C++的学习心得和知识总结 第十四章(完)
本章内容:OOP思想的应用,具体代码输出
文章目录
- 第一题:求迷宫路径(深度优先遍历)
- 第二题:求迷宫的最短路径(广度优先遍历)
- 第三题:大数的加减法
- 第四题:海量数据Top K系列问题和查重问题
- 第五题:海量数据Top K
- 第六题:海量数据Top K系列问题和查重问题的综合应用
第一题:求迷宫路径(深度优先遍历)
问题描述如下:

在使用OOP思想解决问题的时候,需要从具体的问题场景中。抽象出来哪些实体,在计算机上描述这个实体,那也就是类 。根据实体间的关系,也就得出了类与类之间的关系。
分析:迷宫行列,由人给出。所以说这个描述迷宫的二维数组是动态开辟出来的。迷宫整个地图可以看做是一个类(行、列、以及迷宫节点类型的二级指针:动态开辟二维数组)
迷宫是由一个个的具体位置节点组成,这每一个节点可以抽象成一个类(属性:横坐标、纵坐标、节点值、一个方向数组,表示这个节点四个方向的可走性);
接下来的问题就是:如何深度搜索一个迷宫路径?
答:如果使用非递归来实现深度搜索,那么肯定是需要一个栈了。如果当前节点可以走(其值为0),然后这个节点就可以放入到这个栈中了。然后开始查看栈顶元素,查看其4个方向的可走性,然后确定它是留在(保存最终的路径结果)栈里面,还是出栈(不可以作为路径的一个节点)。
这里再次分析问题,迷宫从左上角出发,如果能走到右下角,说明走通了(有路径)。否则在任何一节点卡死,则说明迷宫不通。这里使用的深度遍历,就是说 当前方向能走,则走下去。暂时不用管其他的方向,先沿着这个方向走下去(能走则一直走)。但是有一点需要注意:从当前节点走到下一个节点,那么这两个节点的方向应该改变为不能走。结束之后才真正把下个节点给入栈。
注:从左上角出发,为了尽可能快地到达右下角。迷宫的4个数组方向,规定方向的先后顺序为
1 → 2↓ 3← 4 ↑ 。
当行走过程中,发现走入了死路。(刚走过的路先被堵死,然后其他3个方向的路也走不了。那当然就是说这个节点 其实走不了,那于是就从栈里面删除这个节点,然后立即标注 刚才我走的这个路 是个死路,千万不可以再进去了。然后开始继续看原栈顶元素的其它方向了)。
最终源代码如下:
#include 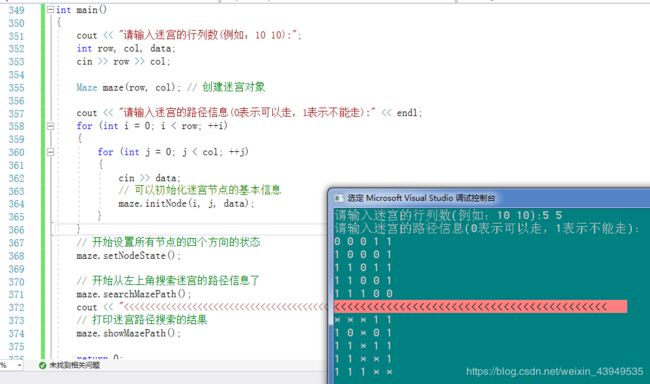
此次写代码,花费了大量时间在

先开始 这个地方写的是Node CurTop = _resultArrayStack.top(); 里面的CurTop,后来又修改成_resultArrayStack.top() 还是运行不出来结果。调试了5个多小时,心塞啊
多简单的问题 唉 !!!!!!!!!!!!
第二题:求迷宫的最短路径(广度优先遍历)
上面的深度优先,是走下去则沿着一个方向(规定好的 右 下 左 上),直至走出迷宫或者死胡同。当站在这个节点上,如果刚才规定好的那个方向可以走 则就按照那个方向前进。并不会去判断一下哪条路会近一些?例如 :上面的代码走下面的迷宫:

