Ribbon过滤器
前言
本文将描述Ribbon在进行Server过滤的一个重要基础组件:AbstractServerPredicate,它的作用就是在众多Server的列表中,通过一定的过滤策略,T除不合格的Server,留下来合格的Server列表,进而供以选择。
负载均衡策略的核心之一就是对已知的服务列表进行过滤,留下一堆合格的Server进而按照一定规则进行choose选择,因此本文内容非常重要,内容非常重要,非常重要。
正文
PredicateKey
一个POJO,还有两个属性:
- Object loadBalancerKey:用于
IRule#choose(Object)的key - Server server:服务实例
public class PredicateKey {
private Object loadBalancerKey;
private Server server;
... // 省略两个构造器赋值
... // 省略get方法(无set方法哦)
}
它是一个不可变对象,代表这一个断言key。PredicateKey用于断言AbstractServerPredicate的入参:boolean apply(PredicateKey input)。
AbstractServerPredicate
它是服务器过滤逻辑的基础组件,可用于rules and server list filters。它传入的是一个PredicateKey,含有一个Server和loadBalancerKey,由此可以通过服务器和负载均衡器来开发过滤服务器的逻辑。
它是基于谷歌的Predicate实现的断言逻辑,该接口和JDK8的java.util.function.Predicate一毛一样,可以概念互替。
成员属性
该抽象类内部维护着一些成员属性来辅助判断,比如我们上文讲到的LoadBalancerStats就是重中之重。
public abstract class AbstractServerPredicate implements Predicate<PredicateKey> {
protected IRule rule;
private volatile LoadBalancerStats lbStats;
private final Random random = new Random();
private final AtomicInteger nextIndex = new AtomicInteger();
private final Predicate<Server> serverOnlyPredicate = (server) -> {
return AbstractServerPredicate.this.apply(new PredicateKey(input));
}
public Predicate<Server> getServerOnlyPredicate() {
return serverOnlyPredicate;
}
}
rule:负载均衡器LoadBalancer规则:能从其获取到ILoadBalancer,从而得到一个对应的LoadBalancerStats实例lbStats:LoadBalancer状态信息。可以通过构造器指定/set方法指定,若没有指定的话将会从IRule里拿random:随机数。当过滤后还剩多台Server将从中随机获取nextIndex:下一个角标。用于轮询算法的指示serverOnlyPredicate:一个特殊的Predicate:只有Server参数并无loadBalancerKey参数的PredicateKey,最终也是使用AbstractServerPredicate完成断言
静态工具方法
该抽象类提供了三个静态工具方法,用于快速生成一个AbstractServerPredicate实例。
AbstractServerPredicate:
public static AbstractServerPredicate alwaysTrue() {
return (PredicateKey input) -> return true;
}
public static AbstractServerPredicate ofKeyPredicate(final Predicate<PredicateKey> p) {
return (PredicateKey input) -> p.apply(input);
}
public static AbstractServerPredicate ofServerPredicate(final Predicate<Server> p) {
return (PredicateKey input) -> p.apply(input.getServer());
}
成员方法
构造器就不用研究,无非简单的给成员属性赋值。主要看看提供的访问的方法:
AbstractServerPredicate:
// 得到负载均衡器对应的LoadBalancerStats实例
// 该方法为protected,在子类中会被调用用于判断
protected LoadBalancerStats getLBStats() {
if (lbStats != null)
return lbStats;
if (rule != null)
//从rule里面拿到ILoadBalancer,进而拿到LoadBalancerStats
return null
}
// Eligible:适合的
// 把servers通过Predicate#apply(PredicateKey)删选一把后,返回符合条件的Server们
// loadBalancerKey非必须的。
public List<Server> getEligibleServers(List<Server> servers) {
return getEligibleServers(servers, null);
}
public List<Server> getEligibleServers(List<Server> servers, Object loadBalancerKey) { ... }
getEligibleServers方法内部调用断言方法Predicate#apply(PredicateKey)完成Server的过滤,它属于AbstractServerPredicate的核心,因为apply方法在此处是唯一调用处,因此该方法重要。另外,需要注意的是apply方法(具体的过滤逻辑)在本抽象类是木有提供实现的,全在子类身上。
AbstractServerPredicate:
// 它是轮询算法的实现。轮询算法,下面会有应用
private int incrementAndGetModulo(int modulo) {
