NVIDIA GPUs上深度学习推荐模型的优化
NVIDIA GPUs上深度学习推荐模型的优化
Optimizing the Deep Learning Recommendation Model on NVIDIA GPUs
推荐系统帮助人在成倍增长的选项中找到想要的东西。是在许多在线平台上推动用户参与的关键组件。
随着工业数据集规模的迅速增长,利用大量训练数据的深度学习推荐模型(deep learning,DL)已经开始显示出其相对于传统方法的优势。现有的基于DL的推荐系统模型包括广度和深度模型、深度学习推荐模型(DLRM)、神经协同滤波(NCF)、变分自编码(VAE)和BERT4Rec等。
大型推荐系统解决方案在性能上面临着多重挑战:庞大的数据集、复杂的数据预处理和特征工程管道,以及大量的重复实验。为了满足大规模DL推荐系统训练和推理的计算需求,GPU推荐解决方案旨在提供快速的特征工程和高训练吞吐量(支持快速实验和生产再训练),以及低延迟、高吞吐量的推理。
在这篇文章中,讨论了DLRM的参考实现,是NVIDIA GPU加速DL模型组合的一部分。涵盖了许多不同领域的网络体系结构和应用,包括图像、文本和语音分析以及推荐系统。通过DLRM,系统地解决了上述挑战。
对于海量数据集的数据预处理任务,引入了新的Spark-on-GPU工具。通过NVIDIA Tensor Core GPU上的自动混合精度训练、优化的数据加载程序和定制的嵌入式CUDA内核,在单个Tesla V100 GPU上,只需44分钟就可以在Criteo Terabyte数据集上训练DLRM模型,而在96-CPU线程上则需要36.5小时。
还演示了如何使用NVIDIA Triton推理服务器将经过训练的DLRM模型部署到生产环境中。
DLRM overview
DLRM是一个基于DL的推荐模型,由Facebook research引入。与其基于DL的方法一样,DLRM被设计为同时使用推荐系统训练数据中通常存在的分类输入和数值输入。图1显示了模型架构。为了处理类别数据,嵌入层将每个类别映射到一个密集的表示,然后再将其输入多层感知器(MLP)。数值特征可以直接输入MLP。
在下一个层次上,通过在所有嵌入向量对和处理的稠密特征之间取点积,显式地计算不同特征的二阶交互作用。这些成对交互被输入到顶级MLP中,以计算用户和项目对之间交互的可能性。
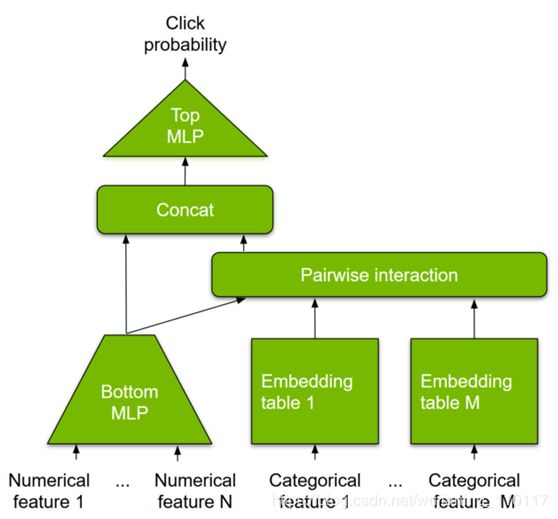
Figure 1. DLRM architecture.
与其基于DL的推荐方法相比,DLRM在两个方面有所不同。首先,显式地计算特征交互,同时将交互顺序限制为成对交互。
其次,DLRM将每个嵌入的特征向量(对应于分类特征)视为一个单元,而其方法(如Deep和Cross)将特征向量中的每个元素视为一个新单元,该单元应产生不同的交叉项。这些设计选择有助于降低计算/内存成本,同时保持具有竞争力的准确性。
Criteo dataset
Criteo-Terabyte-click-logs公共数据集是推荐任务中最大的公共数据集之一,提供了对真实企业数据规模的难得一瞥。包含约1.3TB的未压缩点击日志,包含超过40亿个24天的样本,可用于训练预测广告点击率的推荐系统模型。
这是公共DL数据集中的一个大型数据集。然而,真实的数据集可能要大一两个数量级。企业尽量利用尽可能多的历史数据,因为这通常转化为更好的准确性。
在本文中,使用Criteo Terabyte数据集来演示GPU优化的DLRM训练管道的效率。此数据集中的每条记录都包含40个值:一个表示单击(值1)或不单击(值0)的标签、13个数值特征值和26个分类特征值。特性是匿名的,分类值是散列的,以确保隐私。
End-to-end training pipeline
- 提供了一个关于Criteo Terabyte数据的端到端训练管道,帮助从几个简单的步骤开始。
-
- copy存储库。Clone the repository.
