TensorFlow学习记录:用简单卷积神经网络实现Cifar10数据集分类
使用TensorFlow搭建一个简单的卷积神经网络实现Cifar10数据集分类,这个神经网络模型包括两个卷积层,两个池化层,卷积操作后在后面加三个全连层,最后一个全连层用于输出分类。整个神经网络架构图如下:
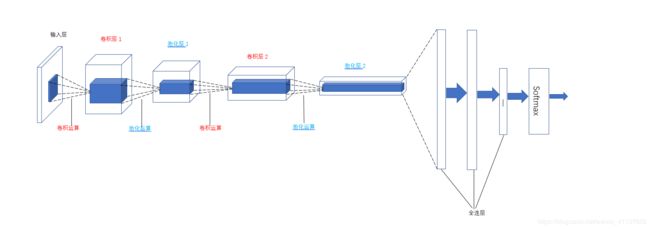
名词解释
| 名字 | 说明 |
|---|---|
| 输入层 | 输入层是整个神经网络的输入。在用于图像分类的卷积神经网络中,它一般代表的是一张图片的像素矩阵。根据通道数的不同,图片像素的矩阵也有着不同的深度数值,比如黑白图片只有一个通道,所以其深度为1;而在RGB色彩模式下图像有3个通道,所以深度为3。 |
| 卷积层 | 如上图所示,该神经网络有两个卷积层。卷积层由一系列执行了卷积操作而得到的特征映射图组成。这里卷积运算的过程是:对于单个卷积核,有3个通道,每个通道的分量分别与对应的被卷积张量的对应通道卷积,得到3个通道的卷积结果,然后这3个通道的卷积结果按元素叠加,生成一个通道的卷积结果,然后该卷积结果再经过激活函数,得到最终的卷积结果。至此,一个3通道的张量,经过一个3通道的卷积核后,得到了一个单通道的张量。常用的卷积核大小有3x3或者5x5.为了能从神经网络中的每一小块得到更多的抽像特征,一般卷积层的单元矩阵会比上一层的单元矩阵更深,也就是使用了多个卷积核。 |
| 池化层 | 池化层的单元矩阵深度不会比上一层的单元矩阵更深,但是它能在宽度和高度方向缩小矩阵的大小。另外,加入池化层也能达到减少整个神经网络中参数的目的。 |
| 全连层 | 如上图所示,在得到池化层的结果后连接了3个全连层。我们可以将卷积层和池化层看成是图像特征提取的结果,图像中的信息在经过几轮卷积操作和池化操作的处理后,得到了更抽象的表达,这就是图像最基本的特征。在得到了提取的特征后,为了完成分类任务仍需要构建几个全连层。其实可以简单地理解为卷积层和池化层相当于人类的眼睛,专门用于信息特征的提取,全连层相当于人类的大脑,将提取到的特征进行整合处理,算出结果。 |
| softmax层 | 通过softmax层,可以得到输入样例所属种类的概率分布情况。 |
Cifar-10数据集
Cifar-10数据集中包含60000张32*32彩色图像,其中训练集图像50000张,测试集图像10000张。这个数据集中包含了十个类别的图片,分别是airplane,automobile,bird,cat,deer,dog,frog,horse,ship和truck,并且其中没有任何重叠的情况,下面开始对这些图像进行分类。
首先去下载这个数据集,网址为 http://www.cs.toronto.edu/~kriz/cifar.html, 点击下载CIFAR-10 python version,然后解压。
开始编写.py文件
数据读取和预处理
导入相关库和定义一些需要用到的变量
import os
import tensorflow as tf
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
import numpy as np
import time
import math
num_classes = 10 #一共有10个类别
num_examples_pre_epoch_for_train = 50000 #50000个样本用于训练
num_examples_pre_epoch_for_eval = 10000 #10000个样本用于测试
max_steps = 4000 #训练4000步
batch_size = 100 #每次训练100个样本
num_examples_for_eval = 10000
data_dir = "C:/Users/Administrator/Desktop/Tensorflow/cifar-10-batches-bin" #下载的样本的路径
class CIFAR10Record(object): #定义一个空类,用于返回读取的Cifar-10数据
pass
接着定义一个read_cifar10()函数用于读取文件队列中的数据
def read_cifar10(file_queue): #file_queue为图片路径
result = CIFAR10Record() #创建一个CIFAR10Record对象
label_bytes = 1 #标签占一个字节
result.height = 32 #图像高为32像素
result.width = 32 #图像宽为32像素
result.depth = 3 #因为是RGB三通道,所以深度为3
image_bytes = result.height * result.width * result.depth #结果为3072,即一幅图像的大小为3072字节
record_bytes = label_bytes + image_bytes #加上标签,即一个样本一共有3073字节
