python 下载拉钩教育AES加密视频
说在前面:
下面我们要爬取的是拉钩教育课程上面的视频,课程已经购买过了。但是由于没有提供缓冲和下载视频的功能,所以就打算把视频通过python给下载下来,以下的文章都是参考博友的,自己总结下并学习学习。
正式爬取:
1.拉钩教育的网址:https://kaiwu.lagou.com/,输入自己的账号和密码 ,然后登陆进去,找到自己已经购买的课程(这里我就举这个例子)。
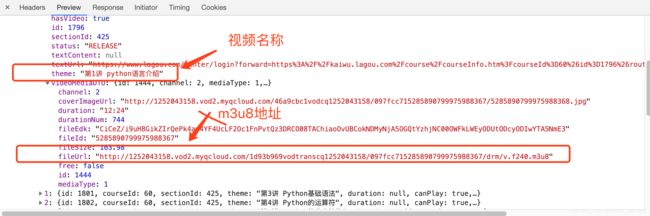
2.通过F12 抓包的方式,进入到控制台的network,最后找到的这个视频的请求地址,同时也找到视频的名字和地址(注意:cookies 和referer 字段 请求的时候一定要带上,因为电脑的原因截图没有显示出来)。

下面是请求头的代码,注意一定要带上cookie 和referer 字段,代码里面的cookie要修改成自己的,要不然会报错。
def __init__(self):
self.url = 'https://gate.lagou.com/v1/neirong/kaiwu/getCourseLessons?courseId=131'
self.headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36',
'Cookie': 'LG_LO7D',
'Referer': 'https://kaiwu.lagou.com/course/courseInfo.htm?courseId=131',
'Origin': 'https://kaiwu.lagou.com',
'Sec-fetch-dest': 'empty',
'Sec-fetch-mode': 'cors',
'Sec-fetch-site': 'same-site',
'x-l-req-header': '{deviceType:1}'}
self.queue = Queue() # 初始化一个队列
self.error_queue = Queue()
self.save_folder = r"/Users/拉钩视频下载/"
3.分析请求地址和请求后的响应内容,不难发现 返回的数据是json格式,所以只需要使用json()模块解析数据就可以了。
4.现在已经知道请求的地址,然后我们就可以发送请求,再解析数据了。现在有许多的视频网站,都是通过m3u8的方式把视频分割成ts视频流的方式,所以本次我们要得到的就是m3u8文件地址,再通过m3u8文件找到每一个单独的ts视频的地址以及AES128加密的key以及iv偏移量。
具体代码如下:
通过parse_one方法得到了所有课程的m3u8以及课程名,通过字典的形式进行存储,然后把得到的字典传递给下一个方法。
def parse_one(self):
"""
:return:获得所有的课程url和课程名 返回一个队列(请求一次)
"""
html = requests.get(url=self.url, headers=self.headers).text
dit_message = json.loads(html)
courseSectionList = dit_message['content']['courseSectionList']
for course in courseSectionList:
for i in course['courseLessons']:
if i['videoMediaDTO'] == None:
pass
else:
fileUrl = i['videoMediaDTO']['fileUrl']
theme = i['theme']
m3u8_dict = {fileUrl: theme} # fileUrl就是m3u8视频的url,theme为视频的名字
if os.path.exists(os.path.join(self.save_folder, "{}.mp4".format(theme))):
print("{}已经存在".format(theme))
pass
else:
self.queue.put(m3u8_dict) # 将每个本地不存在的视频url(m3u8)和name加入到队列中
return self.queue
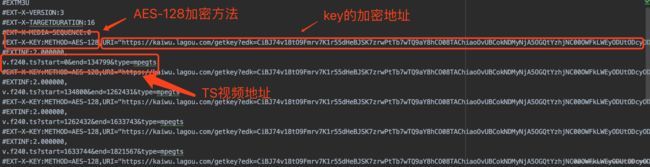
5.同样的道理,我们还需要向m3u8文件地址发送请求,可以从此请求中获取ts 以及key相关的信息。
然后,从下面这些信息中拿到key(key的url已经找到了,通过requests发送请求即可得到真正的二进制的key )以及所有ts的url(这里ts的url只给出了部分需要自己拼接,用发送请求的url进行拼接)。
这是m3u8文件的内容:
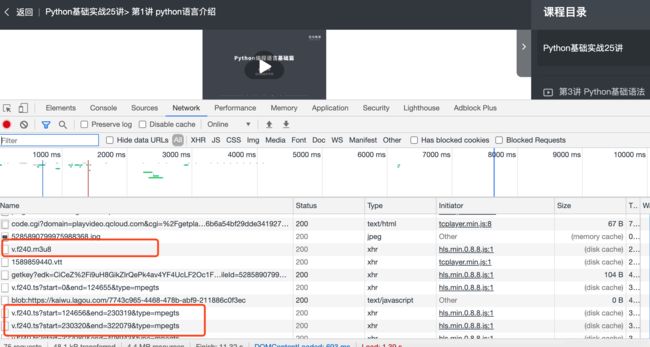
下面是每一节课程下面视频的m3u8地址 和ts地址,可以找一下规律,然后自己拼接下地址:
m3u8地址:
https://1252043158.vod2.myqcloud.com/1d93b969vodtranscq1252043158/097fcc715285890799975988367/drm/v.f240.m3u8
ts地址:
https://1252043158.vod2.myqcloud.com/1d93b969vodtranscq1252043158/097fcc715285890799975988367/drm/v.f240.ts?start=0&end=124655&type=mpegts
https://1252043158.vod2.myqcloud.com/1d93b969vodtranscq1252043158/097fcc715285890799975988367/drm/v.f240.ts?start=124656&end=230319&type=mpegts
这部分代码如下:
