PF_RING简介
1、PF_RING简介
PF_RING是Luca研究出来的基于Linux内核级的高效数据包捕获技术。简单来说PF_RING 是一个高速数据包捕获库,通过它可以实现将通用 PC 计算机变成一个有效且便宜的网络测量工具箱,进行数据包和现网流量的分析和操作。同时支持调用用户级别的API来创建更有效的应用程序。
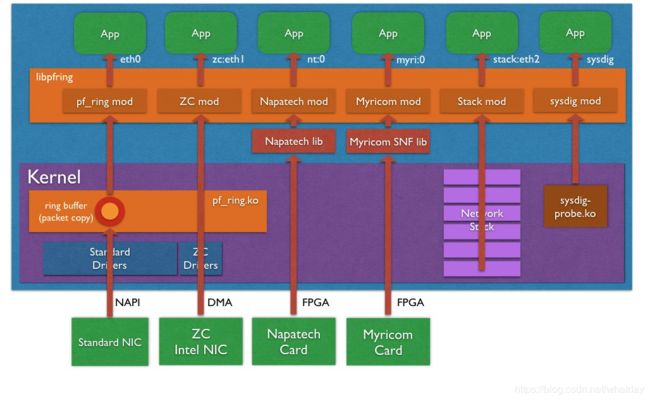
2、PF_RING的优点
现在我们知道PF_RING是拥有一套完整开发接口的高速数据包捕捉库,与我们熟知的libpcap十分相似,但其性能要优于libpcap。关于libpcap的实现机制可以参考 libpcap实现机制及接口函数 https://blog.csdn.net/whatday/article/details/89241551
问题
- 在传统数据包捕获的过程中, CPU的多数时间都被用在把网卡接收到的数据包经过内核的数据结构队列发送到用户空间的过程中。也就是说是从网卡-->内核, 再从内核-->用户空间,这两个步骤,花去了大量CPU时间,从而导致没有其他时间用来进行数据包的进一步处理。
在传输过程中sk_buff结构的多次拷贝,以及涉及用户空间和内核空间的反复系统调用极大的限制了接收报文的效率,尤其是对小报文的接收影响更为明显。
解决方案
** PF_RING提出的核心解决方案便是减少报文在传输过程中的拷贝次数**。由下图我们可以直观的看到不同技术下对数据拷贝的优化是不同的。接下来将围绕这张图的实现路径解释PF_RING和PF_RING ZC库的实现机制。

libpcap、PF_RING、PF_RING ZC方案对比
网卡接收报文的前面的流程就是 libpcap实现机制及接口函数 https://blog.csdn.net/whatday/article/details/89241551 中讲解的NAPI,主要的不同体现在报文在内核空间与用户空间的传递。
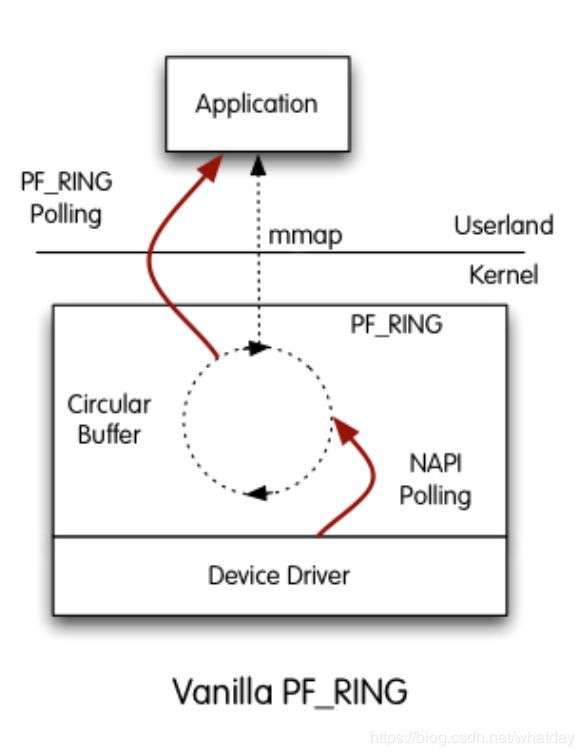
PF_RING noZC
1、PF_RING socket 针对轮询机制的不足,在轮询机制的基础上提出一种新的包捕获套接字模型,基于环形缓冲区的新的套接字
PF_RING
2、每创建一个PF _RING套接字便分配一个环形缓冲区,当这个套接字结束时释放这个缓冲区
3、PF_RING套接字绑定到某一网卡上时,这个网卡在套接字结束之前处于制度状态,当数据包到达网卡时,将其放入到环形缓冲区。如果缓冲区已经满,则将其丢弃。
4、用户空间可以直接访问这个环形缓冲区中的数据
5、当有新的数据包到来的时候,可以直接覆盖掉已经被用户空间读取过的那个数据包的空间
