Python爬取豌豆荚软件分类
Python爬取豌豆荚软件分类以及下载量
一,查看网页
链接豌豆荚
红框内即为要爬取的元素
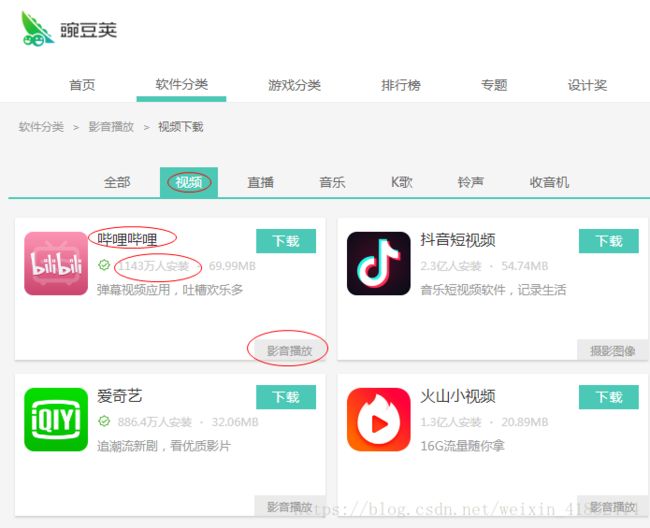
二,获取所有页签的地址:
#爬取豌豆荚
import requests
from bs4 import BeautifulSoup
import pandas as pd
#获取各个分类的url
data = requests.get('https://www.wandoujia.com/category/app')
s = BeautifulSoup(data.text, "html.parser")
divs = [li.div.find_all('a') for li in s.find_all('div')[4].find_all('ul')[0].find_all('li')]
urls_dict = {}
for i in range(len(divs)):
#print(divs[i])
for j in range(len(divs[i])):
title = divs[i][j].attrs['title']
url = divs[i][j].attrs['href']
urls_dict[title] = url
{‘视频’: ‘https://www.wandoujia.com/category/5029_716’,
‘直播’: ‘https://www.wandoujia.com/category/5029_1006’,
‘音乐’: ‘https://www.wandoujia.com/category/5029_722’,
‘K歌’: ‘https://www.wandoujia.com/category/5029_718’,
‘铃声’: ‘https://www.wandoujia.com/category/5029_719’,
‘收音机’: ‘https://www.wandoujia.com/category/5029_837’,
‘WiFi’: ‘https://www.wandoujia.com/category/5018_895’,
‘浏览器’: ‘https://www.wandoujia.com/category/5018_599’,
‘输入法’: ‘https://www.wandoujia.com/category/5018_597’,
‘优化’: ‘https://www.wandoujia.com/category/5018_596’,
‘省电’: ‘https://www.wandoujia.com/category/5018_601’,
‘安全’: ‘https://www.wandoujia.com/category/5018_598’,
‘Root’: ‘https://www.wandoujia.com/category/5018_947’,
‘文件管理’: ‘https://www.wandoujia.com/category/5018_948’,
‘聊天’: ‘https://www.wandoujia.com/category/5014_710’,
‘交友’: ‘https://www.wandoujia.com/category/5014_713’,
‘电话通讯’: ‘https://www.wandoujia.com/category/5014_712’,
‘私密’: ‘https://www.wandoujia.com/category/5014_922’,
‘婚恋’: ‘https://www.wandoujia.com/category/5014_946’,
‘社区’: ‘https://www.wandoujia.com/category/5014_714’,
‘桌面’: ‘https://www.wandoujia.com/category/5024_923’,
‘壁纸’: ‘https://www.wandoujia.com/category/5024_634’,
‘主题’: ‘https://www.wandoujia.com/category/5024_632’,
‘锁屏’: ‘https://www.wandoujia.com/category/5024_635’,
‘字体’: ‘https://www.wandoujia.com/category/5024_924’,
‘桌面部件’: ‘https://www.wandoujia.com/category/5024_968’,
‘动态壁纸’: ‘https://www.wandoujia.com/category/5024_975’,
‘小说’: ‘https://www.wandoujia.com/category/5019_605’,
‘新闻资讯’: ‘https://www.wandoujia.com/category/5019_963’,
‘电子书’: ‘https://www.wandoujia.com/category/5019_940’,
‘漫画’: ‘https://www.wandoujia.com/category/5019_606’,
‘听书’: ‘https://www.wandoujia.com/category/5019_604’,
‘搞笑’: ‘https://www.wandoujia.com/category/5019_607’,
‘美化’: ‘https://www.wandoujia.com/category/5016_721’,
‘相机’: ‘https://www.wandoujia.com/category/5016_720’,
‘搞怪’: ‘https://www.wandoujia.com/category/5016_933’,