def get_key(self, **kwargs):
m3u8_dict = kwargs
for m3u8_url in m3u8_dict: # 获取某个视频的url
url_split = m3u8_url.split('.')[0:-2]
str_url = '.'.join(url_split)
true_url = str_url.split('/')[0:-1]
t_url = '/'.join(true_url) # 拼接ts的url前面部分
html = requests.get(url=m3u8_url, headers=self.headers).text # 请求返回包含ts以及key数据
message = html.split('\n') # 获取key以及ts的url
# 通过正则表达式获取key的列表以及ts的列表
key_parse = re.compile('URI="(.*?)"')
key_list = key_parse.findall(html)
key = requests.get(url=key_list[0], headers=self.headers).content # 一个m3u8文件中的所有ts对应的key是同一个 发一次请求获得m3u8文件的key
video_name = m3u8_dict[m3u8_url] # 视频的名字
for i in message:
if 'v.f240.ts?' in i:
ts_url = t_url + '/' + i # ts_url 就是拼接后每一个ts 视频流地址
self.write(key, ts_url, video_name, m3u8_dict)
代码解读:(对响应回来的数据进行各种切割拼接的操作以得到真正有用的内容)
- 1.遍历上一个请求穿过来的字典,通过这个m3u8_url可以拼接出ts真正的url
- 2.获取加密的秘钥key
- 3.将key,ts的url以及课程的名字传递给下一个方法
- 4.发送请求写入数据
6.破解AES128加密后视频,然后保存到本地,这部分代码如下:
def write(self, key, ts_url, name, m3u8_dict):
save_wav = os.path.join(self.save_folder, '{}.mp4'.format(name))
cryptor = AES.new(key, AES.MODE_CBC, iv=key)
with open(save_wav, 'ab')as f:
try:
html = requests.get(url=ts_url, headers=self.headers).content
f.write(cryptor.decrypt(html))
print('{},{}写入成功'.format(ts_url, name))
except Exception as e:
print('{}爬取出错'.format(name))
while True:
if f.close(): # 检查这个出问题的文件是否关闭 闭关则删除然后重新爬取,没关闭则等待10s,直到该文件被删除并重新爬取为止
os.remove('{}.mp4'.format(name))
print('{}删除成功'.format(name))
thread = self.thread_method(self.get_key, m3u8_dict)
print("开启线程{},{}重新爬取".format(thread.getName(), name))
thread.start()
thread.join()
break
else:
time.sleep(10)
完整代码如下:
使用多线程threading 和 Queue来爬取,速度提升很多。
import threading
from queue import Queue
import re
import requests
import json
from Crypto.Cipher import AES
import time
import os
class LaGou_spider():
def __init__(self):
self.url = 'https://gate.lagou.com/v1/neirong/kaiwu/getCourseLessons?courseId=131'
self.headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36',
'Cookie': 'LG_LOGI-9841821f-45eb-4135-9698-8d6b8280d898; LGUID=20200704113210-6a6a8c61',
'Referer': 'https://kaiwu.lagou.com/course/courseInfo.htm?courseId=131',
'Origin': 'https://kaiwu.lagou.com',
'Sec-fetch-dest': 'empty',
'Sec-fetch-mode': 'cors',
'Sec-fetch-site': 'same-site',
'x-l-req-header': '{deviceType:1}'}
self.queue = Queue() # 初始化一个队列
self.error_queue = Queue()
self.save_folder = r"/Users/拉钩视频下载"
def parse_one(self):
"""
:return:获得所有的课程url和课程名 返回一个队列(请求一次)
"""
html = requests.get(url=self.url, headers=self.headers).text
dit_message = json.loads(html)
courseSectionList = dit_message['content']['courseSectionList']
