基于Python Spark的推荐系统
ALS推荐算法
Spark MLlib中实现了ALS(Alternating Least Squares)基于协同过滤的推荐算法。
MovieLens数据集
MovieLens数据集收集了大量用户对不同电影的评分,详情见数据集官网http://grouplens.org/datasets/movielens。
下载ml-100k数据至工作目录中,终端输入命令:
mkdir -p ~/pythonwork/PythonProject/data
cd ~/pythonwork/PythonProject/data
wget http://files.grouplens.org/datasets/movielens/ml-100k.zip
unzip -j ml-100k
启动 Hadoop Muti Node Cluster,复制ml-100k至HDFS中
start-all.sh
hadoop fs -mkdir /user/yyf/data
hadoop fs -copyFromLocal -f ~/pythonwork/PythonProject/data /user/yyf/
hadoop fs -ls /user/yyf/data
启动Ipython Notebook(Hadoop YARN-client模式)
终端输入命令:
cd ~/pythonwork/ipynotebook
PYSPARK_DRIVER_PYTHON=ipython PYSPARK_DRIVER_PYTHON_OPTS="notebook" HADOOP_CONF_IR=/usr/local/hadoop/etc/hadoop MASTER=yarn-client pyspark
准备数据
ALS算法训练数据的格式是Rating RDD数据类型
1、配置文件读取路径(IPython/Jupyter Notebook中键入以下命令)
global Path
if sc.master[:5]=="local":
Path="file:/home/yyf/pythonwork/PythonProject"
else:
Path="hdfs://master:9000/user/yyf/"2、导入ml-100k数据u.data
rawUserData=sc.textFile(Path+"data/u.data")
rawUserData.count()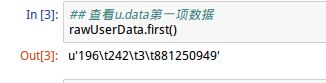
上图,4个字段分别是:用户id、项目(电影)id、评分、评分日期
导入Rating模块,读取rawUserData前3个字段,按照用户id、电影id、用户对电影的评分来编写rawRatings
rawRatings=rawUserData.map(lambda line:line.split("\t")[:3])
## 取前5项
rawRatings.take(5)
3、准备ALS训练数据
ALS训练数据格式 Rating RDD数据类型定义如下:
Rating(user,product,rating)其中,user字段是用户编号,product是产品编号,rating是用户对产品的评价

第一行表示:编号为196的用户对编号为242的电影的评分为3
统计用户数和电影数:

训练模型
1、导入ALS模块
from pyspark.mllib.recommendation import ALS使用ALS.train进行训练,两种训练模式:显式评分训练与隐士评分训练:
- 显式评分(Explicit Rating)训练
使用实际的电影评分,ALS.train(ratings,rank,iterations=5,lambda_=0.01)
- 隐式评分(Implicit Rating)训练
将实际的电影评分看作1(实际意义变成了用户对电影感不感兴趣的二分类标签问题),ALS.trainImplicit(ratings,rank,iterations=5,lambda_=0.01)
两种训练模式都会返回MatrixFactorizationModel模型,其中参数:
- ratings是格式为Rating RDD的训练数据
- rank指矩阵分解时,原本矩阵A(m*n)分解成X(m*rank)矩阵与Y(rank*n)矩阵
- iterations为迭代次数默认5
- lambda默认值为0.01
2、使用ASL.train命令进行训练

使用模型进行推荐
1、针对用户推荐电影
使用MatrixFactorizationModel.recommendProducts(user: Int, num: Int)方法,其中参数user为用户id,num为推荐的项数 。
例如对编号为666的用户推荐5部电影:
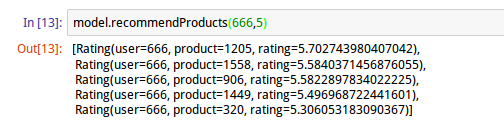
上图推荐结果中,第一项表示系统对用户666首先推荐的电影id,推荐的评分约为5.70。返回的结果按照评分从高到低排列,评分越高说明用户可能越感兴趣。
2、预测用户对某部电影的评分
使用.predict(user: Int, product: Int)方法:

上图的运行结果表示:编号为666的用户对编号为957的电影的评分可能为2.72
3、针对电影推荐用户
给定某部电影,将其推荐给可能对它感兴趣的用户,使用.recommendUsers(product: Int, num: Int)方法,其中参数product表示电影id,num表示推荐的用户数。
例如将编号为957的电影推荐给5个用户:

运行结果返回5个用户(对957最感兴趣的)以及相应的评分。
显示推荐电影的名称
读取u.item文件:

