里就是一个其正确与否有待通过样本去判断的陈述。假设是对一个或多个总体的概率分布或参数的假设;在做判断时掌握的信息是从总体中抽取的样本。在数理统计中,通用"检验"一词来代替上文汇总的"判断"。因此假设检验就是根据样本的信息检验对相关总体的某个假设是否正确。
假设检验的类型
根据总体分布是否已知以及检验的内容,可以将假设检验分为以下两类:
- 参数假设检验:总体分布已知,检验关于未知参数的某个假设(主要包括对总体均值及方差、均值差、方差比等参数的检验);
- 非参数假设检验:总体参数未知时的假设检验问题(主要包括分布拟合检验、符号检验、秩和检验等).
基本理论依据
假设检验的基本理论依据:实际推断原理,即“小概率原理”.
2. 一般步骤(临界值法)
根据样本对原假设进行判断,有两种方法,临界值法和P值法。临界值法是根据显著性水平和统计量的分布确定一个检验统计量的临界值,然后根据检验统计量的值与临界值之间的关系来做决定。 在引例中,临界值就是下面$2.1$节中的待定常数C,检验统计量就是样本均值$\bar{X}$.
引例:
体重指数BMI是目前国际上常用的衡量人体胖瘦程度以及是否健康的一个标准,专家指出,健康成年人的BMI取值应该在18.55-24.99之间。某种减肥药广告宣传,连续使用该种减肥药一个星期便可以达到减肥的效果。为了检验其说法是否可靠,随机抽取9位实验者(要求BMI指数超过25、年龄在20-25岁的女生),先让每位女生记录没有服用减肥药之前的体重,然后让每位女生服用该减肥药,服药期间,要求每位女生保持正常的饮食习惯,连续服用该减肥药1周后,再次记录各自的体重。测得服用减肥药前后的体重差值(服药前体重 - 服药一周后体重)(单位:kg):
$$1.5, 0.6, -0.3, 1.1, -0.8, 0, 2.2, -1.0, 1.4$$
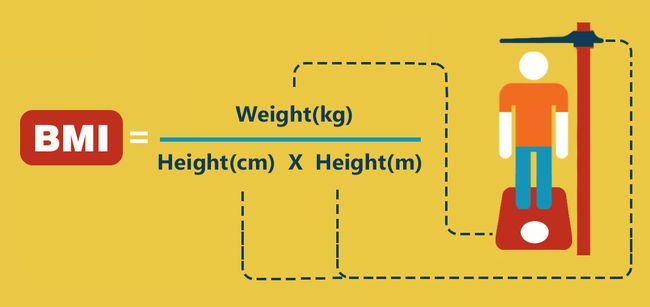
图1:BMI计算公式
问题:根据目前的样本资料能否认为该减肥药广告中的宣称是可靠的?
这里提出的问题就是一个假设检验的问题,包括以下要素:
1). 我们有一个总体,即所考察的BMI指数超过25、年龄在20-25岁的女生服用减肥药一周前后的体重差(这是理想总体,虽然没有在所有符合条件的人群中做实验),且假设该总体服从正态分布$X \sim N(\mu, \sigma^2)$,为了解题方便进一步假设方差$\sigma^2 = 0.36$. 此时总体的分布还有未知参数$\mu$.
2). 从该总体中中抽出的9个样本,即9位参与试验的人.
3). 有一个命题,其正确与否完全取决于未知参数$\mu$的值. $\mu$的取值可以分为三个部分,表示不同的实验效果:$\mu = 0$时表示体重没有变化;$\mu > 0$表示体重下降了;$\mu < 0$表示体重增加了. 在做判断时,只有$\mu > 0$的情况(甚至更严格)才有可能支持"减肥药有效"这个结论.
