对话智能新高度:百度发布超大规模开放域对话生成网络PLATO-2

近日,百度发布对话生成网络 PLATO-2,宣布在开放域对话生成模型上迎来重要进展。PLATO-2 承袭 PLATO 隐变量进行回复多样化生成特性,模型参数高达 16 亿,涵盖中英文版本,可就开放域话题深度畅聊。实验结果显示,PLATO-2 中英文对话效果已超越谷歌 Meena、微软小冰和 Facebook Blender 等先进模型。
百度 NLP 于去年 10 月预公布了通用领域的对话生成预训练模型 PLATO,近期在 ACL 2020 上展示。最近,百度又新发布了超大规模模型 PLATO-2。
PLATO-2 承袭了 PLATO 隐变量进行回复多样化生成的特性,模型参数规模上升到了 16 亿。PLATO-2 包括中英文版本,能够就开放域话题进行流畅深入的聊天。据公开数据,其效果超越了 Google 于今年 2 月份发布的 Meena (26 亿参数)和 Facebook AI Research 于今年 4 月份发布的 Blender (27 亿,最高 94 亿参数)的效果。在中文上更是达到了全新高度。
论文名称:
PLATO-2:Towards Building an Open-Domain Chatbot via Curriculum Learning
论文地址:
https://arxiv.org/abs/2006.16779
GitHub地址:
https://github.com/PaddlePaddle/Knover
PLATO-2中文对话效果演示
引言
传统对话系统需求大量的人工编码,通常只能解决领域内的问题。随着深度学习的普及和不断发展,端到端的开放域对话系统效果也在稳步提升。基于大量语料和超大规模模型的预训练开放域对话生成技术近些年取得了非常多的进展。如微软发布的 DialoGPT, Google 发布的 Meena, Facebook 发布的 Blender 等,依托数亿到数十亿级级别参数的 Transformer 模型,以及数亿到数十亿的语料训练模型,模型能模拟人产生和人类非常相近的对话。
对话中存在 “一对多” 问题,也就是同样的对话语境下,可以有多种不同的回复。这些不同的回复,除了与上下文相关,也和背景知识相关。这些背景知识包括个人属性(性别年龄,画像等等)、生活常识、相关知识、价值观和态度(如认同 / 不认同一个观念)、对话发生的场景信息,对话人情绪状态意图等等(图 1)。然而这些背景知识往往非常难获取,这就给对话系统训练带来非常大的噪音。一般的 Encoder-Decoder 神经网络不管有多么复杂,仍然是一个 “一对一” 的函数,如果直接使用,就很容易产生诸如 “哈哈”,“不知道” 之类的安全回复。