for (;;) {
int current = nextIndex.get();
int next = (current + 1) % modulo;
if (nextIndex.compareAndSet(current, next) && current < modulo)
return current;
}
}
// 得到Eligible合适的机器们后,采用随机策略随便选一台
public Optional<Server> chooseRandomlyAfterFiltering(List<Server> servers) { ... }
// 得到Eligible合适的机器们后,采用轮策略选一台
public Optional<Server> chooseRoundRobinAfterFiltering(List<Server> servers) { ... }
public Optional<Server> chooseRandomlyAfterFiltering(List<Server> servers, Object loadBalancerKey) { ... }
public Optional<Server> chooseRoundRobinAfterFiltering(List<Server> servers, Object loadBalancerKey) { ... }
该抽象类还是比较合格的,提供不少“工具”可以供给子类直接使用,比如这随机选择、轮询选择等等。下面是它的继承图谱:
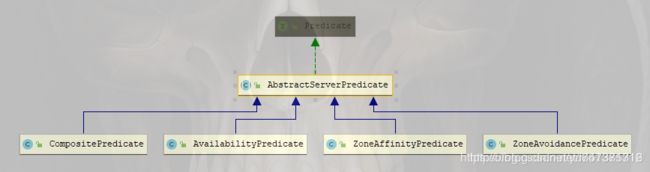
ZoneAffinityPredicate
Affinity:类同的,吸引力。它只会选取指定zone区域内的Server,言外之意就是会过滤掉其它区域的Server们。
说明:每个Server实例都有它自己所属的zone属性,所以可以很方便的通过此属性来完成过滤。
断言方法
它有且仅有一个方法,就是断言方法本身。
public class ZoneAffinityPredicate extends AbstractServerPredicate {
//不陌生把:这就是DeploymentContext部署上下文参数
// 详情内容可参考前面archaius的讲解
private final String zone = ConfigurationManager.getDeploymentContext().getValue(ContextKey.zone);
// 过滤规则:只留下同Zone的Server
// 若这台Server属于当前Zone那就留下,否则丢弃....
@Override
public boolean apply(PredicateKey input) {
Server s = input.getServer();
String az = s.getZone();
if (az != null && zone != null && az.toLowerCase().equals(zone.toLowerCase())) {
return true;
} else {
return false;
}
}
}
这个判断非常简单,和loadBalancerKey木有关系,仅和Server有关。并且指定的zone信息必须是子全局配置Configuration里上下文DeploymentContext来指定。
过滤器ZoneAffinityServerListFilter就是基于此断言器来实现服务器过滤的。
代码示例
@Test
public void fun1() throws InterruptedException {
// 准备一批服务器
List<Server> serverList = new ArrayList<>();
serverList.add(createServer("华南", 1));
serverList.add(createServer("华东", 1));
serverList.add(createServer("华东", 2));
serverList.add(createServer("华北", 1));
serverList.add(createServer("华北", 2));
serverList.add(createServer("华北", 3));
serverList.add(createServer("华北", 4));
// 指定当前的zone
DeploymentContext deploymentContext = ConfigurationManager.getDeploymentContext();
deploymentContext.setValue(DeploymentContext.ContextKey.zone, "华北");
// 准备断言器
ZoneAffinityPredicate predicate = new ZoneAffinityPredicate();
while (true) {
// 以轮询方式选择Server
Optional<Server> serverOptional = predicate.chooseRoundRobinAfterFiltering(serverList);
Server server = serverOptional.get();
String zone = server.getZone();
System.out.println("区域:" + zone + ",序号是:" + server.getPort());
TimeUnit.SECONDS.sleep(5);
}
}
// 请注意:请必须保证Server的id不一样,否则放不进去List的(因为Server的equals hashCode方法仅和id有关)
// 所以此处使用index作为port,以示区分
private Server createServer(String zone, int index) {
Server server = new Server("www.baidu" + zone + ".com", index);
server.setZone(zone);
return server;
}
运行程序,控制台打印:
区域:华北,序号是:1
区域:华北,序号是:2
区域:华北,序号是:3
区域:华北,序号是:4
区域:华北,序号是:1
区域:华北,序号是:2
区域:华北,序号是:3
...
只会选中“华北”区域的机器,多台机器会按照id排序好,非常有规律的轮询规则有木有(若是ramdom随机,就是无规律的喽)。
说明:配置zone的方式有多种,具体你可以参考这篇文章:[享学Netflix] 十四、Archaius如何对多环境、多区域、多云部署提供配置支持?
