spark分布式调用python算法包注意事项整理
项目背景:
算法人员在windows上编写算法并运行,算法包含了从原始数据的解析到最终执行结果的存储或者展示等全套逻辑,随着数据量越来越多已经无法单独写脚本进行数据处理,急需一个数据管理功能,同时单机运行算法较慢,希望能分布式运行调度提高效率。同时数据展示、结果展示等功能
整合与调研中注意事宜整理
1、区分大小写,windows环境不区分大小写,但linux运行环境下区分大小写
2、csv文件解析时候需要如有中文,请指明encoding='gbk',进行解析
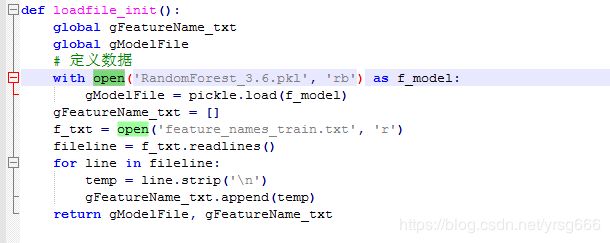
3、当存在多个.py文件互相调用的时候需要将多个py文件打成zip包,在外暴露主函数的py文件即可,其他的包import进入此py文件即可,待测试
https://www.cnblogs.com/SteveWesley/articles/10309757.html
3、参数传递,命令使用--files传入,python脚本中直接调用文件的名字即可,如下: