从上世纪80年代到今天,达梦数据库技术架构演进与应用全记录
导语: 本文根据黄海明老师在2018年5月10日【第九届中国数据库技术大会(DTCC)】现场演讲内容整理而成。

达梦技术总监黄海明
资深数据库专家,ITPUB论坛版主,具有13年以上数据库研发、测试、推广经验。带领团队将达梦数据库在国家电网、中国神华、中国铁建、中国民航、社保等重大行业的核心生产系统中的取得广泛应用。目前致力于达梦数据库核心技术研究及达梦数据库的推广工作。
摘要: 传统关系数据库经过几十年的发展,架构是否已经到了演进尽头?MPP、读写分离、共享存储、分库分表……琳琅满目的架构从何处来向何处去?未来关系数据库架构可能会如何发展?本主题以达梦数据库架构演进与创新为例,向大家分享我们的看法。
达梦数据库架构演进
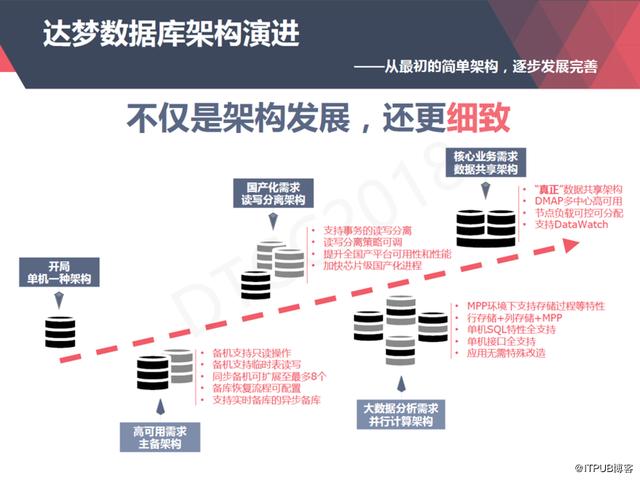
达梦数据库从上世纪80年代开始一直走自研的道路,既非基于开源,也并非源自第三方授权。
像Oracle数据库一样,达梦数据库开局也是一个单机数据库,这个单机数据库是1988年冯玉才教授研究出来的我国第一代有自主知识产权的数据库管理系统。随着达梦数据库在一些重要行业的广泛应用,为了解决高可用性的需求,达梦推出了主备架构。
随着“棱镜门”事件的发展,国家对信息安全的重视程度进一步提升,国家希望能够推行芯片级的国产化,为了在芯片级国产化的场景里面真正应用起来,达梦推出了读写分离架构。
2012年后大数据蓬勃发展,面对大数据分析的需求,达梦推出了大规模并行计算的架构。
达梦推出的架构,都是用匠人之心在做的。比如主备架构,我们的备机设计之初就是可以做只读的,Oracle 11G才支持只读,Oracle 10G的时候备机只能已mount状态启动,不能用于做查询。
另外,系统在做读写分离的时候,很多报表程序想在备机上运行,这个报表程序大部分是只读的,但是很多的报表程序需要用临时表存一下中间数据,临时表上一些增删改的操作无法在备机上完成。
在碰到这个需求之后,达梦对备机做了创新,就是达梦的备机可以支持对临时表的增删改,这样报表业务就可以运行在备机上面。
我们的备机可以支持实时的备机和异步备机,实时的备机主要做故障切换用的,如果报表程序要单独使用一个备机的话,我们可以在实时备机的基础上在加一个异步备机。
实际上,在X86的服务器上达梦单机的处理能力已经很强悍了,我们一般一个一主一备的主备的架构就足以应对很多核心的生产系统。到了芯片级的国产化环节就需要读写分离的架构,因为它的单机处理能力要稍微的弱一些。
我们的读写分离和传统的开源的读写分离架构是不太一样的,我们的读写分离不需要应用也不需要中间件去做分发,它是在我们的驱动程序和服务器端做的分发,这样对于应用是透明的。
另外,我们的读写分离可以同时兼顾性能和可靠性的问题,主备机之间可以做负载均衡,当主机出现故障的时候,它可以选择一台备机切换成主机对外响应业务。
在做大规模并行集群(MPP)的时候,我们也做了很多的创新,我们的MPP集群同时支持行存储和列存储。它不只是简单的做一个行存储引擎和列存储引擎,它会做很多的融合。
作为一个企业级的数据库,我们的MPP集群支持单机所有的SQL特性,包括单机支持的一些接口。对于共享存储的集群,我们也实现了跟Oracle架构完全一样的真正的数据共享集群。
主备架构

我们之所以做主备集群,主要源自于国家电网的国产化项目。在2008年,国家电网在新一代智能调度系统里开始全面做国产化,这里选用的数据库就是达梦数据库。
国家电网新一代智能调度系统可用性要求是99.99%,也就是说一年的停机时间不能超过两个小时。
我们以前的单机架构是无法满足这种需求的,比如升级的时候,你没有办法做滚动升级,于是我们推出了主备架构,这个主备架构也是基于REDO日志来做复制的,实现原理跟Oracle是完全一样的。
在中国铁建的财务共享平台项目中,我们针对财务系统的特点做了一个读写分离的解决方案,大家都知道财务系统的SQL语句是非常复杂的。
中国铁建有十几个局,以前每一个局都有一套财务系统,随着国家对央企管理越来越严,铁建要做一个财务共享服务平台,把每个局的财务系统全部集中到一起,专门成立一个财务公司来统一管理。
这样就面临着系统如何去实现国产化的问题,于是我们做了一个读写分离的架构,把日常的一些费用控制类的写操作较多的业务,放在主机上面,然后把那些SQL比较复杂的核算类的业务放在备机上去执行,这样便做了一些有效的读写分离。
但是我们也遇到了一个问题,就比如每个月末和季度末要出报表了,由于备机不知支持对临时表的增删改,报表程序只能放在主机上跑,这种情况下备机不是很忙,但主机很忙。
这个时候我们就希望把报表程序放在备机上面,进一步提高备机的利用率。于是我们便做了一个创新,就是在备机上面支持对临时表的插入、删除和更新的操作。
这样我们的报表程序就可以非常方便的切换到我们的备机上面去运行,有效的提高了资源的利用率。
读写分离