‘图像编辑’: ‘https://www.wandoujia.com/category/5016_932’,
‘短视频’: ‘https://www.wandoujia.com/category/5016_920’,
‘相册’: ‘https://www.wandoujia.com/category/5016_921’,
‘学习’: ‘https://www.wandoujia.com/category/5026_638’,
‘英语’: ‘https://www.wandoujia.com/category/5026_936’,
‘背单词’: ‘https://www.wandoujia.com/category/5026_960’,
‘考试’: ‘https://www.wandoujia.com/category/5026_639’,
‘翻译’: ‘https://www.wandoujia.com/category/5026_969’,
‘驾考’: ‘https://www.wandoujia.com/category/5026_970’,
‘商城’: ‘https://www.wandoujia.com/category/5017_591’,
‘团购’: ‘https://www.wandoujia.com/category/5017_592’,
‘优惠’: ‘https://www.wandoujia.com/category/5017_593’,
‘快递’: ‘https://www.wandoujia.com/category/5017_949’,
‘全球导购’: ‘https://www.wandoujia.com/category/5017_966’,
‘支付’: ‘https://www.wandoujia.com/category/5023_631’,
‘炒股’: ‘https://www.wandoujia.com/category/5023_628’,
‘银行’: ‘https://www.wandoujia.com/category/5023_627’,
‘理财记账’: ‘https://www.wandoujia.com/category/5023_958’,
‘彩票’: ‘https://www.wandoujia.com/category/5023_629’,
‘借贷’: ‘https://www.wandoujia.com/category/5023_955’,
‘投资’: ‘https://www.wandoujia.com/category/5023_981’,
‘保险’: ‘https://www.wandoujia.com/category/5023_1003’,
‘小工具’: ‘https://www.wandoujia.com/category/5020_614’,
‘电影票’: ‘https://www.wandoujia.com/category/5020_918’,
‘美食’: ‘https://www.wandoujia.com/category/5020_610’,
‘娱乐’: ‘https://www.wandoujia.com/category/5020_612’,
‘上门服务’: ‘https://www.wandoujia.com/category/5020_950’,
‘汽车’: ‘https://www.wandoujia.com/category/5020_951’,
‘房产家居’: ‘https://www.wandoujia.com/category/5020_952’,
‘求职’: ‘https://www.wandoujia.com/category/5020_953’,
‘地图导航’: ‘https://www.wandoujia.com/category/5021_615’,
‘购票’: ‘https://www.wandoujia.com/category/5021_962’,
‘公交地铁’: ‘https://www.wandoujia.com/category/5021_618’,
‘用车租车’: ‘https://www.wandoujia.com/category/5021_954’,
‘住宿’: ‘https://www.wandoujia.com/category/5021_617’,
‘旅行攻略’: ‘https://www.wandoujia.com/category/5021_616’,
‘减肥健身’: ‘https://www.wandoujia.com/category/5028_959’,
‘医疗’: ‘https://www.wandoujia.com/category/5028_647’,
‘养生’: ‘https://www.wandoujia.com/category/5028_801’,
‘怀孕’: ‘https://www.wandoujia.com/category/5028_650’,
‘经期’: ‘https://www.wandoujia.com/category/5028_649’,
‘办公软件’: ‘https://www.wandoujia.com/category/5022_961’,
‘云盘存储’: ‘https://www.wandoujia.com/category/5022_626’,
‘效率办公’: ‘https://www.wandoujia.com/category/5022_919’,
‘笔记’: ‘https://www.wandoujia.com/category/5022_622’,
‘邮箱’: ‘https://www.wandoujia.com/category/5022_625’,