图 1 对话系统难点:对话语料下面的丰富隐藏信息
在百度去年发布的 PLATO 模型,和微软近期发布的 OPTIMUS 模型中,都提到了利用隐变量(Latent Space)来建模这种不可见的多样性的方法。而百度 PLATO 模型更是独特采用了离散隐变量的方式来建模,且采用了多样化生成 + 合适度判断的方式,其中合适度判断用于回复筛选(Response Selection)。PLATO 在 Persona-Chat, Daily Dialogue 和 DSTC7-AVSD 三个不同类型的公开数据集上获得了 SOTA 的效果。
PLATO-2 介绍
这次公布的 PLATO-2, 是在 PLATO 工作基础上的进一步扩展。PLATO 使用了 12 层 Transformer 作为基础,参数为 1.1 亿。PLATO-2 通过扩展网络,增加训练数据集,将网络扩展到 16 亿参数。考虑到精细化的引入隐变量的网络训练,计算消耗很大,PLATO-2 采取了课程学习的方法,逐步优化参数,加快训练效率。
PLATO-2 模型结构
和 DialoGPT 单向网络,以及 Meena 和 Blender 使用的 Encoder-Decoder 结构不同,PLATO-2 使用了 Unified Network 结构,针对上文部分使用双向 Attention, 回复部分使用单向 Attention,两者共享网络参数,只是 Attention Mask 进行了灵活设计。这种设定经过各项任务的反复验证,发现在同等规模参数量的情况下具有最佳的性价比。同时,PLATO-2 采用了 GPT-2 的前置正则化层的方式,以更好适应大规模训练的需求。
此外,PLATO-2 承袭了 PLATO 结构, 包括三个逻辑模块,Generation, Recognition 和 Response Selection,如图 2 右边所示。其中 Recognition 网络用于在训练过程中识别隐变量, Generation 则能够根据不同隐变量来生成回复(蓝色部分)。Response Selection 承担从不同隐变量生成的回复中,选择合适度最好的回复,因此也可以认为是一种评估(Evaluation)模型(橙色部分)。
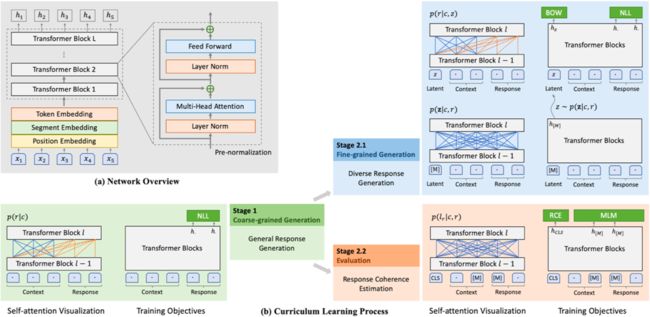
图 2 PLATO-2 模型结构简图
PLATO-2 训练方法
PLATO-2 采用了课程学习方法。因为带隐变量的模型需要同时训练三个不同模块,其训练成本很大,因此,第一步,PLATO-2 先训练了不含隐变量的模型。该模型进行的是简化的 “一对一” 建模,容易生成安全回复。第二步,在前一步模型基础上,添加上隐变量,然后同时训练 Generation + Recognition 和 Response Selection 两个不同模型。其中,Response Selection 模型在合适度预测的基础上,还添加了 Masked Language Model 作为辅助任务,以强化模型对语义的理解。
PLATO-2 效果
PLATO-2 包含中英文两部分模型。其中,中文模型在 12 亿中文开放域多轮对话数据集上进行训练,而英文模型则在 7 亿英文开放域多轮数据集上训练。PLATO-2 训练耗费了 64 张英伟达 V100 卡共 3 周的时间,依托了百度飞桨强大并行能力,包括 Fleet 并行库和 Recompute 等扩展显存的方式。单个 Batch 包含 52 万 Token,训练过程中约进行了 30 万次梯度回传。
为了全面对比 PLATO-2 和其他基线的效果,PLATO-2 的论文进行了静态和动态评估。其中,静态评估是利用现有对话上文,要求模型预测一句下文,人工评估对话的合适度。而动态评估中,由于中文的对比模型没有开放 API 接口,中英文采用了不同的评估数据收集方式。英文动态评估采用了两个模型进行相互对话(Self-Chat)的形式,通过人工来评估效果。中文则采用了人机对话的形式。中英文动态评估中,都是先给定一句起始话题(第一句对话),然后进行多轮交互,最后对这些多轮对话进行评估。


图 3 PLATO-2 动态评估效果
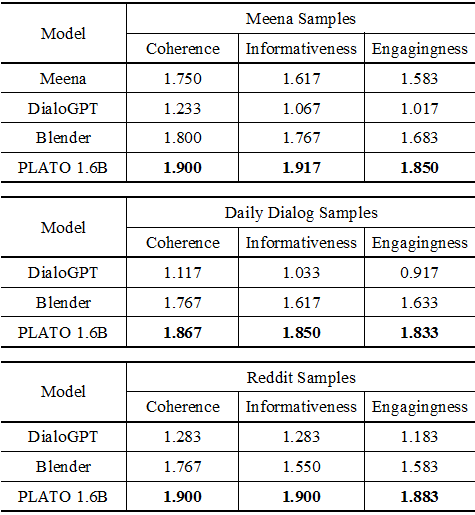
图 4 PLATO-2 静态评估效果
从结果上看,PLATO-2 在动态(图 3)或者静态(图 4)评估中,均明显超越了 DialoGPT、Meena 和 Blender,在中文上和微软小冰拉开了极大的差距。这意味着,PLATO-2 的对话智能达到了全新的领域。
此外,文章也放出了 PLATO-2 一些中文(图 5)和英文(图 6)对话的演示。从对话效果上看,PLATO-2 和之前的模型,包括 Meena 和 Blender 有非常明显的区别。一方面 PLATO-2 在对话内容丰富度上提升明显,另一方面,PLATO-2 能够就一个话题深入聊天并扩展到相关话题。而之前的最佳模型 Blender,则非常频繁地转换话题,并且在每个话题上聊得相对较浅。

图 5 PLATO-2 中文对话演示

图 6 PLATO-2 英文对话演示和 Blender 使用相同对话种子对比
总结
PLATO-2 基于全新的隐空间技术和 Transformer 模型,从内容丰富,连贯性上都达到了新的高度。期待 PLATO-2 能为智能对话开辟全新的领域。此外, PLATO-2 的英文模型和代码即将陆续在 Github 开放,而中文模型也有望于不久的将来,开放接口提供相关服务。对智能对话感兴趣的小伙伴一定不能错过。
如在使用过程中有问题,可加入飞桨官方QQ群交流:1108045677
如果您想详细了解更多飞轮的相关内容,请参见以下文档。
官网地址:
https://www.paddlepaddle.org.cn
飞轮开源框架项目地址:
的GitHub:
https://github.com/PaddlePaddle/Paddle
Gitee:
https://gitee.com/paddlepaddle/Paddle
END