达梦的主备架构在很多的央企和政府里面获得了广泛的应用,当然大部分都是基于X86平台。
众所周知,美国商务部对中兴公司进行了封锁,完全暴露出我国在国产芯片上的短板。但实际上我们的国产芯片目前的处理能力其实还是可以的。
目前市面上可以买到的CPU主频可以达到1.5G以上,内核数大概在16核以上,支持的内存容量可以到64~128GB,这是目前国产CPU的整体水平,当然这和X86平台还是有一定差距的。
因为它不只是芯片的问题,是一个生态问题,CPU也需要很多的外设和操作系统、数据库之间的配合,所以它在单机处理能力以及整体可用性上就和X86系统稍微有一些差距。为了实现全国产的目的,我们研发出一个读写分离的架构。
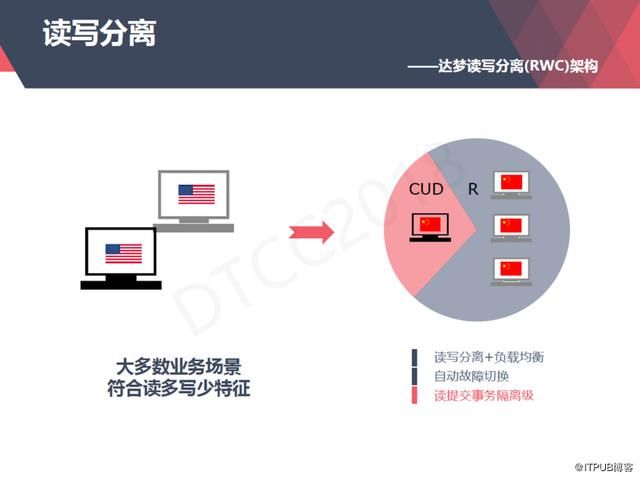
目前全国产的系统大多数的业务场景符合读多写少的特征,这样就可以把一些写的操作放在主机上,读的操作放在备机上。
整个读写分离的过程对用户来说是透明的,它通过我们的驱动程序和服务端自动做分发,也就是说单机的程序不需要做任何的修改,可以方便的移植到我们的读写分离系统上面来。
比如说我们一主三备组成的集群,这四台机器任何三台出现问题整个系统都是可用的,主机出现问题的话可以选用一台备机切换到主机,这个切换可以是手动的也可以是自动的;备机出现问题可以自动将坏掉的备机剔除出集群,主备之间始终保持着严格的一致性。
那么我们是怎么去做读写分离的呢?首先我们主备机之间的复制我们称之为及时归档,就是说我们主机产生的REDO传送给备机,备机应用了之后,主机才会提交,这样可以保证主机和备机之间的强一致性。有了这个的保障之后就可以做事务级的读写分离。
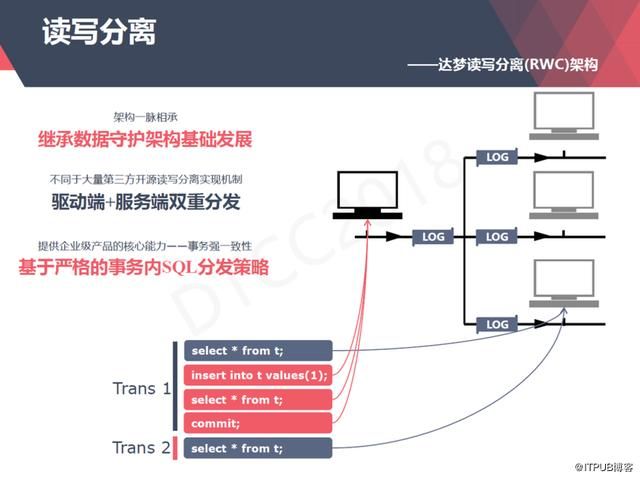
第一个事务是读和写的混合事务,它的第一个SQL语句是一个查询语句,我们的驱动会自动的把它分配到备机上去执行。
第二条语句是一个插入语句,我们把它分配到主机上去执行,并且在整个过程中,它下面的操作都是在主机上执行的。第一个事务是一个纯的查询类的业务直接分配到备机上去执行。主机和备机承担多少业务都是可以设置的。
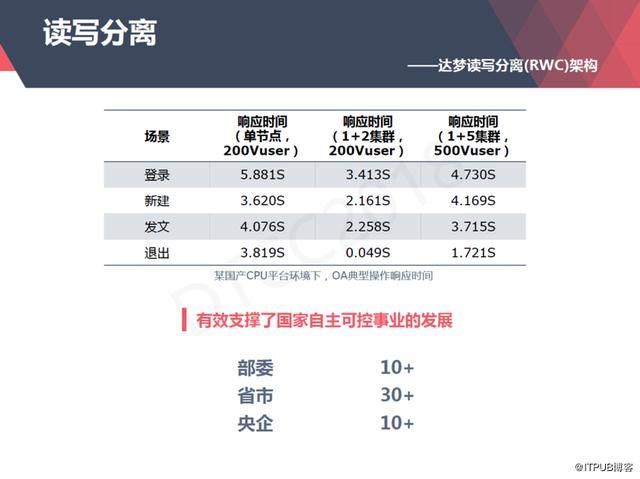
上图是我们做的一个测试,是在某国产CPU平台环境下面做了一个对OA典型应用性能的测试。系统的性能要求是500并发下所有操作的响应时间不超过5s,通过测试我们可以看出在200Vuser上,单机性能就显得非常勉强。