reader = tf.FixedLengthRecordReader(record_bytes=record_bytes) #使用FixedLengthRecordReader类创建一个用于读取固定长度字节数信息的对象(针对bin文件而言)
result.key, value = reader.read(file_queue) #使用该类的read()方法读取指定路径下的文件
#这里得到的value就是record_bytes长度的包含多个label数据和image数据的字符串
record_bytes = tf.decode_raw(value, tf.uint8)
#decode_raw()可以将字符串解析成图像对应的像素数组
#strided_slice(input,begin,end)用于对输入的input截取[begin,end)区间的数据
result.label = tf.cast(tf.strided_slice(record_bytes, [0], [label_bytes]), tf.int32)
#这里把record_bytes的第一个元素截取下来然后转换成int32类型的数
#剪切label之后剩下的就是图片数据,我们将这些数据的格式从[depth*height*width]转换为[depth,height,width]
depth_major = tf.reshape(tf.strided_slice(record_bytes, [label_bytes], [label_bytes + image_bytes]),
[result.depth, result.height, result.width])
#将[depth,height,width]的格式转换为[height,width,depth]的格式
result.uint8image = tf.transpose(depth_major, [1, 2, 0])
return result
紧接着read_cifar10()函数的是inputs函数,这个函数用于构建文件路径,将构建的文件路径传给read_cifar10()函数读取样本,对读取到的样本进行数据增强处理。
def inputs(data_dir, batch_size, distorted): #data_dir为文件路径,batch_size为读取批量大小,distorted是否对样本进行增强处理
#拼接文件名路径列表
filenames = [os.path.join(data_dir, "data_batch_%d.bin" % i) for i in range(1, 6)]
#创建一个文件队列,并调用read_cifar10()函数读取队列中的文件,在后面还要调用一个tf.train.start_queue_runners()函数才开始读取图片
file_queue = tf.train.string_input_producer(filenames)
read_input = read_cifar10(file_queue)
#使用tf.cast()对图片数据进行转换
reshaped_image = tf.cast(read_input.uint8image, tf.float32)
num_examples_per_epoch = num_examples_pre_epoch_for_train
if distorted != None:
#将[32,32,3]大小的图片随机剪裁成[24,24,3]的大小
cropped_image = tf.random_crop(reshaped_image, [24, 24, 3])
#随机左右翻转图片
flipped_image = tf.image.random_flip_left_right(cropped_image)
#随机调整亮度
adjusted_brightness = tf.image.random_brightness(flipped_image, max_delta=0.8)
#随机调整对比度
adjusted_contrast = tf.image.random_contrast(adjusted_brightness, lower=0.2, upper=1.8)
#对图片每一像素减去平均值并除以像素方差
float_image = tf.image.per_image_standardization(adjusted_contrast)
#设置图片及标签的形状
float_image.set_shape([24, 24, 3])
read_input.label.set_shape([1])
min_queue_examples = int(num_examples_pre_epoch_for_eval * 0.4)
print("Filling queue with %d CIFAR image before starting to train.""This will take a few minutes." % min_queue_examples)
#shuffle_batch()函数通过随机打乱张量的顺序创建批次.
