Wayland协议解析 二 Wayland中的数据结构解析
为了更好的学习wayland,我们可以先学习wayland中定义的一些数据结构.因为贯穿wayland的所有东西都是基于这些数据结构.
- 首先介绍wl_array
struct wl_array {
/** Array size */
size_t size;
/** Allocated space */
size_t alloc;
/** Array data */
void *data;
};
Wayland定义的数组数据结构. 其中data保存实际的数据,size保存实际数据的大小,alloc保存当前data总共分配的大小(malloc/realloc分配的大小)。
注意,alloc总是大于size,因为空间总要比保存的数据大才行,另外当往数组里面插入数据的时候,alloc不够大了,
那么就会以当前alloc大小翻倍的大小重新分配内存。因此在进行网络传输的时候,只需要把data里面的数据发送出去即可.
- 然后介绍wl_map
struct wl_map {
struct wl_array client_entries;
struct wl_array server_entries;
uint32_t side;
uint32_t free_list;
};
struct wl_array {
/** Array size */
size_t size;
/** Allocated space */
size_t alloc;
/** Array data */
void *data;
};
union map_entry {
uintptr_t next;
void *data;
};
这个数据结构是wayland的核心,用来保存进程间通信的实际对象指针,并得到对于指针的ID,用于进程间传递。
wl_map结构体存放wayland客户端和服务器端对应的对象。其中:
client_entries: 用wl_array数组保存客户端的对象。(这种情况server_entries不使用)
server_entries:用wl_array数组保存服务器端的对象。(这种情况client_entries不使用)
side:表明当前map保存的是客户端还是服务器端对象(通过这个变量,确定client_entries/server_entries里面保存有对象,并且这个变量只在客户端初始化为WL_MAP_CLIENT_SIDE,在服务器端初始化为WL_MAP_SERVER_SIDE)
free_list:这个变量用来记录当前已经被删除了的对象的存放位置,但是对这个位置做了个处理。((i << 1) | 1 : i代表下标, 也就是指针的最后一位置为1),
然后,这个下标所指的位置的map_entry.next变量记录着下一个被删除的位置(直到为0,free_list初始值为0),形成链表
提示: map的节点是map_entry结构。data保存实际的对象的地址。但是这个地址做了处理(原理上data是指针,编译器为了4字节对齐,最后两位都是0,map利用了这两位。把倒数第二位保存flags的值(0/1),最后一位表示当前对象是否已经被删除了(1表示删除,0表示没删除)),map_entry是个联合体,data成员保存实际的对象指针,而next是在对象被删除的时候,用来保存下一个被删除的对象的下标。
数据保存关系: wl_map保存两个wl_array数组, wl_array保存map_entry联合体的节点元素。
flags: entry->next |= (flags & 0x1) << 1;
deleted: map->free_list = (i << 1) | 1;
wayland协议实现基本决定了,创建对象都是客户端发起的,流程是客户端请求创建对象,通过wl_map_insert_new函数插入对象,并返回对象的ID(其实是下标),然后把ID传递到服务器端,在服务器端通过wl_map_insert_at函数把创建的对象插入到指定的下标(ID),这样就建立了两个对象的对应关系。只有一个对象是特殊的,就是wl_display.这个对象是写死的下标(为1),因为这个对象肯定是第一个创建的。
- wl_list 链表
struct wl_list {
/** Previous list element */
struct wl_list *prev;
/** Next list element */
struct wl_list *next;
};
wayland实现的这种链表在很多优秀的代码里面都有过,这种链表非常优秀,它可以保存任何类型的元素。为什么可以保存任何类型的元素呢? 我举个例子,你一定很好理解。