于是我们做了一个一主五备的集群,它可以满足500并发的需求。我们这个方案有效的支撑了国家安全可控事业的发展,目前,我们在10多个部委,30多个省市和10多个央企获得了应用。
并行计算

在2008年的时候,我们做了一个分析型的项目,数据量大概在5TB左右,当时是一个单机的架构。过程中我们做了很多的优化:建索引、改写SQL等,但是发现这些优化手段还是不能够满足性能的需求,因为它是一个即席查询,它的每一个列都有可能成为一个过滤条件。
所以在2011年的时候,我们推出了一个大规模并行集群的架构,它的储存和计算是在一起的,数据可以均衡的分布在集群的各个节点上,一条SQL过来的时候,每个节点同时运算,这样在一些表连接不多的场景,随着节点数的增多,性能可以得到一个线性的提升。
这种架构可以满足100TB以内分析型的需求,但是如果是100TB以上,这种架构就会表现出很大的局限性。因为它的存储和计算是一起的,要想满足需求我们就要将计算和存储做分离。达梦公司的下一代产品DM8就是一种弹性计算的架构,也就是存储和计算分离的架构。
我们将这种分析型的场景分了两类,一类是MPP加列存储,也就是统计分析型的业务。但是面对很多客户应用,它不仅仅是一个纯粹的统计分析型的业务,它还有很多的精确查询或条件查询。
例如社保,它需要建一个分析型集群,那么它就需要根据一些人的信息做一些精确查询,这种精确查询的并发量是非常大的,所以我们重点要解决的问题就是混合负载的问题,于是我们推出了行存储和列存储做融合的解决方案。
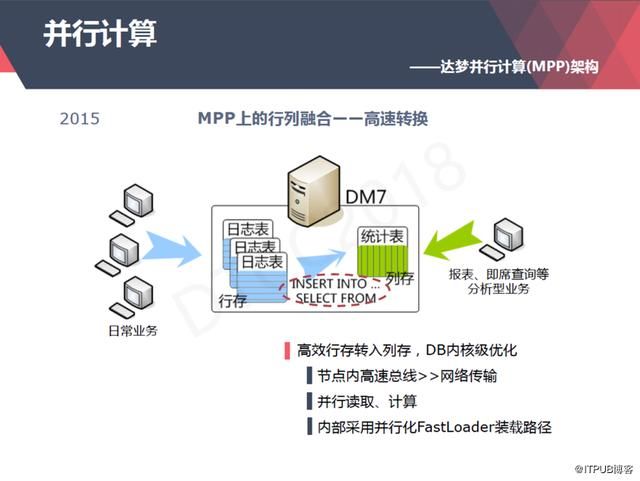
达梦在行列融合方面做了一些创新,首先就是在同一个MPP集群里面可以同时支持行存储和列存储。传统的列存数据库要把数据插入到列存的表里,前端需要设置一套ETL来做数据的入库,但是我们就不需要做这些,我们的行存储可以直接的转换成列存储,简单说就是一个查询插入的操作。
其次,另一个创新是源自于什么样的场景呢?比如做大数据分析,首先数据必须从生产系统同步到分析系统,传统的列存数据库可能需要用ETL做一些批量抽取,但它会有延时,而很多客户的应用场景又要求数据是实时的。
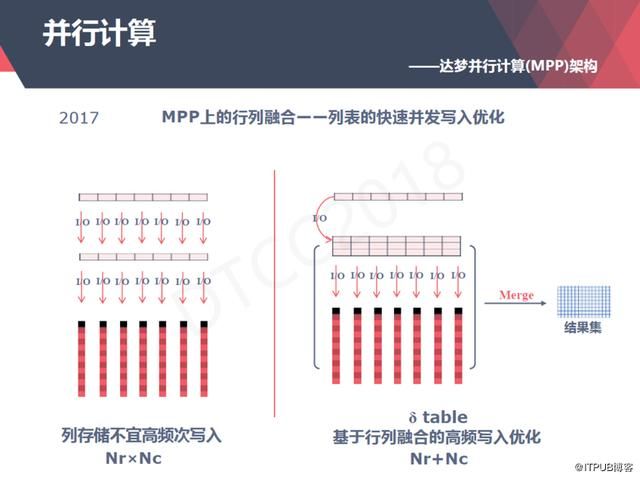
并且从事务型的数据库到分析型的数据库里面,列存储还面临一个问题,我们用一种类似Oracle OGG的工具去分析原库的数据库日志,在把它同步到列存储的目的库,但是这个列存库它不适合做高频次的单条插入,只适合批量操作。怎么去解决这个问题呢?