下面是进行假设检验的一般步骤。
2.1 建立两个完全对立的假设:原假设与备择假设
在作假设检验之前,必须确定原假设(或零假设,$H_0$)和备择假设(或对立假设,$H_1$)。这两个假设通常是完全对立的,例如药物有效与无效,基因表达量有差异与没有差异等。决定谁作原假设,依赖于立场、惯例和方便性。选择零假设的基本原则是:保护零假设,尽量维持现状或取简单假设。例如筛选差异基因,原假设是两组基因没有差异,只有在具有了充足的证据,证明两组基因是有差异的,才能拒绝原假设,说明它们是有差异的。
对于引例中的问题来说,站在消费者的角度,需要严格看待减肥药的效果,因此原假设可以设定为该药物没有作用。那么根据题设,转化成数学语言为:
服用减肥药前后体重差值$X \sim N(\mu, \sigma^2)$,方差$\sigma^2 = 0.36$
检验假设:$H_0: \mu = 0, H_1: \mu > 0$
因为$\bar{X}$是$\mu$的无偏估计,$\bar{X}$的取值大小反映了$\mu$的取值大小,当原假设成立时,$\bar{X}$取值应偏小(这里X表示体重差,体重差越小表示该减肥药的效果越不明显)。因此,
当$\bar{X} \ge C$时,拒绝原假设$H_0$,
当$\bar{X} < C$时,接受原假设$H_0$,
其中C是待定常数——检验统计量的临界值。
2.2 给出检验统计量,并确定拒绝域的形式
在做统计分析时,很多步骤都与各种不同的分布有关,例如代表样本数值特征的统计量;用来做参数估计的枢轴量(包含一个未知量的统计量);还有这里出现的用于假设检验的检验统计量。
如果统计量$T = T(X_1, ..., X_n)$的取值大小与原假设$H_0$是否成立有密切联系,就可以将其称为对应假设问题的检验统计量,而对应于拒绝原假设$H_0$时,样本值的范围称为拒绝域,记为$W$,其补集$\bar{W}$称为接受域。确定一个检验,等价于指定其接受域或否定域。
引例中的检验统计量为$\bar{X}$,拒绝域为
$$W = \{(X_1, ..., X_n): \bar{X} \ge C\}$$
C如何选择,是问题的关键。
首先要理解C点的含义:C值取定后就是一个固定的值,C点将随机变量的整个取值范围$(0,+\infty)$分成了两个部分,左边为接受域,右边为拒绝域(这里衡量的是体重差,拒绝域在右边,没有考虑体重增加的情况)。
所以当样本均值$\bar{X} < C$时,就落到了接受域(也就是$\bar{X}$与0接近到了一定程度,类似于样本均值落到了0的邻域),就可以认为$\bar{X}$与0没有差别。又因为$\bar{X}$是总体均值$\mu$的无偏估计,因此可以认为总体的均值$\mu=0$,从而接受原假设$H_0$。当样本均值$\bar{X} > C$时,就落到了拒绝域(样本均值与0的差别非常大),所以就拒绝了原假设。
2.3 根据显著水平和统计量的分布确定临界值
两类错误
在检验一个假设$H_0$时,有可能犯以下两类错误之一:
1). $H_0$正确,但被否定了,即丢弃了真假设(弃真),也叫作"第一类错误"或"I型错误";
2). $H_0$不正确,但被接受了,即接受了假的假设(取伪),也叫作"第二类错误"或"II型错误"
在引例中,如果犯了第一类错误,就会将本来没有减肥效果的减肥药当做有减肥效果,从而对消费者的利益造成比较大的损害;如果犯了第二类错误,就会将本来有减肥效果的药物当做没有减肥效果,这会让制药公司蒙受损失。再举一个例子:某流行病的发病率为0.1%,由于发病率比较低,可以将"来检测的人没有患病"作为原假设$H_0$. 此时如果犯了第一类错误,就会将健康人诊断为病人从而开具错误的处方,通常也将这种情况称作假阳性;如果犯了第二类错误,就会将病人诊断为健康人从而可能使病人错过最佳治疗时间,且有可能传染给其他人,通常也将这种情况称为假阴性.
下面是一张广为流传的图,用来说明"假阳性"和"假阴性",其原假设$H_0$是"没有怀孕":

图2:假阳性&假阴性
我们希望在检验一个假设$H_0$时,犯两类错误的概率都尽量小。但是难免会有失误的时候,而且这两类错误是相互对立的:对于引例来说,假如检验的条件非常严格(例如规定必须每个人的体重都下降10kg),则犯第一类错误的概率就会比较小,但是大大提高了假阴性的概率。对于引例来说,犯第一类错误的后果显然比犯第二类错误的后果严重,因此检验的标准需要偏严格一些。
在区间估计中,也存在类似的问题:想要增大可靠性即置信系数,就会使区间长度变大而降低精度,反之亦然. 在区间估计中,是用"保一望二"的原则来解决这个问题的,即使置信系数达到指定值,在这个限制之下使区间精度尽可能大. 在假设检验中也是这样办:先保证第一类错误的概率不超过某指定值$\alpha$($\alpha$通常较小,最常用的是0.05和0.01,有时也取0.001, 0.1或0.2等值),在这个限制下,使第二类错误的概率尽可能小. 以上原则也被称为"奈曼-皮尔逊原则".