这样走,明显不是最优解,绕了很大的胡同。
当然只是简单的更换行走方向顺序,肯定也是不合适的。
这里就要使用到广度优先遍历 来找到迷宫路径的最短路径。
提高情况下:深度优先遍历采用的是递归 当然我们这里使用了栈实现了非递归版本。而广度优先遍历采用的是 类似剥洋葱的方式,逐渐接近最终解。以达到取得最优解的结果。当然这里就非常自然地使用上了队列的结构。

广度优先遍历的方式分析如下:从入口位置进入,把门口节点入队列。然后类似于 深度优先遍历,进入循环控制结构:队列不为空,然后检查队头元素的 4个方向的是否可行。依次把可以走的下一个位置给入队,注意:这里是所有可以走的下一步节点是都可以入队的。(当然是跟在队尾了) 处理完这个队头节点之后(4个方向都处理了),然后这个队头节点既可以走了。(当然在处理下一个这个可以走的位置的时候,节点间的移动状态也需要去置为NO)继续处理下一个队头元素。
经过循环之后,重点肯定是可以找到最短路径的。也就是我们在到达终点的时候,随着之前的入队、出队,可这些元素无论是有效的还是无效的,我们都没有保留下来。根本不确定 到底哪个元素才是属于这个最短路径上的节点呢?(深度优先遍历的栈最终保存的就是其路径信息)。所以这里就需要额外的花上一部分空间,来保存最短路径上的节点(行走过程中的这个最短路径节点之间的位置信息)都是哪些节点?
如下:最坏的情况无非就是 每个位置都可以走。

简单来做就是:把上面的二维数组(迷宫地图)的节点 一一映射到这个一位数组之上。(其实在内存之上,没有所谓的二维。只是抽象意义上的二维)
映射方法:二维数组的坐标(x,y)——》一位数组的坐标(x*Row+y)。这也即:一维数组的下标就标识着 二维数组上的某一个节点(唯一的)。
于是这样就好做了:从这个节点A到达下一个节点B,应该在一位数组B下标的数据域里面记载上A节点的二维坐标。(下次从B找它是从哪来的? 或者说 B的前一个节点元素是谁? 就可以很方便地根据B下标里面的二维坐标找到A)。
这样从最终的终点下标 在这个辅助数组里面往前找,直到找到门口节点。就可以把这个路径的节点信息 一一还原出来(一条完整的路径就出来了),这个过程是从后向前逆推的。

源代码如下:
#include 
第三题:大数的加减法
题目要求:实现大数的加减法。而且在主函数里面有 对象的输出,所以需要提供 operator+ operator- operator<<这三个方法。如果有时间,可以再实现一下 乘法和除法的实现。
#include 这里给定的BigInt对象,对外来说看着是BigInt类型的对象,但是对内,主要是看其成员属性其底层也只是一个string对象(成员变量)。这最终遍历的也就是这个字符串对象。
#include 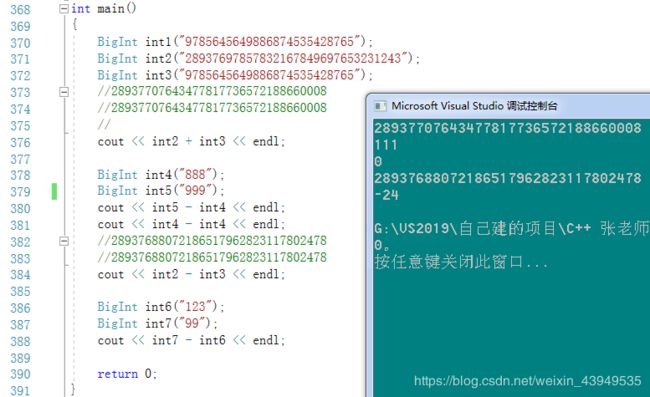
第四题:海量数据Top K系列问题和查重问题
大量数据求 Top K、查重
(1)值最大的前k个 或者 值最小的前k个。
(2)值第k大 或者 第k小的那和数据是多少
(3)哪些数据是重复的?重复了多少次?
(4)去重复问题
本节重点:海量数据的查重问题