‘玩游戏’: ‘https://www.wandoujia.com/category/5027_645’,
‘育儿’: ‘https://www.wandoujia.com/category/5027_646’,
‘讲故事’: ‘https://www.wandoujia.com/category/5027_643’,
‘唱儿歌’: ‘https://www.wandoujia.com/category/5027_644’,
‘早教’: ‘https://www.wandoujia.com/category/5027_956’,
‘小儿百科’: ‘https://www.wandoujia.com/category/5027_971’}
三、根据获取的页签地址爬取每个页面的APP信息
每个页面只加载了一部分APP信息,点击查看更多,页面地址并没有变化。如何爬取出更多的APP信息呢
1、打开页面,点击开发者工具,选Network/XHR,
2、页面点击查看更多,找到地址链接查看发现每次查看更多,只有page增加1,在查看其它页面后,总结出url变化规律只有三个变量catId/subCatId/page。接下来就可以开始撸代码了
#获取软件分类
base_url = 'https://www.wandoujia.com/wdjweb/api/category/more?catId='
apps = {}
apps_install = {}
for key in urls_dict.keys():
# key = '视频'
num = 1
page_last = False
catid = urls_dict[key].split('/')[4].split('_')[0]
subCatId = urls_dict[key].split('/')[4].split('_')[1]
title_list = []
cat_second_list = []
install_list = []
while not page_last: #每个分类最后一页停止
#拼接出每页的url,点击加载更多,page会增1
url = 'https://www.wandoujia.com/wdjweb/api/category/more?catId={}&subCatId={}&page={}&ctoken=4Op4yfsiSsr8OAzRt5b1MtwE'.format(catid, subCatId, num)
print(url)
#爬取对应的网页
data = requests.get(url)
#解析出json
json = data.json()
content = json['data']['content']
if content != '': #判断是否最后一页
soup = BeautifulSoup(content, "html.parser")
#获取app的名称
title_list.extend([li.find_all('a')[1].attrs['title'] for li in soup.find_all('li')])
#获取app的二级分类
cat_second_list.extend([li.find_all('a', {'class':"tag-link"})[0].string for li in soup.find_all('li')])
#获取app的安装人数
install_list.extend([li.find_all('span', {'class':"install-count"})[0].string for li in soup.find_all('li')])
#保存到字典
apps[key] = dict(zip(title_list,cat_second_list))
apps_install[key] = dict(zip(title_list,install_list))
#加载下一页
num = num + 1
else:
#触发则表示当前分类已经加载所有页面,即到最后一页
page_last = True
#创建空数据框,保存到本地
apps_df = pd.DataFrame(columns = ['一级分类', '二级分类', 'app名称', '安装人数'])
app_ls = []
cat_ls = []
ins_ls = []
#将字典解析出来保存到数据框
for key in apps.keys():
print(key)
for app in apps[key].keys():
app_ls.append(app)
cat_ls.append(apps[key][app])
ins_ls.append(apps_install[key][app])
apps_df_tmp = pd.DataFrame({'app名称': app_ls, '二级分类':cat_ls, '一级分类': key, '安装人数': ins_ls})
apps_df = apps_df.append(apps_df_tmp)
#导出
apps_df.to_csv('wandoujia_app_cat.csv', index = False)
app名称,一级分类,二级分类,安装人数
哔哩哔哩,视频,影音播放,1143万人安装
抖音短视频,视频,摄影图像,2.3亿人安装
爱奇艺,视频,影音播放,886.4万人安装
火山小视频,视频,影音播放,1.3亿人安装
腾讯视频,视频,影音播放,709.6万人安装
优酷,视频,影音播放,626.3万人安装
迅雷,视频,影音播放,499.1万人安装
西瓜视频,视频,影音播放,465.6万人安装
影音先锋,视频,影音播放,273.8万人安装
虎牙直播,视频,影音播放,250.5万人安装
爱奇艺动漫,视频,影音播放,154万人安装
这样就把豌豆荚的软件分类爬取下来啦,快去试试吧~