在中国有很多很多的家庭,如果想要把这些家庭给串联起来,可以怎么做呢?有个非常好的办法就是,我给每一个家庭一个电话簿,电话簿里面保存两个电话号码,一个是这个家庭前面一家的号码,另一个是后面一个家庭的号码。所有家庭都是这样,是不是就把他们的关系给串联起来了?任何一个家庭都可以通过他家里的电话簿联系到所有家庭。
怎么样? Wayland里面的链表就是这个电话簿一样的角色。
但是这里有个问题,就是链表里面保存的都是电话簿,要怎么把这个电话簿转换成家庭呢? 这个就是C语言的语言特性。如果知道一个结构体成员的地址,就可以反推到这个结构体的地址。
#define wl_container_of(ptr, sample, member) \
(__typeof__(sample))((char *)(ptr) - \
offsetof(__typeof__(*sample), member))
offsetof 这个是C语言标准里面提供的获取成员偏移量的宏,整个宏就是提供成员变量的地址获取到整个结构体的地址。有兴趣的读者可以多翻阅资料,也可以留言咨询。
Wayland源码里面大量使用了这个结构体,来保存各种不同的结构体对象的链表。并且wayland提供了接口来更好的操作这种链表。
- 客户端真正的对象结构体
struct wl_proxy {
struct wl_object object;
struct wl_display *display;
struct wl_event_queue *queue;
uint32_t flags;
int refcount;
void *user_data;
wl_dispatcher_func_t dispatcher;
uint32_t version;
};
在这里我要告诉大家一个事实:
Wayland协议里面的那些interface的对象在客户端其实真正的结构体是wl_proxy,而那些结构体都是不存在的,只是一个声明而已,根本不存在。如果读者有看过wayland的源码,会发现一个问题,就是wayland协议里面的那些interface对象,从来都不是程序员自己创建出来的,而是通过wayland的一些接口返回回来的。全部都是,无一例外。读者如果不相信可以自己去找找,并且可以自己尝试创建那些对象,肯定是会报错的,因为那些结构体都是不存在的,创建会编译出错。
- 服务器端真正的对象结构体
struct wl_resource {
struct wl_object object;
wl_resource_destroy_func_t destroy;
struct wl_list link;
struct wl_signal destroy_signal;
struct wl_client *client;
void *data;
};
和客户端一样,服务器端所有的interface对象全部都是wl_resource结构体对象。
接下来我要总结一下这个结构体里面都保存了些什么东西。看下图:
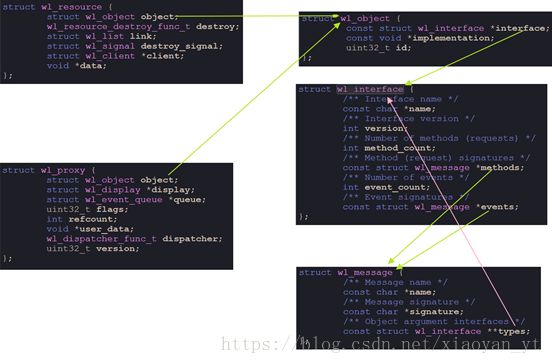
从上图中可知,所有的对象都有个wl_object成员来记录它是属于哪个interface的,并用implementation成员来保存真正需要调用的函数指针,这个id就是用来进行客户端和服务器端对象映射的关键。
然后wl_interface就是wayland协议里面的interface,一个inerface有名字属性,还有版本号,版本号是非常有用的东西。而interface里面的request和event就是由wl_message结构体保存,表示一个函数。wl_message结构体包含函数名,以及函数的参数(所有的参数都保存在signature变量里面,通过字符的方式表示),方法如下:(wayland源码里面的解释)
/**
* Protocol message signature
*
* A wl_message describes the signature of an actual protocol message, such as a
* request or event, that adheres to the Wayland protocol wire format. The
* protocol implementation uses a wl_message within its demarshal machinery for
* decoding messages between a compositor and its clients. In a sense, a
* wl_message is to a protocol message like a class is to an object.
*
* The `name` of a wl_message is the name of the corresponding protocol message.