ZoneAvoidancePredicate
Avoidance:避免、回避、躲开。它负责过滤掉这样的Server们:当某个zone非常糟糕,糟糕到统计达到了threshold阈值,那么就会过滤掉这个zone里面所有的Server们,所以该断言器是具有很强的zone区域意识的。
说明:区域意识在跨机房、跨区域部署的时候非常好用,内置的负载均衡支持能够大大减少你自己的开发量。
规则ZoneAvoidanceRule就是基于此断言器来实现服务器过滤的,对应的负载均衡器有ZoneAwareLoadBalancer,它是Spring Cloud下默认的负载均衡器。
成员属性
public class ZoneAvoidancePredicate extends AbstractServerPredicate {
private volatile DynamicDoubleProperty triggeringLoad = new DynamicDoubleProperty("ZoneAwareNIWSDiscoveryLoadBalancer.triggeringLoadPerServerThreshold", 0.2d);
private volatile DynamicDoubleProperty triggeringBlackoutPercentage = new DynamicDoubleProperty("ZoneAwareNIWSDiscoveryLoadBalancer.avoidZoneWithBlackoutPercetage", 0.99999d);
private static final DynamicBooleanProperty ENABLED = DynamicPropertyFactory.getInstance().getBooleanProperty("niws.loadbalancer.zoneAvoidanceRule.enabled", true);
}
triggeringLoad:triggeringBlackoutPercentage:
关于这两个阈值,上文已有讲解,并且指明了triggeringLoad默认值极度不合理的地方。请参考:[享学Netflix] 四十七、Ribbon多区域选择:ZoneAvoidanceRule.getAvailableZones()获取可用区
ENABLED:是否开启多zone选择的支持,默认true是开启的。可通过外部化配置niws.loadbalancer.zoneAvoidanceRule.enabled来禁用(一般来说不建议你禁用它)。
断言方法
ZoneAvoidancePredicate:
@Override
public boolean apply(@Nullable PredicateKey input) {
// 若开关关闭了,也就是禁用了这个策略。那就永远true呗
if (!ENABLED.get()) {
return true;
}
// 拿到该Server所在的zone,进而完成判断
String serverZone = input.getServer().getZone();
if (serverZone == null) {
return true;
}
// 若可用区只剩一个了,那也不要过滤了(有总比没有强)
if (lbStats.getAvailableZones().size() <= 1) {
return true;
}
...
// 拿到全部可用的zone后,判断该Server坐在的Zone是否属于可用区内
Set<String> availableZones = ZoneAvoidanceRule.getAvailableZones(zoneSnapshot, triggeringLoad.get(), triggeringBlackoutPercentage.get());
return availableZones.contains(serverZone);
}
}
这段断言逻辑,最核心的可以用这一句代码解释:ZoneAvoidanceRule.getAvailableZones()contains(serverZone)。而工具方法getAvailableZones()在上篇文章已经着重分析了其内部实现细节,非常的重要,这里是电梯直达,建议你一定要知晓。
AvailabilityPredicate
availability:可用性,有效性。该断言器主要是对服务的可用性进行过滤(过滤掉不可用的服务器)。很明显,它的判断需要基于LoadBalancerStats/ServerStats来完成。
过滤逻辑
AvailabilityPredicate:
// 平大难逻辑在shouldSkipServer()方法上
@Override
public boolean apply(@Nullable PredicateKey input) {
LoadBalancerStats stats = getLBStats();
if (stats == null) {
return true;
}
return !shouldSkipServer(stats.getSingleServerStat(input.getServer()));
}
// 根据Server状态ServerStats来判断该Server是否应该被跳过
private boolean shouldSkipServer(ServerStats stats) {
if ((CIRCUIT_BREAKER_FILTERING.get() && stats.isCircuitBreakerTripped())
|| stats.getActiveRequestsCount() >= activeConnectionsLimit.get()) {
return true;
}
return false;
}
由此可见,它主要判断Server的两项内容:
-
isCircuitBreakerTripped()即断路器是否在生效中- 默认断路器生效中就会忽略此Server。但是你也可以配置
niws.loadbalancer.availabilityFilteringRule.filterCircuitTripped=false来关闭此时对断路器的检查, 当然默认它是true(不建议你改它)
- 默认断路器生效中就会忽略此Server。但是你也可以配置
-
该Server的并发请求数
activeRequestsCount大于阈值,默认值非常大:Integer.MAX_VALUE,可有如下配置方式:- 通用配置
niws.loadbalancer.availabilityFilteringRule.activeConnectionsLimit=10000(建议根据你的机器配置和压测结果,选择一个合适的值) - 根据具体ClientName配置:
.ribbon.ActiveConnectionsLimit = xxx(这里有个坑爹的地方:此处的ActiveXXX的A是大写,其它地方均是小写哦~)
- 通用配置
CompositePredicate
组合模式。它还具有“回退”到更多(不止一个)不同谓词之一的功能。如果主的Predicate产生的过滤服务器太少,它将一个接一个地尝试fallback的Predicate,直到过滤服务器的数量超过一定数量的阈值或百分比阈值。
成员属性
public class CompositePredicate extends AbstractServerPredicate {
private AbstractServerPredicate delegate;