实际上我们每一个列存表都有一个隐藏的δ表,这个δ表是一个行存表,主要是做辅助的,这样对于单条的高频次插入操作来说,我们会先插入到行存表里面,然后到了一定的时机,它会把这些单条的操作变成一个批量的操作,然后写入我们列存的库里,用户去查询的时候,我们的优化器会自动去查询这个行存表和列存表,把它的结果做一个Merge后提供给用户,这整个过程对用户都是透明的。

有了这个行列融合的解决方案后,我们的MPP就不需要单独建一个查询库、一个分析库。对于高频次插入并发量比较大的精确查询业务,我们可以用行存表来支撑,对于大数据集上的一些统计分析业务我们可以用列存表来支撑。
这个MPP集群在很多大数据分析的场景里面获得了应用,比如河北省的公安云、吉林的公安云、湖北的公安云以及国家公商总局的企业信息公示系统等。工商总局的系统就是一个典型的互联网应用,每天的查询的次数都在几千万次以上,后台都是用我们MPP集群来支撑的。
数据共享
我们在做国产数据库售前交流的时候,我被客户问的最多的就是你们支持RAC吗?这是一个无法回避的问题,从现在来讲RAC不是是唯一的选择,但是2018年我们回头再去看这个问题,我们发现在做密集交易型的场景里面这种共享存储的集群仍然是一个非常好的选择。

Oracle的RAC叫真正应用集群,以前对“真正”这两个字没有什么体会,但是我们在做共享存储集群的时候就深刻的体会到了这两个字。因为实现共享存储集群要克服很多难题。首先它必须要实现缓存交换技术,这项技术Oracle叫缓存融合,也就是把每个节点上的内存当成一块公共的内存来使用。
其次要实现一套自动存储管理系统,每个节点都要做负载均衡,当节点出现故障的时候,要有整套故障处理的流程,包括故障恢复之后重加入的流程,整个过程对客户要是友好的、透明的。另外,各个集群、组件之间的状态要实现同步管理,我们叫集群同步管理软件。
而且 RAC是非常依赖于网络的,有很频繁的内存交换的动作,所以我们还要构建一套高速的私有网络。
在解决了这些棘手问题之后还要做广泛的兼容性,我们不仅要在X86平台上支持,还要在国产的飞腾、龙芯等平台上支持。
2016年,我们推出了共享存储集群,它可以满足三种特性,一个是高可用性,实现了两个节点的可读可写,当节点出现故障的时候,它可以自动处理,然后做重加入。
另一个是高吞吐量,对于Oracle为什么叫真正应用集群,因为它的每个节点都是可读可写的,实际上很多其他的数据库实现的所谓共享存储集群只有一个节点是可读写的,其他节点是只读的,并不是真正的共享存储集群。
还有一个特点就是要实现负载均衡,我们的驱动程序会自动的把连接均匀的分配到每一个节点上来,从而实现负载均衡。

目前,我们共享存储的集群在公安行业和检察行业获得了广泛的应用。
未来会是什么?