git clone https://github.com/NVIDIA/DeepLearningExamples
cd DeepLearningExamples/PyTorch/Recommendation/DLRM
- 构建DLRM Docker容器 Build a DLRM Docker container
docker build . -t nvidia_dlrm_pyt
在NVIDIA NGC容器中启动交互式会话以运行预处理/训练和推理。DLRM PyTorch容器可以通过以下方式启动:
mkdir -p data
docker run --runtime=nvidia -it --rm --ipc=host -v ${PWD}/data:/data nvidia_dlrm_pyt bash
- 在Docker交互会话中,下载并预处理CriteoTB数据集。
在下载数据之前,必须签订并同意Criteo Terabyte数据集的条款和条件。该数据集包含24个压缩文件,需要大约1TB的磁盘存储空间来存储数据,另外2 TB的磁盘存储空间来立即得到结果。
如果不想在24个文件的完整集合上进行实验,可以下载一个子集文件并修改数据预处理脚本以仅处理这些文件。
cd preproc && ./prepare_dataset.sh && cd -
- Start training.
python -m dlrm.scripts.main --mode train --dataset /data --save_checkpoint_path model.pt
接下来,将讨论这个训练管道的几个细节。
Data preprocessing and transformation with Spark
最初的Facebook DLRM代码库附带了一个数据预处理实用程序来预处理数据。
对于数值特征,数据预处理步骤包括用0填充缺失值和归一化(将值移动到>=1并取自然对数)。
对于分类特征,预处理将哈希值转换为从0开始的连续整数范围。
这个基于NumPy的数据实用程序运行在一个CPU线程上,需要大约5.5天来转换整个Criteo Terabyte数据集。
使用Spark改进了数据预处理过程,以充分利用所有可用的CPU线程。在DLRM Docker映像中,使用了Spark 2.4.5,启动了一个独立的Spark集群。这将显著提高数据预处理速度,并随着可用CPU内核数的增加而扩展。Spark以Parquet格式输出转换后的数据。最后,将Spark 数据文件转换成一种二进制格式,专门为Criteo数据集设计。
在一个具有96核和768GB RAM的AWS r5d.24xl实例上,整个过程需要9.45小时(不带频率上限)和2.87小时(带频率上限),以便将出现次数少于15次的所有罕见类别映射到一个特殊类别)。
Spark可以进一步提高。为DLRM引入了一个SparkGPU插件。图2显示了GPU上Spark的数据预处理时间改进。使用8v100 32-gbgpu,与等效的Spark CPU管道相比,可以将处理时间进一步加快43倍。Spark GPU插件目前正处于早期访问阶段,供选定的开发人员使用。邀请注册对Spark GPU插件的兴趣。

Figure 2: Spark performance improvement on GPU vs CPU. CPU model: AWS r5d.24xl, 96 cores, 768 GB RAM. Bars represent speedup factor for GPU vs. CPU. The higher, the better.
预处理脚本是为Criteo Terabyte数据集设计的,但是应该可以与任何其具有相同格式的数据集一起使用。数据应该分成文本文件。这些文本文件的每一行都应该包含一个训练示例。示例应包含多个字段,这些字段由制表符分隔:
第一个字段是标签。正数用1,负数用0。
接下来的N个标记应该包含由制表符分隔的数字特征。
下一个M标记应该包含由制表符分隔的散列分类特性。
必须修改数据参数,例如每个分类特征的唯一值的数目和predoc/spark_data中的数字特征的preproc/spark_data_utils.py,以及预印/运行中的spark配置preproc/run_spark.sh.
