HashMap之HashSet和TreeSet
Map
键值对:键值(key)作为索引(不能重复),查询键对应的对象“值”(value,可以重复)
即:一个键对应一个对象,多个键可以对应同一个对象;理解上可以理解为数学中的映射
数学中最简单的例子:|-x|
深入理解:key是用Set来存放的,不可重复;value是用Collection来存放的,可重复---链接--点击打开链接
要求映射中的key是不可变对象;不可变对象是该对象在创建后它的哈希值不会被改变,如果对象的哈希值发生变化,Map对象很可能就定位不到映射的位置了。
键对象和值对象一般理解:只要向集合中添加元素,必须提供一对键对象和值对象,值对象可以是Map类型,形成多级映射
首先是了解HashMap的几个核心成员变量(以下均为jdk源码加以注释)
实例1 核心成员变量
transient Node[] table;
//说明1--HashMap的哈希桶数组,非常重要的存储结构,用于存放表示键值对数据的Node元素。
transient Set> entrySet;
//说明2--HashMap将数据转换成Set的另一种存储形式,这个变量主要用于迭代功能。
transient int size;
//说明3--HashMap中实际存在的Node数量,注意这个数量不等于table的长度,甚至可能大于它,
//因为在table的每个节点上是一个链表(或RBT)结构,可能不止有一个Node元素存在。
transient int modCount;
//说明4--HashMap的数据被修改的次数,这个变量用于迭代过程中的Fail-Fast机制,
//其存在的意义在于保证发生了线程安全问题时,能及时的发现(操作前备份的count和当前modCount不相等)并抛出异常终止操作。
int threshold;
//说明5--HashMap的扩容阈值,在HashMap中存储的Node键值对超过这个数量时,自动扩容容量为原来的二倍。
final float loadFactor;
//说明6--HashMap的负载因子,可计算出当前table长度下的扩容阈值:threshold = loadFactor * table.length。
在HashMap的内部可以看见定义了这样一个内部类
![]()
实例2 Node源码
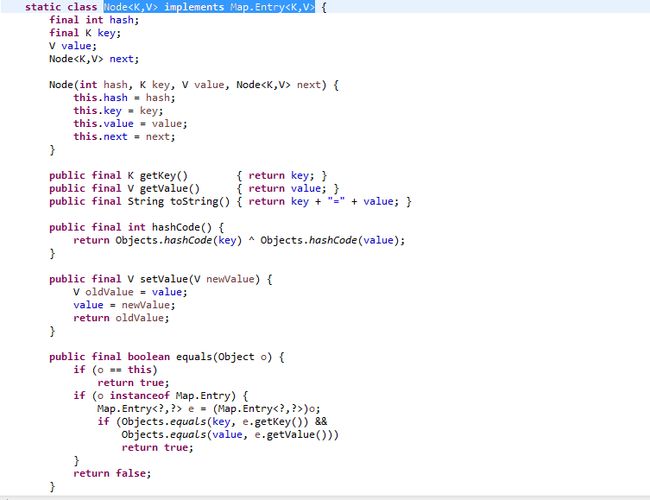
我们大体看一下这个内部类就可以知道,它实现了Map.Entry接口。其内部的变量含义也很明确,hash值、key\value键值对和实现链表和红黑树所需要的指针索引。
实例3 HashMap定义的常量
//说明1---默认的初始容量为16,必须是2的幂次
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
//说明2---最大容量即2的30次方
static final int MAXIMUM_CAPACITY = 1 << 30;
//说明3---默认加载因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
//说明4---当put一个元素时,其链表长度达到8时将链表转换为红黑树
static final int TREEIFY_THRESHOLD = 8;
//说明5---链表长度小于6时,解散红黑树
static final int UNTREEIFY_THRESHOLD = 6;
//说明6---默认的最小的扩容量64,为避免重新扩容冲突,至少为4 * TREEIFY_THRESHOLD=32,即默认初始容量的2倍
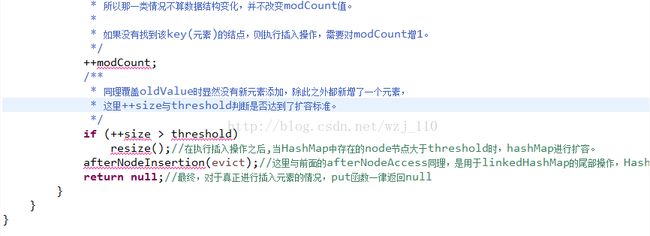
static final int MIN_TREEIFY_CAPACITY = 64;实例4 put源码
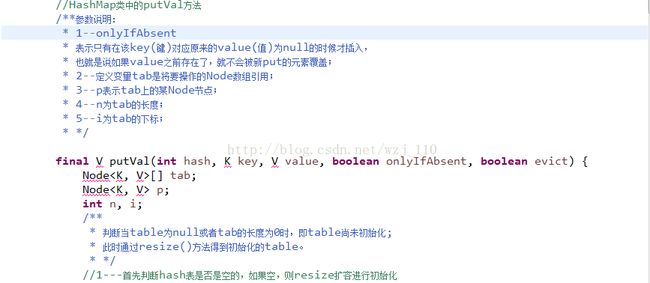
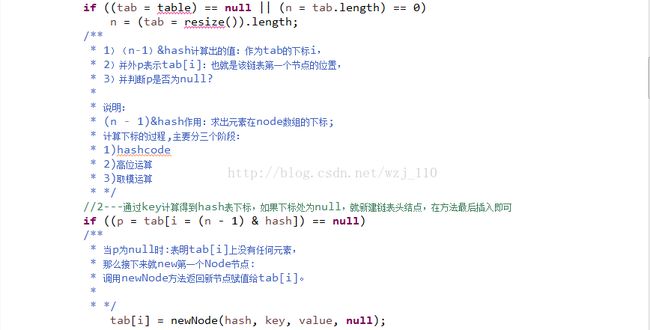