环形缓冲区示意图
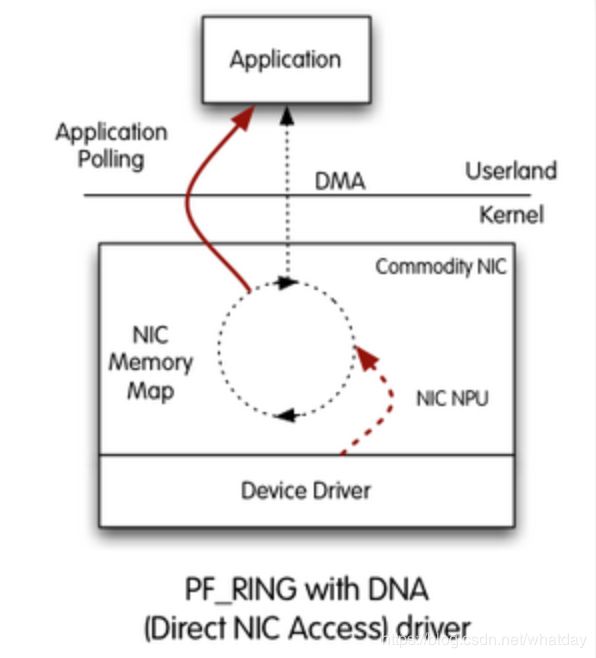
PF_RING ZC
- PF_RING ZC 实现了PF_RING™ DNA(Direct NIC Access 直接网卡访问)技术。是一种映射网卡内存和寄存器到用户态的方法。
- 因此除了由网卡的网络处理单元完成DMA传输之外,没有任何额外的数据包复制,进一步节省了一次数据拷贝操作
- 这将性能更好,因为CPU周期的仅用于操作数据包,而不是把数据包从网卡挪走。
其缺点是,只有一个应用可以在某个时间打开DMA ring(请注意,现在的网卡可以具有多个RX / TX队列,从而就可以在每个队列上同时一个应用程序),换而言之,用户态的多个应用需要彼此沟通才能分发数据包。
PE_RING ZC
用户空间创建PF_RING套接字时
fd = socket(PF_RING, SOCK_RAW, htons(ETH_P_ALL));
和基于PF_PACKET套接字的libpcap不同的是,PF_RING机制更为灵活:
- 1.PF_RING采用mmap的方式将网络裸数据放在一个用户态可以直接access的地方,而不是通过socket read/write机制的内存拷贝;
- 2.PF_RING支持下面1到3三种方式将裸数据放到mmap到用户态的环形缓冲区以及4的DNA方式:
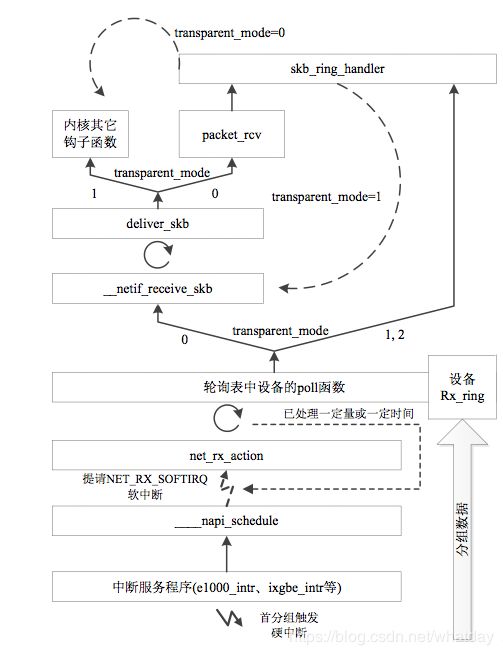
- 1.按照PACKET套接字的方式从netif_receive_skb函数中抓取数据包,这是一种和PACKET套接字兼容的方式,所不同的是数据包不再通过socket IO进入用户态,而是通过mmap;(transparent_mode 0)
- 2.直接在NAPI层次将数据包置入到所谓的环形缓冲区,同时NAPI Polling到skb对列,对于这两个路径中的第一个而言,这是一种比2.1介绍的方式更加有效的方式,因为减少了数据包在内核路径的处理长度,但是要求网卡支持NAPI以及PF_RING接口(一般而言,NAPI会将数据包Polling到一个skb队列)。(transparent_mode 1)
- 3.和2相同,只是不再执行NAPI Polling。这就意味着,数据包将不会进入内核,而是直接被mmap到了用户态,这特别适合于用户态的完全处理而不仅仅是网络审计,既然内核不需要处理网络数据了,那么CPU将被节省下来用于用户态的网络处理。这可能会将内核串行的网络处理变为用户态并行的处理。(transparent_mode 2)