Data loading
采用二进制数据格式,本质上是对加载速度特别快的NumPy数组的序列化。这与重叠数据加载和host2设备传输以及神经网络计算相结合,使能够实现高GPU利用率。
Embedding tables and custom embedding kernel
基于DL的推荐模型通常太大,无法装入单个设备内存。这主要是由于嵌入表的绝对大小,与类别特征的基数和潜在空间的维数(嵌入表中的行数和列数)成正比。
采用了一种常见的做法,将所有罕见的分类值映射到一个特殊的“缺失类别”值(这里,在数据集中出现次数少于15次的任何类别都被视为缺失类别)。这减少了嵌入表的大小,并避免了嵌入那些在随机初始化的训练过程中无法充分更新的条目。
与其计算密集型层不同,嵌入层受内存带宽限制。与当前最先进的商用CPU相比,GPU具有非常高的带宽内存。为了有效地使用可用的内存带宽,将所有分类嵌入表合并到一个表中,并使用自定义内核执行嵌入查找。内核使用矢量化的加载存储指令以获得最佳性能。
Training with automatic mixed precision
混合精度是指在计算过程中使用多个数值精度,如FP32 FP16。
从Volta架构开始,NVIDIA gpu配备了张量核、执行矩阵乘法的专用计算单元、线性(也称为完全连接)和卷积层的构建块。NVIDIA NGC PyTorch容器中提供的自动混合精度(AMP)功能使混合精度训练只需对代码库进行最小的更改。在引擎启动下,AMP是由NVIDIA APEX库提供的,通过只更改脚本的三行来实现混合精度训练。
在对NVIDIA DL模型库中的各种模型和体系结构的实验中,AMP通常提供1.3倍到3倍或更多的加速。对于DLRM,AMP提供了比FP32训练快2.37倍的速度。使用V100 32GB的GPU,DLRM可以在44分钟内在Criteo Terabyte数据集上训练一个epoch,收敛到AUC值0.8036。
End-to-end inference pipeline
推荐系统推理包括确定查询用户最有可能与之交互的项的有序列表。
对于有数百万到数亿个项目可供选择的大型商业数据库(如广告或应用程序),通常执行项目检索过程以将项目数量减少到更易于管理的数量,例如几百到几千个。这些方法包括计算效率高的算法,例如基于用户偏好和业务规则的近似邻域搜索或过滤。在此基础上,调用一个DL推荐模型来重新排列条目。得分最高的将呈现给用户。这个过程如图3所示。

Figure 3: Recommender systems inference process.
如所见,对于每个查询用户,要评分的用户项对的数量可以大到几千个。这给推荐系统推理服务器带来了沉重的负担。服务器必须处理高吞吐量以同时服务多个用户,同时以低延迟运行以满足在线商务引擎的严格延迟阈值。
NVIDIA Triton推理服务器提供了一个为NVIDIA gpu优化的云推理解决方案。服务器使用HTTP或GRPC端点提供推理服务,允许远程客户端请求对服务器管理的任何模型进行推理。Triton服务器自动管理和使用所有可用的GPU。
下一节将介绍如何准备DLRM模型,以便与Triton服务器进行推理,并了解Triton服务器的性能。
Prepare the model for inference
Triton服务器可以为TorchScript和ONNX模型以及其模型提供服务。提供了一个导出工具来准备经过训练的DLRM模型,以便进行生产推断。
使用TorchScript
可以使用以下任一方法将预处理的PyTorchDLRM模型导出到TorchScript模型torch.jit.script脚本或者torch.jit.trace使用以下命令:
python triton/deployer.py --ts-script --triton-max-batch-size 65536 --model_checkpoint dlrm.pt --save-dir /repository [other optional parameters]
这将从名为dlrm.pt公司,使用torch.jit.script脚本最大可维护批量为65536。
使用ONNX
类似地,可以使用以下命令创建ONNX生产就绪模型:
python triton/deployer.py --onnx --triton-max-batch-size 65536 --model_checkpoint dlrm.pt --save-dir /repository [other optional parameters]
导出工具的结果是一个打包的目录/存储库,Triton服务器可以很容易地利用。
设置Triton推理服务器
在模型准备就绪的情况下,Triton服务器可以通过以下步骤进行设置。
使用以下命令下载Triton推理Docker图像,其中是服务器版本,例如20.02-py3:
docker pull nvcr.io/nvidia/tensorrtserver:
启动Triton服务器,指向在上一步中创建的导出模型目录:
docker run --network=host -v /repository:/models nvcr.io/nvidia/tensorrtserver: trtserver --model-store=/models
Use the Triton Server perf_client tool to measure inference performance
Triton服务器配有一个方便的性能客户端工具perf_客户端。该工具使用多个并行线程,使用合成数据或实际数据对推理服务器进行压力测试。可以使用以下命令调用:
/workspace/install/bin/perf_client --max-threads 10 -m dlrm-onnx-16 -x 1 -p 5000 -v -i gRPC -u localhost:8001 -b 4096 -l 5000 --concurrency-range 1 --input-data /location/for/perfdata -f result.csv
使用perf客户机,收集了延迟和吞吐量数据,以填充本文后面显示的数字。
Triton服务器批处理策略
默认情况下,导出的模型与Triton服务器静态批处理策略一起部署:每个请求都会立即完成。另一方面,动态批处理是推理服务器的一个特性,允许服务器组合推理请求,以便动态创建批处理。这将导致批量推理请求的吞吐量增加。
同时对一批输入进行推理,这对gpu尤其重要,因为可以大大提高推理吞吐量。在许多用例中,单个推理请求没有批处理,也没有从批处理的吞吐量效益中获益。
对于具有严格延迟阈值的在线应用程序,Triton服务器是可配置的,因此具有动态批处理的队列时间被限制在上限,同时形成尽可能大的批处理以最大化吞吐量。在模型目录中,有一个名为config.pbtxt可以配置一个额外的批处理选项,如下所示:
ddynamic_batching { preferred_batch_size: [ 65536 ] max_queue_delay_microseconds: 7000}
静态批处理吞吐量 ‘
图4显示了Triton服务器在不同批量大小下的吞吐量。对于推荐系统,大批量是最感兴趣的。对于每个查询用户,在一个项目重新排序的请求中会发送数千个项目。与80线程CPU推断相比,Tesla V100 32-GB GPU的吞吐量提高了20倍。可以看到,GPU的吞吐量在大约8K的批处理大小时开始饱和。
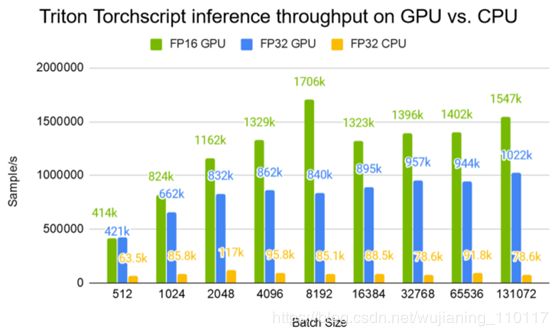
Figure 4. Triton Server TorchScript inference throughput on GPU vs. CPU. GPU: Tesla V100 32GB. CPU: 2x Intel® Xeon® E5-2698 v4 @ 2.20GHz (80 threads).