达梦数据库是一个通用型的商用数据库,我们的方案要对用户和合作伙伴负责。我们的用户和合作伙伴很多用了一些比较传统的技术,比如Pro*C、Hibernate等架构,我们都需要去一一兼顾。

所以对于未来的数据库架构来说,要对传统企业应用架构友好,最好能直接移植。这里提炼了几点,
第一个是要能横向扩展存储,应对越来越大的数据规模;
第二个是要灵活的运用资源,提升资源的利用率;
第三个是要保证服务的可用性,能够做故障的检测和切换;
第四个是要具备数据副本能力,保证数据可靠性;
最后一个是我们非常看重的,就是希望这一套架构要同时的满足事务型和分析型的业务。
弹性计算
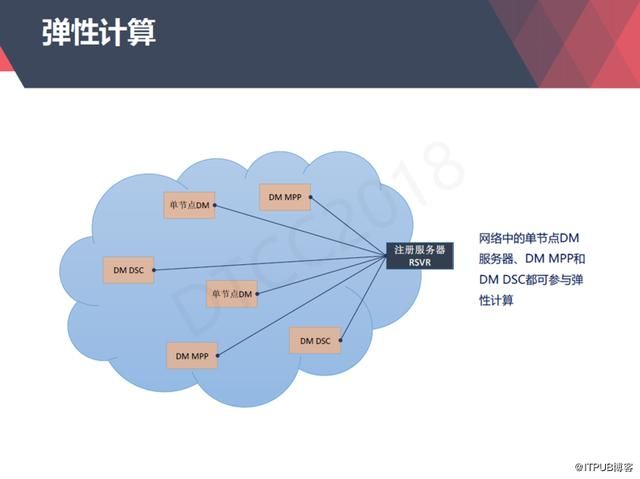
在达梦公司的下一代产品DM8里面提出来了一种弹性计算的架构。
首先在网络里面有一个注册的服务器,可以把这些MPP、单机、共享存储、读写分离等集群管理起来。
然后选一个主数据库,其他数据库做辅助,当一个客户请求过来的时候,主数据库就会判断目前的计算能力是否能够满足需求,如果满足不了就会生成一个弹性计算的子计划,
然后从注册服务器里面获取我们可用的计算资源的列表,然后我们把弹性计算的子计划和它的数据发送给我们辅助计算的节点,多个辅助计算的节点同时运算把计算结果反馈给主节点,主节点再做一些整合的计算,生成最终的结果。
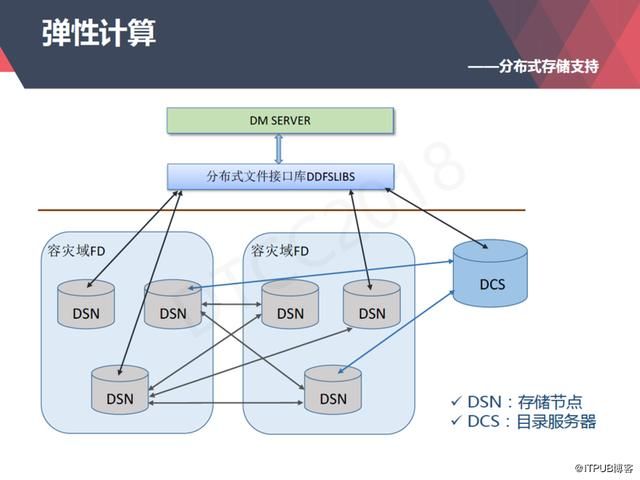
在存储层面我们开发自己的分布式文件系统,它分三个层面。最底下是存储层,在这一层我们提出了容灾域的概念。
我们认为一个容灾域里所有的副本和存储同时失效的可能性很大,所以我们容灾域里存储层的副本是在另外一个容灾域里面,它的副本可以是多个的。
另外我们还有一个目录服务器,主要做一些元数据的管理。中间我们提供了一个分布式文件访问接口,供上层计算节点调用。
其他
除此之外,DM8还做了很多高级特性。在行列融合方面,我们做了行列的深度融合,DM8可能是没有列存表的,我们对需要的行存表会自动的去维护一个影子的列存表,它的数据可以自动的同步,执行计划可以根据场景自己选择使用行存表还是列存表。目前的共享存储的集群只支持2个节点,但是我们DM8会支持到4节点或者8节点。
以后随着CPU计算能力的增强以及IO能力的广泛应用,网络会面临一个瓶颈,所以我们全面支持RDMA。
另外,之前DM7有很多查询优化的参数,很多的参数需要手动干预,但是DM8做了很多的智能化,可以根据不同的使用场景使用不同的优化参数。
在运维管理方面,我们的业务规模越来越大,需要管理的数据库也越来越多,所以我们会推出一个运维管理平台来做集中管理。
技术以外的话题

借用欢乐喜剧人的一句话:搞国产数据库,我们是认真的!