private List<AbstractServerPredicate> fallbacks = Lists.newArrayList();
private int minimalFilteredServers = 1;
private float minimalFilteredPercentage = 0;
// 接口方法的实现
@Override
public boolean apply(@Nullable PredicateKey input) {
return delegate.apply(input);
}
}
delegate:primary首选的Predicate断言器。注意:它可能是一个,也可能是多个断言器组成的一个chainfallbacks:回退。当然primary没有达到过滤的要求的时候,会时候fallabck里的进行过滤minimalFilteredServers:默认值是1。minimalFilteredPercentage:上面是按照个数,这是按照百分比控制阈值,默认值是0。
以上两个参数代表阈值:表示经过过滤后,我最少希望有1台服务器。
过滤逻辑
我们List是经过抽象父类的getEligibleServers()完成过滤的,因此本类“加强”此逻辑的话,仅需复写此方法即可:
CompositePredicate:
// 从主Predicate获取**过滤后**的服务器,如果过滤后的服务器的数量还不够
// (应该说还太多),继续尝试使用fallback的Predicate继续过滤
@Override
public List<Server> getEligibleServers(List<Server> servers, Object loadBalancerKey) {
// 1、使用主Predicate完成过滤,留下合格的Server们
List<Server> result = super.getEligibleServers(servers, loadBalancerKey);
// 2、继续执行fallback的断言器
Iterator<AbstractServerPredicate> i = fallbacks.iterator();
while (i.hasNext())
if(result.size() < minimalFilteredServers
|| result.size() < servers.size() * minimalFilteredPercentage){
// 特别注意:这里传入的是Server,而非在result基础上过滤
// 所以每次执行过滤和上一次的结果没有半毛钱关系
result = i.next().getEligibleServers(servers, loadBalancerKey);
}
}
return result;
}
对此部分“加强版”过滤逻辑做如下文字总结:
-
使用主Predicate(当然它可能是个链)执行过滤,若剩余的server数量不够数(比如我最小希望有1台),那么就触发fallback让它去尝试完成使命
-
若fallback有值(不为空),就顺序的一个一个的尝试,让若经过谁处理完后数量大于最小值了,那就立马停止返回结果;但是若执行完所有的fallback后数量还是小于阈值不合格咋办呢?那就 last win
- 重点:每次执行Predicate都是基于原来的ServerList的,所以每次执行都是独立的,这点特别重要
构建实例
它的实例只能采用其内置的Builder模式来构建,为各个属性赋值,具体见下面的代码示例。
代码示例
@Test
public void fun7() {
// 准备一批服务器
List<Server> serverList = new ArrayList<>();
serverList.add(createServer("华南", 1));
serverList.add(createServer("华东", 1));
serverList.add(createServer("华东", 2));
serverList.add(createServer("华北", 1));
serverList.add(createServer("华北", 2));
serverList.add(createServer("华北", 3));
serverList.add(createServer("华北", 4));
serverList.add(createServer("华北", 5));
serverList.add(createServer("华北", 6));
serverList.add(createServer("华北", 7));
serverList.add(createServer("华北", 8));
serverList.add(createServer("华北", 9));
serverList.add(createServer("华北", 10));
serverList.add(createServer("华北", 11));
serverList.add(createServer("华北", 12));
// 指定当前的zone
DeploymentContext deploymentContext = ConfigurationManager.getDeploymentContext();
deploymentContext.setValue(DeploymentContext.ContextKey.zone, "华北");
// 准备断言器(组合模式)
CompositePredicate compositePredicate = CompositePredicate
.withPredicate(new ZoneAffinityPredicate()) // primary选择一个按zone过滤的断言器
.addFallbackPredicate(AbstractServerPredicate.alwaysTrue())
// 自定义一个fallabck过滤器
.addFallbackPredicate(new AbstractServerPredicate() {
@Override
public boolean apply(@Nullable PredicateKey input) {
int port = input.getServer().getPort();
return port % 10 > 5;
}
})
// 我最少要20台机器,但经过主Predicate过滤后只剩12台了,所以不用它的结果,使用fallback的结果
.setFallbackThresholdAsMinimalFilteredNumberOfServers(20)
.build();
List<Server> servers = compositePredicate.getEligibleServers(serverList);
System.out.println(servers);
}
运行程序,控制它打印:
[www.baidu华北.com:6, www.baidu华北.com:7, www.baidu华北.com:8, www.baidu华北.com:9]
解释:我最少要20台机器,但经过主Predicate过滤后只剩12台了,不符合我的需求,所以不用它的结果,使用fallback处理。
总结
关于Ribbon服务器过滤逻辑的基础组件:AbstractServerPredicate就先介绍到这了,本文内容非常重要,内容非常重要,非常重要,负载均衡的核心就是对Server进行筛选,因此它制定的一些规则大都基于本文所述的过滤逻辑,所以掌握本文对后面继续了解IRule会非常有帮助,将好不吃力。