继续分析引例中的问题,取显著性水平$\alpha = 0.05$,
当原假设$H_0$成立时 $\Rightarrow \frac{\bar{X}}{0.6 / \sqrt{9}} \sim N(0, 1)$,(统计量的分布)
此时,显著性水平就是犯第一类错误的概率的上限:
$P\{\bar{X} \ge C | \mu=0\} = P\{\frac{\bar{X}}{\sigma/\sqrt{n}} \ge \frac{C}{\sigma/\sqrt{n}} | \mu=0\}$
$= 1 - \Phi(\frac{C}{\sigma/\sqrt{n}}) \le \alpha = 0.05.$, $(0.05 = \Phi(-z_{0.05}))$. $1 - \Phi(x)$越小,$x$越靠近分布的右端,值越大
$\Rightarrow \frac{C}{0.6/\sqrt{9}} \ge z_{0.05} = 1.645. \Rightarrow C \ge 0.329.$
其中,$\Phi(x)$表示区间$(-\infty, x)$上x轴与概率密度函数围成的面积;$z_{\alpha}$表示概率密度函数的上$\alpha$分位点;检验统计量是样本的均值,标准化后服从标准正态分布(总体方差已知).
2.4 根据样本得出结论
根据样本信息得,$\bar{X} = 0.522 > 0.329$.
当原假设$H_0$成立时,样本落在拒绝域的概率不超过0.05,这是一个小概率事件(小概率事件发生了)。
根据实际推断原理,有充分的理由拒绝原假设,认为厂家的宣传是可靠的.
同理,若$\alpha = 0.01$,可以计算得到$ W = \{ \bar{X} \ge 0.465\}$,此时条件变得更加严格,仍然可以拒绝原假设.
3. P值法
P值法的前两步与临界值法相同,下面是"P值法"的第三步和第四步. 由于在P值法中,只与显著性水平$\alpha$进行比较,也就是只对第一类错误进行了限制,因此也被称为"显著性检验"(Significance Test).
3.3 计算最小显著水平——P值法
P值的定义:当原假设$H_0$成立时,检验统计量取比观察到的结果更为极端的数值的概率。(如果比观察结果更极端的事件发生的概率非常小,那么观察结果本身发生的概率也会非常小!)
$$P_{\_} = P\{\bar{X} \ge \bar{x} = 0.522 | \mu = 0\} = 1 - \Phi(\frac{0.522}{0.6/\sqrt{9}}) = 0.0045 < \alpha = 0.05$$
按照P值的定义,现在观察到的结果为$\bar{x} = 0.522$,观察到比$\bar{x}$更大的结果的概率为0.0045. 这个概率非常小,小到几乎不可能发生.
那么此时的观察结果本身$\bar{x} = 0.522$的概率也非常小,接近0.0045,也就是说在原假设"减肥药无效"成立的情况下,小概率事件发生了,因此要拒绝原假设.
带概率性质的反证法:
该方法有点像"反证法",但是又有不同之处,因此被称为"带概率性质的反证法". 一般的反证法要求在原假设成立的条件下导出的结论是绝对成立的,如果事实与之矛盾,则完全绝对地否定原假设.
概率反证法的逻辑是:如果小概率事件在一次试验中发生,我们就以很大的把握拒绝原假设.
3.4 比较P_值与显著水平,得出结论
P_值与显著性水平$\alpha$的关系:
1). 若$P_{\_} \le \alpha$,等价于样本落在拒绝域内,因此,拒绝原假设,称检验结果在水平$\alpha$下是统计显著的;
2). 若$P_{\_} > \alpha$,等价于样本没有落在拒绝域内,因此,不拒绝(接受)原假设,称检验结果在水平$\alpha$下统计不显著.
reference
https://marginalrevolution.com/marginalrevolution/2014/05/type-i-and-type-ii-errors-simplified.html
https://allizhealth.com/wp-content/uploads/2016/07/BMI-Formula-1.jpg
http://www.360doc.com/content/17/0904/19/45877835_684588486.shtml
http://staff.ustc.edu.cn/~zwp/teach/Prob-Stat/Lec16_slides.pdf
《概率论与数量统计》,陈希孺,中国科学技术大学出版社,2009年2月第一版
中国大学MOOC:浙江大学&哈尔滨工业大学,概率论与数理统计