Python入门第五天——序列:列表、元组、集合、字典
文章目录
- 列表
- 创建列表
- 访问列表
- 删除列表
- 添加元素
- 查找元素
- 修改元素
- 删除元素
- 元组
- 创建元组
- 访问元组
- 修改元组
- 删除元组
- 查找元素
- 集合
- 创建集合
- 访问集合
- 删除集合
- 添加元素
- 删除元素
- 交集、并集、差集运算
- 集合常用方法:
- 字典
- 创建字典
- 访问字典
- 删除字典
- 添加键值对
- 修改键值对
- 删除键值对
- 字典常用方法:
序列(Sequence)是指按特定顺序依次排列的一组数据,可以占用一块连续的内存,也可以分散到多块内存中。序列类型包括列表(list)、元组(tuple)、字典(dict)和集合(set)。列表和元组比较相似,按顺序保存元素,所有的元素占用一块连续的内存,每个元素都有自己的索引,因此列表和元组的元素都可以通过索引(index)来访问。它们的区别在于:列表可以修改,元组不可修改。字典和集合存储的数据都是无序的,每份元素占用不同的内存,其中字典元素以 key-value 的形式保存。
有索引即可索引、切片、相加和相乘操作。列表和元组可以,字典和集合不可以。
索引:从左到右,索引值从 0 开始递增;从右向左,索引值 从-1 开始。
序列切片
切片是访问序列元素的另一种方法,可以访问一个,也可以访问一定范围内的元素
name[start : end : step]
1、name:表示序列的名称;
2、start:开始索引位置(包括该位置),默认不指定为 0,从序列的开头进行切片;
3、end:结束索引位置(不包括该位置),默认不指定为整个序列;
4、step:表示隔几个存储位置(包含当前位置)取一次元素,即step 大于 1,会“跳跃式”的取元素。不设置 step ,最后一个冒号省略。
序列相加
两种类型相同的序列使用“+”运算符将两个序列进行连接,但不会去除重复的元素。
序列相乘
一个序列乘以数字 n 会生成新的序列,其内容为原来序列被重复 n 次的结果。
和序列相关的内置函数
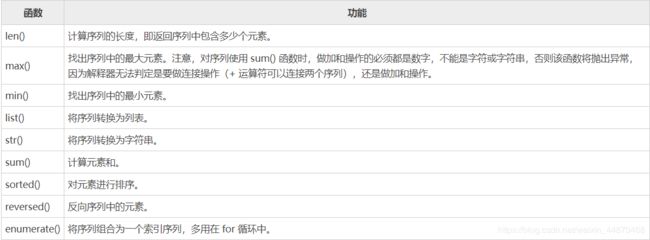
列表
所有元素都放在一对中括号[ ]里面,相邻元素之间用逗号,分隔
创建列表
1、使用 [ ] 直接创建列表,一般使用=将它赋值给某个变量
listname = [e1 , e2 , e3 , … , en] #可以一个元素都没,为空列表
2、使用 list() 函数创建列表,还可将其它数据类型转换为列表类型
list1 = list(“hello”)
print(list1)
访问列表
1、使用索引访问
listname[i]
2、使用切片访问
listname[start : end : step]
删除列表
1、使用del关键字
del listname
添加元素
1、append() 方法,列表的末尾追加单个元素或整体
listname.append(obj)
2、extend() 方法,列表末尾追加多个元素(合并)
listname.extend(obj)
3、insert()方法,任意地方插入元素
listname.insert(index , obj)
查找元素
1、index() 方法,查找某个元素出现的位置(索引),不存在,会导致 ValueError 错误
listname.index(obj, [start], [end])
返回的是索引值,而不是元素值
2、count() 方法,统计某个元素出现的次数
listname.count(obj)
返回0表示不存在
3、in字符 :判断值是否在列表中;not in字符 :判断值是否不再列表中
元素 in/not in 序列
修改元素
1、修改单个元素,直接赋值即可
num = [40, 36, 89, 2, 36, 100, 7]
num[2] = -26 #使用正数索引
2、修改多个元素,切片法给一组元素赋值
num = [40, 36, 89, 2, 36, 100, 7]
num[1: 4] = [45.25, -77, -52.5] #修改第 1~4 个元素的值(不包括第4个元素)
删除元素