for course in courseSectionList:
for i in course['courseLessons']:
if i['videoMediaDTO'] == None:
pass
else:
fileUrl = i['videoMediaDTO']['fileUrl']
theme = i['theme']
m3u8_dict = {fileUrl: theme} # fileUrl就是m3u8视频的url,theme为视频的名字
if os.path.exists(os.path.join(self.save_folder, "{}.mp4".format(theme))):
print("{}已经存在".format(theme))
pass
else:
self.queue.put(m3u8_dict) # 将每个本地不存在的视频url(m3u8)和name加入到队列中
return self.queue
def get_key(self, **kwargs):
m3u8_dict = kwargs
for m3u8_url in m3u8_dict: # 获取某个视频的url
url_split = m3u8_url.split('.')[0:-2]
str_url = '.'.join(url_split)
true_url = str_url.split('/')[0:-1]
t_url = '/'.join(true_url) # 拼接ts的url前面部分
html = requests.get(url=m3u8_url, headers=self.headers).text # 请求返回包含ts以及key数据
message = html.split('\n') # 获取key以及ts的url
# 通过正则表达式获取key的列表以及ts的列表
key_parse = re.compile('URI="(.*?)"')
key_list = key_parse.findall(html)
key = requests.get(url=key_list[0], headers=self.headers).content # 一个m3u8文件中的所有ts对应的key是同一个 发一次请求获得m3u8文件的key
video_name = m3u8_dict[m3u8_url] # 视频的名字
for i in message:
if 'v.f240.ts?' in i:
ts_url = t_url + '/' + i # ts_url 就是拼接后每一个ts 视频流地址
self.write(key, ts_url, video_name, m3u8_dict)
def write(self, key, ts_url, name, m3u8_dict):
save_wav = os.path.join(self.save_folder, '{}.mp4'.format(name))
cryptor = AES.new(key, AES.MODE_CBC, iv=key)
with open(save_wav, 'ab')as f:
try:
html = requests.get(url=ts_url, headers=self.headers).content
f.write(cryptor.decrypt(html))
print('{},{}写入成功'.format(ts_url, name))
except Exception as e:
print('{}爬取出错'.format(name))
while True:
if f.close(): # 检查这个出问题的文件是否关闭 闭关则删除然后重新爬取,没关闭则等待10s,直到该文件被删除并重新爬取为止
os.remove('{}.mp4'.format(name))
print('{}删除成功'.format(name))
thread = self.thread_method(self.get_key, m3u8_dict)
print("开启线程{},{}重新爬取".format(thread.getName(), name))
thread.start()
thread.join()
break
else:
time.sleep(10)
# 创建多线程方法
def thread_method(self, method, value):
thread = threading.Thread(target=method, kwargs=value)
return thread
def main(self):
global m3u8
thread_list = []
m3u8_dict = self.parse_one()
while not m3u8_dict.empty():
for i in range(10): # 创建10个线程并启动
m3u8 = m3u8_dict.get() # 每次从队列取出一个对象 ,启动一个线程实例化对象,然后再放到线程列表中
thread = self.thread_method(self.get_key, m3u8)
thread.start()
print(thread.getName() + '启动成功,{}'.format(m3u8))
time.sleep(1)
thread_list.append(thread)
for k in thread_list:
k.join() # 回收线程
if __name__ == '__main__':
run = LaGou_spider()
run.main()
其实,我在这里有一个疑问 ,就是那个破解AES加密的时候,为什么iv也是key?
不应该是m3u8文件里面的那个iv偏移量吗?
cryptor = AES.new(key, AES.MODE_CBC, iv=key)
参考博客:Python爬虫实现全自动爬取拉钩教育视频