但凡是查重复问题:就是要去使用增删查 近似达到O(1)时间复杂度的哈希表。如果是对于内存没有太大限制的场景,就可以一次使用哈希表。(牺牲空间换时间)。
(在32位Linux系统之下,一个int占4字节。10亿个数据,占内存大概为1*4G)所以说只是把这些数据存起来的话,就需要大量的内存(若是使用链式哈希表,除了数据域还有指针域),当然是不现实的。
(这里我们讨论的都是整数类型的查重)
如果是不允许这么大的内存使用,则这个时候需要使用上 分而治之的思想,把大量的数据量进行一个划分。
<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
(这里将使用一个Bloom Filter布隆过滤器进行大量数据的查重)
<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
倘若数据类型是 字符串类型,则也是可以使用哈希表和布隆过滤器的。可是对于字符串类型,我们有更好的处理办法:TrieTree字典树(前缀树)
<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
(这里将使用一个进行TrieTree字典树(前缀树)大量数据的查重)
<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
基于哈希表实现的undered_map undered_set。是最好用的工具 其中链式哈希表,是:解决哈希冲突是用链表把产生哈希冲突的数据连接起来,因此每一个节点除了保存整数数据,还需要保存指针域,因此10亿个整数,每个整数在多一个指针大小空间,那么整个链式哈希表算下来,大约需要4G(数据总数)+4G(指针总数)= 8G的内存空间。

问题1 :下面的数组,哪些数字重复了,以及重复了多少次?(没有提及内存的情况,意思就是重在了解解法思想)
#include 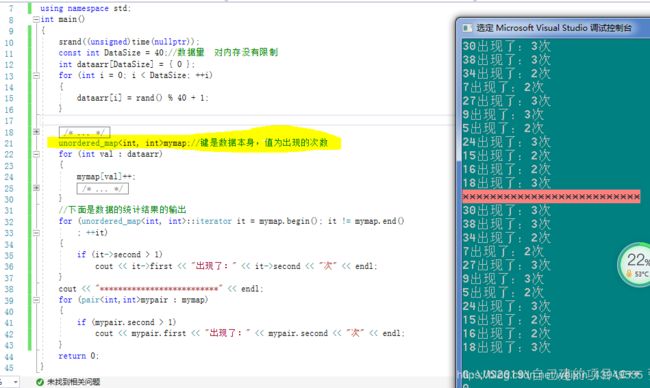
mymap对象是定义在栈上的,所以数据量太大的情况就会导致。栈空间不够使用,导致程序崩溃
问题2 :给定一个文件(里面有50亿数据),哪些数字重复了,以及重复了多少次
内存限制在400M
50亿个数据(整数)大概在20G的大小。倘若再使用上哈希表(40G:这是最差的结果了),所以不可能一下子把全部的数据都加载到这个Map表里面。

从大文件里面读出每一个data,然后mod文件个数(哈希映射函数:除留余数法),把这个数据放到对应序号的小文件中。为了减少哈希冲突,最好是个素数。这样做的话,值相同又经过同一个哈希映射函数,当然最后放在了同一个小文件中。(当然为了减少密集,把小文件个数上提(这样一个小文件的大小就不会超过400M了)。一个进程允许文件的个数大概到1024个)
然后对于每个小文件就可以读入到内存当中了,然后进行类似于上面的操作了。
这就是分而治之的思想
例子如下:这里50G/400M =128个 。做法就是将大文件的数据都通过除留余数法,把数据分散到众多的小文件里面,然后这些小文件每次都是可以直接加载到有所限制的内存之中的,然后进行操作。最终合并这些小文件的结果,得到最终的结果。
代码如下:
#include 
问题3:

10亿个数据,相当于1G的整数。也就是整数就4G了,使用上链式哈希表,就得到8G的结果。需要8G的内存才可以读进去,可是现在内存限制在400M上。约莫分上37个小文件就可以完美解决问题了。
这里的解决方案是:把a和b这两个大文件,划分成个数相等的一些小文件。这里照样使用的是分而治之的策略,比如都划分为37个小文件。

分别从a和b文件里面读取数据data。然后data%37=file_index.得到数据的下标,然后把数据存放在对于号的小文件之中。
![]()
毕竟这里采用的是,相同的哈希映射函数。最后处理的时候,是对应下标的小文件两两一起处理。
#include 
第五题:海量数据Top K