1、del,可以删除整个列表,还可以删除列表中的某些元素(根据索引值)
del listname[start : end] #不包括 end 位置
2、pop() 方法,删除列表中指定索引处的元素,不指定index 参数,默认删除最后一个元素(出栈)
listname.pop(index)
3、remove()方法,根据元素值进行删除,只删除第一个和指定值相同的元素,必须保证元素存在,否则会 ValueError 错误
nums.remove(36)
4、clear()方法,删除列表所有元素
listname.clear()
元组
和列表的不同之处在于:列表是可变序列;元组是不可变序列,若子元素是可变类型,则可以改变子元素。
创建元组
1、使用 ( ) 直接创建
tuplename = (e1, e2, …, en)
2、使用tuple()函数创建,将其它数据类型转换为元组类型
tup2 = tuple(list1)
print(tup2)
访问元组
1、使用索引访问元组元素的格式为:
tuplename[i] #注意,索引方式和列表一样,用[ ]
2、使用切片访问元组元素的格式为:
tuplename[start : end : step]
修改元组
元素不能修改,只能拼接或者重新赋值
tup1 = (100, 0.5, -36, 73)
tup2 = (3+12j, -54.6, 99)
print(tup1+tup2)
tup1 = (12,89)
print(tup1)
运行结果为:
(100, 0.5, -36, 73, (3+12j), -54.6, 99)
(12,89)
删除元组
del 关键字将其删除
tup = (‘Java教程’,“http://www.av.com”)
del tup
查找元素
1、index() 方法,查找某个元素出现的位置(索引),不存在,会导致 ValueError 错误
tuplename.index(obj, [start], [end])
返回的是索引值,而不是元素值
2、count() 方法,统计某个元素出现的次数
tuplename.count(obj)
集合
和数学中的集合概念一样,用来保存不重复的元素,即集合中的元素都是唯一的,无序的。
创建集合
1、使用 {} 创建
setname = {e1,e2,…,en} #不能为空,空的话是字典类型
2、set()函数创建
setname = set(list1) #可以为空
访问集合
由于集合中的元素是无序的,无法用下标访问。最常用的方法是使用循环结构,将集合中的数据逐一读取出来。
a = {1,‘c’,1,(1,2,3),‘c’}
for ele in a:
print(ele,end=’ ')
运行结果为:
1 c (1, 2, 3)
删除集合
使用 del() 语句
del(a)
添加元素
setname.add(element)
add() 方法添加的元素,只能是数字、字符串、元组或布尔类型(True 和 False)值,不能添加列表、字典、集合等可变的数据,否则 Python 解释器会报 TypeError 错误。
删除元素
setname.remove(element)
交集、并集、差集运算
set1={1,2,3} 和 set2={3,4,5}
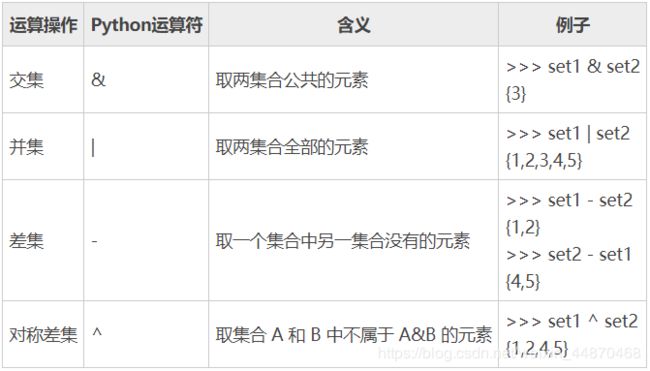
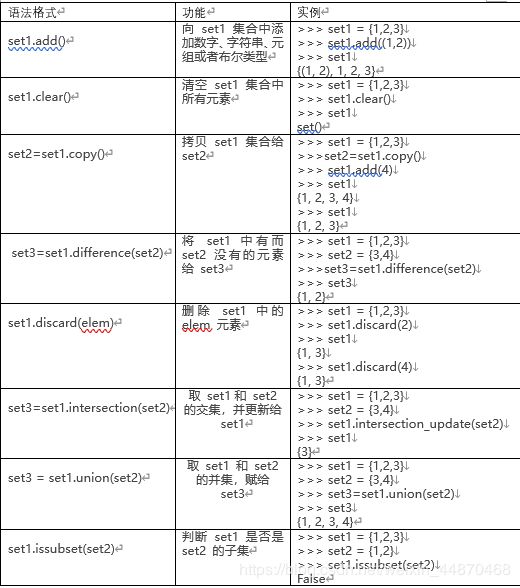
集合常用方法:
>> dir(set)[‘add’, ‘clear’, ‘copy’, ‘difference’, ‘discard’, ‘intersection’,‘isdisjoint’, ‘issubset’, ‘issuperset’, ‘pop’, ‘remove’,‘union’,‘update’]
字典
是一种无序的、可变的序列,它的元素以“键值对(key-value)”的形式存储
创建字典
1、使用 { } 创建
dictname = {‘key’:‘v1’, ‘key2’:‘v2’, …, ‘keyn’:‘vn’} #各个键必须唯一,不能重复。
2、通过 dict() 映射函数创建