图5显示了与CPU相比,GPU上的Triton TorchScript推理延迟。在8192的批处理大小下,V100 32-GB GPU比80线程CPU推断减少了19倍的延迟。

Figure 5. Triton TorchScript inference latency on GPU vs. CPU. GPU: Tesla V100 32 GB. CPU: 2x Intel® Xeon® E5-2698 v4 @ 2.20GHz (80 threads).
动态批处理吞吐量
与静态批处理相比,使用动态批处理可以进一步提高吞吐量。在这个实验中,将每个用户的请求批量大小设置为1024,Triton最大和首选批量大小设置为65536。图5显示了不同请求并发级别的延迟和吞吐量。延迟分为客户端发送/接收时间、服务器队列和计算时间、网络、服务器发送/接收时间。
并发级别是perf_client的一个参数,允许控制延迟吞吐量权衡。默认情况下,perf_client在请求并发性为1时使用模型上可能的最低负载来测量模型的延迟和吞吐量。为此,perf_client向服务器发送一个推断请求并等待响应。当接收到该响应时,perf_client立即发送另一个请求,然后重复此过程。
在N的更高并发级别上,perf_client立即一个接一个地触发请求,而不等待前一个请求得到满足,同时在任何时候最多保持N个未完成的请求。
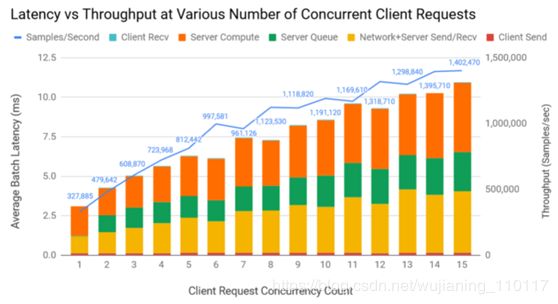
Figure 6. Latency vs. throughput at varying number of concurrent client requests on Tesla V100 32GB GPU. Model: DLRM TorchScript FP16. Maximum Triton batch size: 65536.
图6显示,如果延迟上限为10毫秒,则可以达到每秒1318710个样本的吞吐量。这意味着在一个V100 GPU上每秒可以为1288个用户提供服务,每个用户在10毫秒的延迟限制内,假设希望为每个用户评分1024项,并且用户请求在任何10毫秒窗口内以最大12个请求的统一速率出现。
结论
在这篇文章中,经历了一个完整的DLRM管道,从数据准备到培训再到生产推理。GPU优化的DLRM可从NVIDIA deep learning model zoo的/PyTorch/Recommendation/DLRM下获得。提供现成的Docker图像用于训练和推理、数据下载和预处理工具,以及Jupyter演示笔记本,让快速启动和运行。通过导出工具,经过训练的模型可以在一个简单的步骤中为生产推理做好准备。还邀请注册兴趣,以便尽早访问Spark GPU组件。
DLRM是NVIDIA Merlin的一部分,NVIDIA Merlin是一个用于构建基于DL的高性能推荐系统的框架。要了解有关Merlin和更大的生态系统的更多信息,请参阅最近的文章,宣布NVIDIA Merlin:一个用于深度推荐系统的应用程序框架。
诚邀试用最新开发的推荐系统应用工具并从中受益。问题和功能请求有助于指导未来的开发。很高兴看到可以用自己的数据处理这个模型。