- 4.这是一种更猛的方式,唤作DNA支持的模式,直接绕过内核协议栈的所有路径,也就是说直接在网卡的芯片中将数据包传输到(DMA的方式)所谓环形缓冲区,内核将看不到任何数据包,这种方式和Intel的万兆猛卡结合将是多么令人激动的事啊;(DNA技术)

E33B49AA-8CBA-4146-9AB7-A38EB076B11B.png
以上便是我们在文档中见到的transparent_mode。对于transparent_mode为0的情况,内核会通过net_if_recv_skb回调packet_rcv函数实现数据接收,所以当向系统内核插入PF_RING模块时在内核注册了packet_rcv钩子函数,使用通用的网卡驱动便可以实现向PF_RING传递报文。而对于transparent_mode为1和2的模式,则是需要使用PF_RING特殊定制的网卡驱动,并在网卡驱动中直接调用注册的包处理函数,将报文传递给PF_RING。
屏幕快照 2016-12-16 下午4.02.38.png
transparent_mode是对skb_ring_handler之前的包处理路径进行优化,
quick_mode是对skb_ring_handler之后的包处理过程进行优化
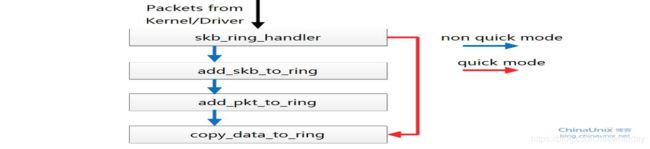
quick_mode
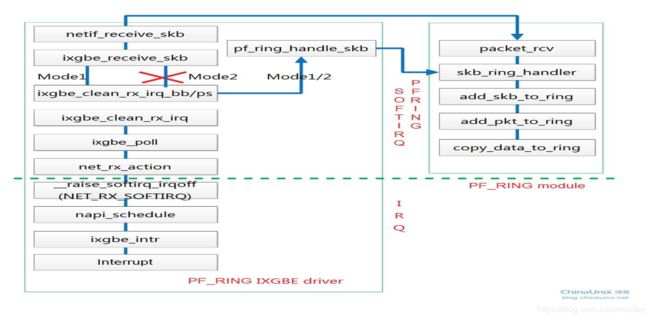
屏幕快照 2016-12-15 下午3.06.52.png
PF_RING的背后
很多人都只是认为PF_RING只是一个高性能的抓包机制,提供本机的数据包镜像分析,实现网络审计,这只是按照传统的思路来解释的。更进一步,PF_RING机制颠覆了网络中间节点解释数据包的方式。按照传统的观念,中间网络节点只能按照协议栈的层次一层一层地解析数据包,所谓路由器是三层设备,交换机是二层设备,防火墙分为二层防火墙和三层防火墙...使用PF_RING的设备,它可以将数据包直接从网卡的芯片DMA到你机器上的内存,仅此而已,然后你通过一个应用程序而不是内核协议栈来处理数据包,至于说你的应用程序怎么处置数据包,我来列举几个:
1.深度解析数据包,按照各种你可以想到的粒度来解析会话,然后记录审计信息;
2.提供高性能的入侵检测功能;
3.转发数据包,按照路由器的方式。但是不再仅仅通过查询路由表的方式进行IP路由,而是可以通过各种各样的方式,转发表完全由你自己定义,比如实现一个通用的SDN流表;
4.根据上面第2点的含义,你可以决定哪些包被丢弃,这就是一个高性能的防火墙。
相比协议栈的串行解决方案,使用PF_RING是一个更加高效的方案,不但高效,而且灵活。如果你拥有多核心的处理器,你甚至可以可以在用户态并行处理数据包的各个层信息