images_train, labels_train = tf.train.shuffle_batch([float_image, read_input.label], batch_size=batch_size,
num_threads=16,
capacity=min_queue_examples + 3 * batch_size,
min_after_dequeue=min_queue_examples)
return images_train, tf.reshape(labels_train, [batch_size])
#不对图像进行数据增强处理
else:
resized_image = tf.image.resize_image_with_crop_or_pad(reshaped_image, 24, 24)
float_image = tf.image.per_image_standardization(resized_image)
float_image.set_shape([24, 24, 3])
read_input.label.set_shape([1])
min_queue_examples = int(num_examples_per_epoch * 0.4)
images_test, labels_test = tf.train.batch([float_image, read_input.label], batch_size=batch_size,
num_threads=16, capacity=min_queue_examples + 3 * batch_size)
return images_test, tf.reshape(labels_test, [batch_size])
接下来开始设计卷积神经网络
定义一个variable_with_weight_loss()函数来创建卷积核权重和全连层的权重参数,使用truncated_normal()函数产生截断的正态分布来创建权重;但是这里会给权重增加一个L2的loss,相当于做了一个L2的正则化处理,目的是减少特征权重,防止过拟合。
def variable_with_weight_loss(shape, stddev, w1):#shape为权重的形状,stddev为正态分布标准差,w1控制L2 loss的大小,相当于公式中的λ
var = tf.Variable(tf.truncated_normal(shape, stddev=stddev)) #生成权重矩阵
if w1 is not None:
weights_loss = tf.multiply(tf.nn.l2_loss(var), w1, name="weights_loss") #给权重矩阵增加L2正则化,w1控制L2 loss的大小
tf.add_to_collection("losses", weights_loss) #将权重矩阵增加到集合losses中,它会在后面计算神经网络整体loss时被用上
return var
#注:公式为J(w)+λR(w),J(w)原为损失函数,R(w)为L2正则化项,λ为提前挑选的值,控制偏好小范数的权重(越大的λ偏好范数越小的权重)
开始读取图片
#对于训练用的图片,distorted=True,表示进行数据增强处理,这样就可以获得更多带噪声的样本,相当于扩大了样本量
images_train, labels_train = inputs(data_dir=data_dir, batch_size=batch_size, distorted=True)
#对于测试用的图片,distorted=None,表示不进行数据增强处理
images_test, labels_test = inputs(data_dir=data_dir, batch_size=batch_size, distorted=None)
创建x和y_两个placeholder用于在训练或评估时提供输入的数据和对应的label。
x = tf.placeholder(tf.float32, [batch_size, 24, 24, 3])
y_ = tf.placeholder(tf.int32, [batch_size])
创建卷积层和池化层
kernel1 = variable_with_weight_loss(shape=[5, 5, 3, 64], stddev=5e-2, w1=0.0)#shape=[5, 5, 3, 64]表示输入图像的通道数为3,生成64个大小为5*5,通道数量为64的卷积核
conv1 = tf.nn.conv2d(x, kernel1, [1, 1, 1, 1], padding="SAME") #x为输入图像,kernel1为卷积核,对x进行卷积 操作,[1, 1, 1, 1]为卷积操作步长,padding="SAME"表示对x的边界使用全零填充
bias1 = tf.Variable(tf.constant(0.0, shape=[64]))#生成64个偏置参数
relu1 = tf.nn.relu(tf.nn.bias_add(conv1, bias1)) #使用relu函数进行去线性化处理
pool1 = tf.nn.max_pool(relu1, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1], padding="SAME")#池化操作,池化核大小为3*3,步长为2*2
kernel2 = variable_with_weight_loss(shape=[5, 5, 64, 64], stddev=5e-2, w1=0.0)#shape=[5, 5, 64, 64]表示从上层输入图像的通道数为64,生成64个大小为5*5,通道数量为64的卷积核
conv2 = tf.nn.conv2d(pool1, kernel2, [1, 1, 1, 1], padding="SAME")
bias2 = tf.Variable(tf.constant(0.1, shape=[64]))
relu2 = tf.nn.relu(tf.nn.bias_add(conv2, bias2))
pool2 = tf.nn.max_pool(relu2, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1], padding="SAME")
两个卷积层之后是3个全连层,为了能够将经过两个卷积层操作的的数据连接到全连层,需要使用reshape()函数将pool2输出变成一维向量,并使用get_shape()函数获取数据扁平化之后的长度。