*
* The `signature` is an ordered list of symbols representing the data types
* of message arguments and, optionally, a protocol version and indicators for
* nullability. A leading integer in the `signature` indicates the _since_
* version of the protocol message. A `?` preceding a data type symbol indicates
* that the following argument type is nullable. While it is a protocol violation
* to send messages with non-nullable arguments set to `NULL`, event handlers in
* clients might still get called with non-nullable object arguments set to
* `NULL`. This can happen when the client destroyed the object being used as
* argument on its side and an event referencing that object was sent before the
* server knew about its destruction. As this race cannot be prevented, clients
* should - as a general rule - program their event handlers such that they can
* handle object arguments declared non-nullable being `NULL` gracefully.
*
* When no arguments accompany a message, `signature` is an empty string.
*
* Symbols:
*
* * `i`: int
* * `u`: uint
* * `f`: fixed
* * `s`: string
* * `o`: object
* * `n`: new_id
* * `a`: array
* * `h`: fd
* * `?`: following argument is nullable
*
* While demarshaling primitive arguments is straightforward, when demarshaling
* messages containing `object` or `new_id` arguments, the protocol
* implementation often must determine the type of the object. The `types` of a
* wl_message is an array of wl_interface references that correspond to `o` and
* `n` arguments in `signature`, with `NULL` placeholders for arguments with
* non-object types.
*
* Consider the protocol event wl_display `delete_id` that has a single `uint`
* argument. The wl_message is:
*
* \code
* { "delete_id", "u", [NULL] }
* \endcode
*
* Here, the message `name` is `"delete_id"`, the `signature` is `"u"`, and the
* argument `types` is `[NULL]`, indicating that the `uint` argument has no
* corresponding wl_interface since it is a primitive argument.
*
* In contrast, consider a `wl_foo` interface supporting protocol request `bar`
* that has existed since version 2, and has two arguments: a `uint` and an
* object of type `wl_baz_interface` that may be `NULL`. Such a `wl_message`
* might be:
*
* \code
* { "bar", "2u?o", [NULL, &wl_baz_interface] }
* \endcode
*
* Here, the message `name` is `"bar"`, and the `signature` is `"2u?o"`. Notice
* how the `2` indicates the protocol version, the `u` indicates the first
* argument type is `uint`, and the `?o` indicates that the second argument
* is an object that may be `NULL`. Lastly, the argument `types` array indicates
* that no wl_interface corresponds to the first argument, while the type
* `wl_baz_interface` corresponds to the second argument.
**/
我简单解释一下:wayland参数不是就那几种吗?这个地方就把这几个参数再缩短标记,用一个字符来表示,但是有个特殊的‘?’,它表示后面这个参数可以为空。在参数的最前面有一个数字,这个数字代表着版本号。但是呢,参数中有可能是interface的对象,那么就必须指明到底是哪个interface的对象,因此wl_message的最后一个成员types,就用一个数组的方式记录这个参数是哪个interface的对象,如果是非interface的参数就为空。
最后,我们来得出,wayland解析协议文件产生了些什么,其实,看上面的图片就能知道很多东西。看下面的文件:

- 产生一个协议源文件, 里面保存了协议文件里面所有的interface转换而成的wl_interface结构体变量,包括wl_message结构体记录的request和event函数。
- 产生一个客户端使用的头文件,里面封装了wl_proxy转换成指定interface假声明的结构体操作的一些接口函数。以及request函数的实现,但是这个实现只是把请求发送到服务器端而已,实际调用在服务器端进行。最后,文件里面还封装了一个回调函数的结构体,成员就是所有的event函数指针,需要客户端去实现,并设置到interface的对象里面,该文件生成了这个设置的接口,实际就是填充到wl_object结构体的implementation变量中。
- 产生一个服务器端头文件,里面基本和客户端一样的组成。只是结构体是wl_resource,函数结构体的成员是所有request的函数指针。以及所有的event的实现。
也就是说,客户端需要程序员自己实现事件(event),服务器端需要程序员实现请求(request)。
好了,wayland协议的解析差不多都说完了,有什么不清楚的,可以留言咨询。接下来就开始讲述wayland协议解析之后的工作原理。
对了,感兴趣的读者可以去看看QtWayland里面解析wayland协议的工具源码,它把wayland协议再做了一层封装成了C++面向对象,看起来更容易。