a = dict(str1=value1, str2=value2…) #str 表示字符串类型的键,value表示键对应的值,字符串不能带引号。
demo = [(‘two’,2), (‘one’,1), (‘three’,3)] #第一个元素作为键,第二个元素作为值。
字典中各元素的键都只能是字符串、元组或数字,不能是列表。列表是可变的,不能作为键。
3、通过 fromkeys() 方法创建
dictname = dict.fromkeys(list,value=None)
例如:
knowledge = {‘语文’, ‘数学’, ‘英语’}
scores = dict.fromkeys(knowledge, 60)
print(scores)
运行结果为:
{‘语文’: 60, ‘英语’: 60, ‘数学’: 60}
访问字典
1、通过键来访问对应的值,是无序的,不能像列表和元组那样,采用下标或切片的方式访问元素。
dictname[key]
键必须是存在的,否则会抛出异常。
2、get() 方法,指定的键不存在时,不会抛出异常
dictname.get(key[,default])
default 用于指定要查询的键不存在时,此方法返回的默认值,如果不手动指定,会返回 None。
删除字典
del 关键字
a = dict(two=0.65, one=88, three=100, four=-59)
del a
添加键值对
直接给不存在的 key 赋值
dictname[key] = value
修改键值对
键的名字不能被修改,我们只能修改值
a = {‘数学’: 95, ‘语文’: 89, ‘英语’: 90}
a[‘语文’] = 100
删除键值对
使用 del 语句
a = {‘数学’: 95, ‘语文’: 89, ‘英语’: 90}
del a[‘语文’]
字典常用方法:
>> dir(dict)[‘clear’, ‘copy’, ‘fromkeys’, ‘get’, ‘items’, ‘keys’, ‘pop’, ‘popitem’, ‘setdefault’, ‘update’, ‘values’]
keys() 方法用于返回字典中的键 ;values() 方法用于返回字典中键对应的值 ;items() 用于返回字典中键值对 。
scores = {‘数学’: 95, ‘语文’: 89, ‘英语’: 90}
print(scores.keys())
print(scores.values())
print(scores.items())
运行结果:
dict_keys([‘数学’, ‘语文’, ‘英语’])
dict_values([95, 89, 90])
dict_items([(‘数学’, 95), (‘语文’, 89), (‘英语’, 90)])
注意:keys()、values() 和 items() 返回值的类型分别为 dict_keys、dict_values 和 dict_items。
copy() 方法拷贝一个字典,有深拷贝,也有浅拷贝。若有个键对应的值为列表,列表可变,对其做浅拷贝,即b 中的 [1,2,3] 的值不是自己独有,而是和 a 共有。
a = {‘one’: 1, ‘two’: 2, ‘three’: [1,2,3]}
b = a.copy()
update() 方法用一个字典的键值对更新己有的字典,pop() 用来删除指定的键值对,而 popitem() 用来随机删除一个键值对
dictname.update({‘one’:4.5, ‘four’: 9.3})
dictname.pop(key)
dictname.popitem()
setdefault() 方法用来返回某个 key 对应的 value, key 存在,为key 对应的 value,此时指定新值也不变;key 不存在,为默认defaultvalue,不写的话是 None
a = {‘数学’: 95, ‘语文’: 89, ‘英语’: 90}
a.setdefault(‘物理’, 94) #“物理”不存在,指定默认值94
a.setdefault(‘化学’) #“化学”不存在,无指定值,为None