假如这里如果找的是前K大元素,需要的是小根堆。具体做法:把这么多数据的前k个元素放进去这个小根堆里面,(找前K大元素,就是在逐渐淘汰小值的过程),于是这前K个元素的最小值在堆顶存在。然后再逐渐遍历余下的整数,这些整数都和此时的堆顶进行比较。
(1)如果比堆顶元素小,则继续遍历下一个
(2)比堆顶大,则证明此时的堆顶元素,肯定不是前k大的元素。于是小根堆的堆顶出堆,然后这个比较大点的元素入堆。
(3)直至剩下数据遍历结束,此时的小根堆里面就保存的是前K大元素。
例如:

如果是找前K小元素,需要的是大根堆。 具体做法:把这么多数据的前k个元素放进去这个大根堆里面,(找前K小元素,就是在逐渐淘汰大值的过程),于是这前K个元素的最大值在堆顶存在。然后再逐渐遍历余下的整数,这些整数都和此时的堆顶进行比较。
(1)如果比堆顶元素大,则继续遍历下一个
(2)比堆顶小,则证明此时的堆顶元素,肯定不是前k小的元素。于是小根堆的堆顶出堆,然后这个比较小点的元素入堆。
(3)直至剩下数据遍历结束,此时的大根堆里面就保存的是前K小元素。
如果是找第K小元素,需要的是大根堆的堆顶
如果是找第K大元素,需要的是小根堆的堆顶
写代码的时候,我们也不需要去自定义 大小根堆:
![]()
<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
解法2:快排分割函数(效率会比大小根堆更高一些)
假如问题场景如下:共8个数据

对于快排分割函数而言,一趟下来:暂定把23作为基准数 ,可以使得小于23的调整到左边;大于23的调整到右边。基准数23 就可以算是调整结束了 O(log n)
实现步骤如下:
(1)把23先保存起来。从后向前,16小于23,则16调整到23位置处。如下:
![]()
(2)然后从左再向右找,遇到了45,大于23,则45调整到最后面位置上。
![]()
(3)再从右向左找:找到一个比23小的。5调整
![]()
(4)不存在从左往右,比23 小的值了。于是23可以归位了
![]()
于是、于是、于是一趟快排分割函数,23的位置也就调整好了。小于23的调整到左边;大于23的调整到右边。如下:

23 的数组下标是3(index),表示着23 是整个数组的第4(index+1)小的数据。而且前4小的数据就是23 前面的和23本身。
如果是找前k大的话,表示着23 是整个数组的第5大的数据。而且前4大的数据就是23 后面的和23本身。
如果这里找的是第2小的,则说明这个数据在23的左面。然后在23的左边进行 一次快排分割函数。如果这里找的是第6小的,则说明这个数据在23的右面。然后在23的右边进行 一次快排分割函数。
经过快排分割函数,能够在O(lgn)时间内,把小于基准数的整数调整到左边,把大于基准数的整数调整到右边,基准数(index)就可以认为是第(index+1)小的整数了,也即 [0,(index)]就是前index+1小的整数了
问题1:求vector容器中元素值最大的前10个数字。代码如下:
#include maxHeap;
priority_queue<int, vector<int>, greater<int>> minHeap;
// 先往小根堆放入10个元素
int k = 0;
for (; k < 10; ++k)
{
minHeap.push(vec[k]);
}
//构建一个小根堆,堆顶默认是最小的值
/*
遍历剩下的元素依次和堆顶元素进行比较,如果比堆顶元素大,
那么删除堆顶元素,把当前元素添加到小根堆中,元素遍历完成,
堆中剩下的10个元素,就是值最大的10个元素
*/
for (; k < vec.size(); ++k)
{
if (vec[k] > minHeap.top()) // O(log_2_10)
{
minHeap.pop();
minHeap.push(vec[k]);
}
}
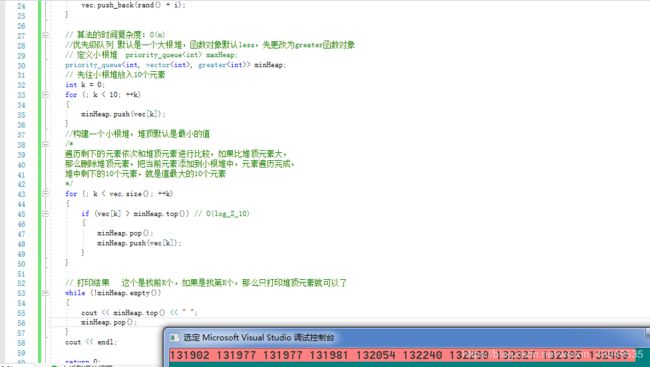
// 打印结果 这个是找前K个,如果是找第K个,那么只打印堆顶元素就可以了
while (!minHeap.empty())
{
cout << minHeap.top() << " ";
minHeap.pop();
}
cout << endl;
return 0;
}
算法的时间复杂度O(n):遍历这个容器。
问题2:求vector容器中元素值第10个小的数字。算法的时间复杂度O(log n)。代码如下:
#include &arr: 存储元素的容器
2.int i:数据范围的起始下标
3.int j:数据范围的末尾下标
4.int k:第k个元素
功能描述:通过快排分割函数递归求解第k小的数字,并返回它的值
*/
int selectNoK(vector<int>& arr, int i, int j, int k)
{
int pos = partation(arr, i, j);//得到一次快排分割后的基准数下标
if (pos == k - 1)
return pos;//找到了,返回这个POS可以做更多事情
else if (pos < k - 1)
return selectNoK(arr, pos + 1, j, k);//右边的下一个位置接着找
else
return selectNoK(arr, i, pos - 1, k);//左边的上一个位置接着找
}
int main()
{
/*
求vector容器中元素第10小的元素值 前10小的
*/
vector<int> vec;
for (int i = 0; i < 100000; ++i)
{
vec.push_back(rand() + i);
}
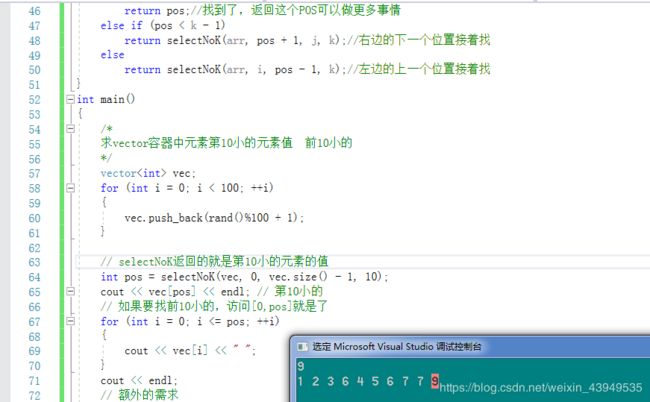
// selectNoK返回的就是第10小的元素的值
int pos = selectNoK(vec, 0, vec.size() - 1, 10);
cout << vec[pos] << endl; // 第10小的
// 如果要找前10小的,访问[0,pos]就是了
// 额外的需求
/*
有一个大文件,里面放的是整数,内存限制200M,求最大的前10个
采用的计算分治的思想了
大致计算一下整数文件的大小 / 200M = 要分的小文件的数量
哈希映射: 整数 % 小文件的个数 = file_index
然后现在每一个小文件就可以加载到内存当中了,就可以对每一个小
文件的整数求top k元素了,然后合并小文件结果即可
*/
return 0;
}
第六题:海量数据Top K系列问题和查重问题的综合应用
之前两节已经总结了 海量数据的两种问题场景:

本节主要讨论的是:海量数据重复次数最大/第k大的数据值是什么?
解法就是二种情形的综合考量:哈希表统计(使用映射表统计重复)+大小根堆/快排分割函数。联合求解问题。
/*
问题描述:
求vector容器中元素重复次数最大的第10个的元素值 前10多的元素值
*/
srand((unsigned)time(nullptr));
vector<int> vec;
for (int i = 0; i < 100; ++i)
{
vec.push_back(rand()%100 + 1);
}
这里要求的是 重复次数最大的第10 或者 前十多的数据值。
重复次数的统计如下:
unordered_map<int, int>mymap;//进行数据的统计
/*
【】运算符重载函数
拿val数字在map中查找,如果val不存在,numMap[val]会插入一个[val, 0]
返回其值0的引用。这么一个返回值,然后++,得到一个[val, 1]这么一组新数据
如果val存在,numMap[val]刚好返回的是val数字对应的second重复的次数,
直接++,即可。
*/
for (int val : vec)
{
mymap[val]++;
}
于是就把上面的数据源的全部数据和其重复次数都求出来了。
然后就需要在此基础之上,求出重复次数最多的k大,或者第K。
我们选择 小根堆进行查找。(当然这里使用快排分割也行,只是我需要的不仅仅是重复次数的排名,我还需要保存一下 重复次数最多的值 是谁?)