创建Recommend项目
建立Recommend项目,包含两个.py程序:
1、RecommendTrain.py
- (1) 数据准备阶段:读取u.data,经过处理后产生评分数据ratingsRDD
- (2) 训练阶段:评分数据ratingsRDD经过ALS.train训练后产生模型Model
- (3) 存储模型:存储模型Model在本地或HDFS中,作为后续推荐使用
2、Recommend.py
- (1) 数据准备阶段:读取u.item经过数据处理后,产生movieTitle(电影ID:电影名称)对照表
- (2) 载入模型:载入之前存储的模型Model
- (3) 推荐阶段:使用Model进行推荐,并使用movieTitle转换显示推荐电影名称
RecommendTrain.py
# -*-coding: utf-8 -*-
from pyspark import SparkContext
from pyspark import SparkConf
from pyspark.mllib.recommendation import Rating
from pyspark.mllib.recommendation import ALS
def SetPath(sc):
"""定义全局变量Path,配置文件读取"""
global Path
if sc.master[0:5] == "local": # 当前为本地路径,读取本地文件
Path = "file:/home/yyf/pythonwork/PythonProject/"
else: # 不是本地路径,有可能是YARN Client或Spark Stand Alone必须读取HDFS文件
Path = "hdfs://master:9000/user/yyf/"
def CreateSparkContext():
"""定义CreateSparkContext函数便于创建SparkContext实例"""
sparkConf = SparkConf() \
.setAppName("Recommend") \
.set("spark.ui.showConsoleProgress","false")
sc = SparkContext(conf=sparkConf)
SetPath(sc)
print("master="+sc.master)
return sc
def PrepareData(sc):
"""数据预处理:读取u.data文件,转化为ratingsRDD数据类型"""
rawUserData = sc.textFile(Path + "data/u.data")
rawRatings = rawUserData.map(lambda line: line.split("\t")[:3])
ratingsRDD = rawRatings.map(lambda x: (x[0], x[1], x[2]))
return ratingsRDD
def SaveModel(sc):
"""存储模型"""
try:
model.save(sc, Path+"ALSmodel")
print("模型已存储")
except Exception:
print("模型已存在,先删除后创建")
if __name__ == "__main__":
sc = CreateSparkContext()
print("==========数据准备阶段==========")
ratingsRDD = PrepareData(sc)
print("========== 训练阶段 ============")
print(" 开始ALS训练,参数rank=5,iterations=10,lambda=0.1")
model = ALS.train(ratingsRDD, 5, 10, 0.1)
print("========== 存储model ==========")
SaveModel(sc)Recommend.py
# -*-coding: utf-8 -*-
from pyspark import SparkContext
from pyspark import SparkConf
from pyspark.mllib.recommendation import MatrixFactorizationModel
import sys
def SetPath(sc):
"""定义全局变量Path,配置文件读取"""
global Path
if sc.master[0:5] == "local": # 当前为本地路径,读取本地文件
Path = "file:/home/yyf/pythonwork/PythonProject/"
else: # 不是本地路径,有可能是YARN Client或Spark Stand Alone必须读取HDFS文件
Path = "hdfs://master:9000/user/yyf/"
def CreateSparkContext():
"""定义CreateSparkContext函数便于创建SparkContext实例"""
sparkConf = SparkConf() \
.setAppName("Recommend") \
.set("spark.ui.showConsoleProgress","false")
sc = SparkContext(conf=sparkConf)
SetPath(sc)
print("master="+sc.master)
return sc
def loadModel(sc):
"""载入训练好的推荐模型"""
try:
model = MatrixFactorizationModel.load(sc, Path+"ALSmodel")
print("载入模型成功")
except Exception:
print("模型不存在, 请先训练模型")
return model
def PrepareData(sc):
"""数据准备:准备u.item文件返回电影id-电影名字典(对照表)"""
itemRDD = sc.textFile(Path+"data/u.item")
movieTitle = itemRDD.map(lambda line: line.split("|")) \
.map(lambda a: (int(a[0]), a[1])) \
.collectAsMap()
return movieTitle
def RecommendMovies(model,movieTitle,inputUserId):
RecommendMovie = model.recommendProducts(inputUserId, int(input[1]))
print("对用户ID为"+str(inputUserId)+"的用户推荐下列"+input[1]+"部电影:")
for p in RecommendMovie:
print("对编号为" + str(p[0]) + "的用户" + "推荐电影" + str(movieTitle[p[1]]) + "推荐评分为" + str(p[2]))
def RecommendUsers(model,movieTitle,inputMovieId):
RecommendUser = model.recommendUsers(inputMovieId, int(input[1]))
print("对电影ID为"+str(inputMovieId)+"的电影推荐给下列"+input[1]+"个用户:")
for p in RecommendUser:
print("对编号为" + str(p[0]) + "的用户" + "推荐电影" + str(movieTitle[p[1]]) + "推荐评分为" + str(p[2]))
def Recommend(model):
"""根据参数进行推荐"""
if input[0][0] == "U":
RecommendMovies(model, movieTitle, int(input[0][1:]))
if input[0][0] == "M":
RecommendUsers(model, movieTitle, int(input[0][1:]))
if __name__ == "__main__":
print("请输入2个参数, 第一个参数指定推荐模式(用户/电影), 第二个参数为推荐的数量如U666 10表示向用户666推荐10部电影")
input = [i for i in sys.stdin.readline().strip().split(" ")]
sc=CreateSparkContext()
print("==========数据准备==========")
movieTitle = PrepareData(sc)
print("==========载入模型==========")
model = loadModel(sc)
print("==========进行推荐==========")
Recommend(model)运行结果:
请输入2个参数, 第一个参数指定推荐模式(用户/电影), 第二个参数为推荐的数量如U666 10表示向用户666推荐10部电影
U666 10
==========数据准备==========
==========载入模型==========
载入模型成功
==========进行推荐==========
对用户ID为666的用户推荐下列10部电影:
对编号为666的用户推荐电影Boys, Les (1997)推荐评分为4.88358730439
对编号为666的用户推荐电影Pather Panchali (1955)推荐评分为4.75295263874
对编号为666的用户推荐电影Some Mother's Son (1996)推荐评分为4.53178390243
对编号为666的用户推荐电影Anna (1996)推荐评分为4.50898184243
对编号为666的用户推荐电影Butcher Boy, The (1998)推荐评分为4.46272366026
对编号为666的用户推荐电影Spanish Prisoner, The (1997)推荐评分为4.46272366026
对编号为666的用户推荐电影Brothers in Trouble (1995)推荐评分为4.46272366026
对编号为666的用户推荐电影Butcher Boy, The (1998)推荐评分为4.46272366026
对编号为666的用户推荐电影They Made Me a Criminal (1939)推荐评分为4.39719073006
对编号为666的用户推荐电影Saint of Fort Washington, The (1993)推荐评分为4.37662670282