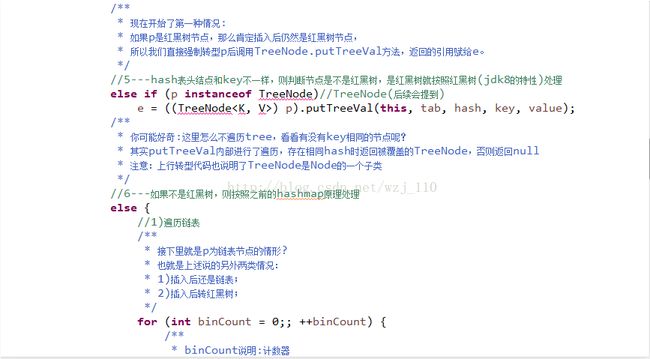



对hash方法说明--源码

源码说明:key.hashCode()计算出key的哈希值,然后将哈希值h右移16位,再与原来的h做异或^运算——这一步是高位运算。
HashCode:散列值,其意义在于类似于进行hashMap等操作时,加快对象比较的速度,进而加快对象搜索的速度。
补充:原来的疑问?比较equals()方法就行了,为什么还要比较hashCode()方法?不是多此一举吗?
hashCode()疑问解答链接--点击打开链接,点击打开链接,点击打开链接,点击打开链接
hashCode()碰撞链接---点击打开链接
高位运算设计思路:设想一下,如果没有高位运算,那么hash值将是一个int型的32位数;而从2的-31次幂到2的31次幂之间,有将近几十亿的空间,如果我们的HashMap的table有这么长,内存早就爆了。所以这个散列值不能直接用来最终的取模运算,而需要先加入高位运算,将高16位和低16位的信息"融合"到一起,也称为"扰动函数"。这样才能保证hash值所有位的数值特征都保存下来而没有遗漏,从而使映射结果尽可能的松散。最后再根据 n-1 与hash值做与操作的取模运算。这里也能看出为什么HashMap要限制table的长度为2的n次幂,因为这样,n-1可以保证二进制展示形式是(以16为例)0000 0000 0000 0000 0000 0000 0000 1111。在做"与"操作时,就等同于截取hash二进制值得后四位数据作为下标。这里也可以看出"扰动函数"的重要性了,如果高位不参与运算,那么高16位的hash特征几乎永远得不到展现,发生hash碰撞的几率就会增大,从而影响性能。
问题1 为什么能保证HashSet集合元素唯一?
当创建一个HashSet集合的对象时,会先调用其构造方法(蓝框标记)看源码1
即:

源码说明:可以看到实际上是创建了一个HashMap类对象,map是HashMap类对象的实例
此时add()添加元素,看对应的源码2

源码说明:其实是调用了HashMap类的map对象的put方法
看HashMap的put()方法的源码3

源码说明:调用了HashMap中的hash()方法和putVal()方法

putVal方法的源码5--上面已近提到过
接源码1--既然创建了HashMap对象,必然要调用相应的构造方法
进入HashMap的构造方法---源码6
链接:点击打开链接