或者如下:
//这里需要的是一个小根堆类型 数字和重复的次数
typedef priority_queue<pair<int, int>, vector<pair<int, int>>,
function<bool(pair<int, int>&, pair<int, int>&)>>MinHeap;
//自定义小根堆的比较方式
MinHeap minheap([](pair<int, int>& src1, pair<int, int>& src2)->bool
{
return src1.second > src2.second;
});
如上:priority_queue 默认是一个大根堆,所以需要重新定义小根堆结构。自定义这个priority_queue,就是为了priority_queue的元素比较方式。priority_queue的第一个参数是元素类型,第二个参数是priority_queue 底层所依赖的容器的类型。(在数组上构建一个堆,才是可行的。毕竟是通过下标的相对位置来表示的)在第三个参数上(函数对象类型),需要传入一个函数对象(自定义小根堆的比较方式)。function函数对象类型接收bool(pair&,pair&)的类型函数,我们没必要去定义一个类型,这里函数对象类型接收传入lambda表达式。
MinHeap minheap([](pair<int, int>& src1, pair<int, int>& src2)->bool
{
return src1.second > src2.second;
});
这句话 是在定义小根堆对象,然后传入一个函数对象来指导编译器进行pair
int main()
{
/*
问题描述:
求vector容器中元素重复次数最大的第10个的元素值 前10多的元素值
*/
srand((unsigned)time(nullptr));
vector<int> vec;
for (int i = 0; i < 100; ++i)
{
vec.push_back(rand()%100 + 1);
}
unordered_map<int, int>mymap;//进行数据的统计
/*
拿val数字在map中查找,如果val不存在,numMap[val]会插入一个[val, 0]
返回其值0的引用。这么一个返回值,然后++,得到一个[val, 1]这么一组新数据
如果val存在,numMap[val]刚好返回的是val数字对应的second重复的次数,
直接++,即可。
*/
for (int val : vec)
{
mymap[val]++;
}
//统计结束
//这里需要的是一个小根堆类型 数字和重复的次数
typedef priority_queue<pair<int, int>, vector<pair<int, int>>,
function<bool(pair<int, int>&, pair<int, int>&)>>MinHeap;
//自定义小根堆的比较方式
MinHeap minheap([](pair<int, int>& src1,
pair<int, int>& src2)->bool
{
return src1.second > src2.second;
});
//找前10 重复次数多的元素值
// 先从map表中读10个数据到小根堆中,建立top 10的小根堆,最小的元素在堆顶
unordered_map<int, int>::iterator it = mymap.begin();
for (int i = 0;i < 10 && it!=mymap.end(); ++i,++it)
{
minheap.push(*it);
}
//继续遍历剩余的元素
for (; it != mymap.end(); ++it)
{
//如果map表中当前元素重复次数大于堆顶元素的重复次数,则替换
if (it->second > minheap.top().second)
{
minheap.pop();
minheap.push(*it);
}
}
// 堆中剩下的就是重复次数最大的前k个
while (!minheap.empty())
{
//auto& pair = minheap.top();
const pair<int, int>& pair = minheap.top();
cout << pair.first << " : " << pair.second << endl;
minheap.pop();
}
return 0;
}

新的需求来了:
![]()
常用解法:
![]()
#include 

注:vector采用clear()函数的时候只能清除元素,并不能清除内存,而要清除内存则可以用swap()。
vector<int> v;
for(size_t i = 0; i < 100; ++i)
{
v.push_back(i);
}
cout << "size=" << v.size() << " capacity=" << v.capacity() << endl;
v.clear();
cout << "After clear(): " << v.size() << " " << v.capacity() << endl;
vector<int> (v).swap(v);
cout << "After swap(): " << v.size() << " " << v.capacity() << endl;
结果如下:
size=100 capacity=128
After clear(): 0 128
After swap(): 0 0
这里的capacity是指vector v的容量,也就是占用的内存,最开始之所以容量是128而不是100,是因为vector在push_back的时候容量是按照2的指数增长的。当调用clear()函数之后,虽然size变成了0,但是其占据的内存并没有变,调用swap函数之后才能彻底的清除。