网上有几个观点,有的人认为数据库有开源的数据库可以用,有商业的数据库可以用,为什么要去做国产的数据库?为什么要重复的发明轮子?造不如买,买不如租!
目前,实践证明这种观点是站不住脚的。从美国商务部对中兴的封锁可以得出结论:我们的核心技术必须掌握在自己的手上。
大家现在才认识到这个问题,但是我们达梦人在30年前就已经认识到这个问题了,从那时候我们就开始自主研发做我们自己的数据库。
目前,国产的氛围很好,国产数据库也算是遇到了一个风口,很多厂商也开始做数据库,有开源的、有基于第三方商业授权的。
那从国家层面来说,到底什么样的数据库是安全可控的?
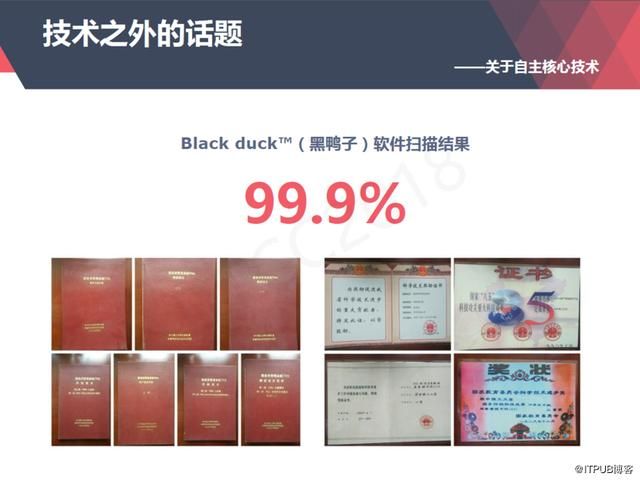
于是在2017年年底,国家组建了一个豪华阵容的专家团队做了一个审核。其中,审核中有很重要的一项,用黑鸭子软件对源代码进行比对,这个黑鸭子软件有2TB的开源代码,在比对的时候,达梦99.9%以上的代码是自主研发的。

当然除了以上情怀和自研,还有什么原因值得你选择达梦数据库呢?
总结一下,是有三个方面的需求。一方面是国家安全可控的需求,对于IOE去O很难的问题,达梦有更好的解决方法。达梦有和Oracle并行运行的逐步替代的科学方法来实现去O,达梦有一个数据同步的软件可以把 Oracle的数据实时同步到达梦数据库。
然后达梦具备很强的Oracle兼容性,同一套应用既可以运行在达梦上面也可以运行在Oracle上面,这样就可以并行运行一段时间,建立信任后,把达梦切换成主机,Oracle切换成备机,再之后把Oracle去掉。
通过这样的方法我们去掉了很多央企的核心生产系统的Oracle数据库。当然,仅仅在X86平台上面做国产化替代是不够的,在国产的CPU平台上面也要能够去替换国外的系统,达梦的读写分离的架构能够有效的推动国产芯片的实用化进程。
另外,中兴事件是一个警钟,央企选择达梦数据库也是基于这个考虑的,他们的选择基于两点,一个是技术上必须可行,经济上必须合理,这两个要求达梦都可以满足。
达梦在技术上可以根据用户需求不断创新,在服务上,给用户提供本地化的原厂服务,但是对于 Oracle来说,这种原厂服务费用很高。
达梦还可以更进一步的源代码级的服务,Oracle的服务层次只能到区域的服务中心,达梦的服务层次可以到达总部的研发中心。