reshape = tf.reshape(pool2, [batch_size, -1])#pool2为100个6*6通道数为64的图像,要把这些图像转换成[100,6*6*64]的数组,这里-1表示把3维结构拉直为1维结构
dim = reshape.get_shape()[1].value #dim即为每张图片的大小,每张图片被转化成1维数组,大小为6*6*64=2304
创建全连层
weight1 = variable_with_weight_loss(shape=[dim, 384], stddev=0.04, w1=0.004) #第一个全连层有384个隐藏单元
fc_bias1 = tf.Variable(tf.constant(0.1, shape=[384]))
fc_1 = tf.nn.relu(tf.matmul(reshape, weight1) + fc_bias1)
weight2 = variable_with_weight_loss(shape=[384, 192], stddev=0.04, w1=0.004)#第二个全连层有192个隐藏单元
fc_bias2 = tf.Variable(tf.constant(0.1, shape=[192]))
local4 = tf.nn.relu(tf.matmul(fc_1, weight2) + fc_bias2)
weight3 = variable_with_weight_loss(shape=[192, 10], stddev=1 / 192.0, w1=0.0)#第三个全连层为最后输出,有10个隐藏单元,代表10个类别
fc_bias3 = tf.Variable(tf.constant(0.0, shape=[10]))
result = tf.add(tf.matmul(local4, weight3), fc_bias3)
计算损失值
在权重参数生成函数variable_with_weight_loss()中,我们将L2正则化损失的参数加入到集合losses中,现在通过get_collection()函数获取这些集合中的损失值,并通过add_n()函数计算加和。优化器选择使用了Adam算法的AdamOptimizer,并设置全局学习速率为001.
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=result, labels=tf.cast(y_, tf.int64))
weights_with_l2_loss = tf.add_n(tf.get_collection("losses"))
loss = tf.reduce_mean(cross_entropy) + weights_with_l2_loss
train_op = tf.train.AdamOptimizer(1e-3).minimize(loss)
top_k_op = tf.nn.in_top_k(result, y_, 1)#获取输出分类准确率最高的那个数,即将10个输出类别中概率最大的值的索引与label比较,相同为True,不同为False
下面开始启动训练
with tf.Session(config=tf.ConfigProto(log_device_placement=True)) as sess:
tf.global_variables_initializer().run()
tf.train.start_queue_runners() #前面的tf.train.string_input_producer(filenames)只是创建了文件队列,还没有开始读取,只有执行tf.train.start_queue_runners()时系统才会启动线程开始读取数据。
for step in range(max_steps):
start_time = time.time() #开始时间
image_batch, label_batch = sess.run([images_train, labels_train])
_, loss_value = sess.run([train_op, loss], feed_dict={x: image_batch, y_: label_batch})
duration = time.time() - start_time #当前步所用时间
if step % 100 == 0: #每100步计算一次准确率和训练速度
examples_per_sec = batch_size / duration #100张图片/当前步所用时间=每秒钟训练多少张图片
sec_per_batch = float(duration)
print("step %d,loss=%.2f(%.1f examples/sec;%.3f sec/batch)" % (step, loss_value, examples_per_sec, sec_per_batch))
训练完成后,使用测试集进行预测。
测试集一个有10000张图片,但是我们依然要像训练时那样一个batch一个batch地输入数据。为了最大限度地使用完验证数据,我们先计算评测全部测试样本一共要多少个batch,得到一个num_batch,这个变量就作为循环进行的次数。
每一step都会使用run()函数执行获取images_test, labels_test的batch的过程,然后通过top_k_op操作计算模型能在这个batch上得到正确预测结果的样本数量,最后汇总所有预测正确的样本数量,求得全部测试样本中预测正确的样本数量,并将正确率打印出来。
num_batch = int(math.ceil(num_examples_for_eval / batch_size))
true_count = 0
total_sample_count = num_examples_for_eval
for j in range(num_batch):
image_batch, label_batch = sess.run([images_test, labels_test])
prediction = sess.run([top_k_op], feed_dict={x: image_batch, y_: label_batch})
true_count += np.sum(prediction)
print("accuracy=%.3f%%" % ((true_count / total_sample_count) * 100))
#输出accuracy=73.3%
参考书籍:《TensorFlow深度学习算法原理与编程实战》 蒋子阳 著