如何使用GIST+LIBLINEAR分类器提取CIFAR-10 dataset数据集中图像特征,并用测试数据进行实验
上学期开了多媒体的课程,把其中一个课程设计实现的过程与大家分享。
转载请注明出处,谢谢。
最近整理文件的时候,发现了我以前写的文档和源码,附上github的下载地址
https://github.com/bigfishman/Gist-LIBLINEAR-CIFAR-10
喜欢的朋友可以fork
这个课程设计是为了实现图像分类的整个过程,通过完成整个的工作过程,更好的理解图像分类这一概念,提高自己的理论与实践结合的能力。整个项目分为四大步:导入数据、特征提取部分、分类器训练部分、标签预测部分。根据课程,我们选择的数据集为CIFAR-10,特征提取采用的是GIST特征提取方法,分类方法我们使用的是LIBLINEAR中自带的Train和Predict程序。到最后得出结果,进行结果分析。
工具及设计方案详细介绍
CIFAR-10 dataset
CIFAR-10数据集包括60000个32x32彩色图像,分布在在10类,每个类有6000幅图像。这60000幅图片中分别包括50000幅训练图像和10000幅测试图像。
数据集被分成了五个训练文件和一个测试文件,每一个文件都有10000张图片。测试文件中随机的包含了每个类的1000幅图片,但是每个训练批次中的图像是随机的,其中包含的图像并不是固定一样的。所以一些培训批次可能某一个类包含更多的图像。而五个训练文件,每个类的总数为5000个,这样就保证了样本的概率平衡。
还需要注意的是,从CIFAR-10中加载的内容中的data数据是整数,需要我们转换成图片,在网站上面我们可以看到也给出了相应的解释。每一个文件中有一个10000x3072N数组。数组的每一行存储一个32x32的彩色图像。前1024项代表的红色,中间1024个代表的是绿色,和最后1024代表的是蓝色。图像存储是按行主序,使数组的前32项是图像的第一排红色通道值。
GIST特征提取
根据项目提供的网站,我们可以大致知道,GIST特征提取是提出一个识别现实世界的计算模型,这个模型绕过个别对象或区域的分割和处理。用一个五维的感知维度来代表一个场景的主要内容,包括自然性、开放性、粗糙度、扩张性和坚固性。这些维度能够可靠的估计使用的光谱和粗定位信息,虽有可用这些维度来代表一个场景图片。
LIBLINEAR分类器
LIBLINEAR是一个用于大规模数据分类的线性分类器,支持逻辑回归和向量机。同时,LIBLINEAR还为开发者提供了好用的命令行和库接口。不管是开发者还是深层次的使用者,LIBLINEAR都有对应的文档供其查阅。实验证明,LIBLINEAR对于大规模数据分析十分有效。
从上面的数据集我们可以知道,数据的数量为60000,而相应的类却仅仅为10,数据数量远远大于数据类别。所以我们使用LIBLINEAR分类器,
具体设计方案
从相应网站下载相应软件。这里CIFAR-10我们下载MATLAB版,解压数据得到训练和测试数据,可以在MATLAB中用LOAD加载,只是现在的数据是整数类型,我们需要将其转换成图片,然后对转换后的图片进行特征提取,将相应的结果保存下来,保存的格式非常重要,我们可以将从LIBLINEAR中下载的数据中的heart-scale打开,记住相应的格式为:labelID:feartures。重复将所有的图片都做一遍,然后将所有的结果保存到一个特定的地方(Feartures.txt),就相当于特征已经提取出来,接下来要做的只是运用LIBLINEAR分类器将所得的特征进行分类(Train),然后用相应的数据进行测试然后进行标签预测(Predict)。从而完成整个图片分类过程。
实践操作
导入数据
实践部分我们根据上面的具体设计来进行

图一:下载的CIFAR-10数据集包
将下载的数据在MATLAB中load后如下图所示:
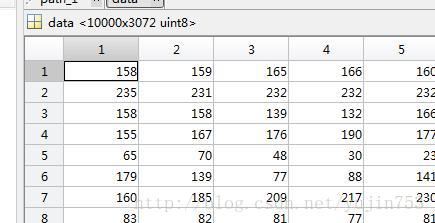
图二:MATLAB中加载数据集
从上图我们可以看到,data中的数据是以二维数组的形式存储的图片信息,每一行有3072个数据,刚好包括了红、绿、蓝三色,每一色的大小为1024即32*32大小,每一行则代表一幅图片。
下面进行二维数组到图片的转换。
RGB图片的每一个色由32*32的矩阵表示
所以我们可以设置变量Red,Green,Blue三个数组来用于读取相应的颜色,然后将相应的颜色值存进Image里面,这时Image就表示一幅图片了
过程如下:

图三:将data数据转换成图片
用Imshow(Image)结果如下:
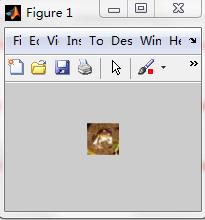
图四:CIFAR-10第一幅图片
对着一幅图片进行特征提取,利用从网站下载下来的LMgist文件,可以得到如下的结果:

图五:GIST特征提取效果图
下面我们要对整个的数据进行收集,有50000个图片信息要进行处理。分别load加载,可以得到相应的数据我们设为data1、data2、data3、data4、data5,然后用一个新的data合并这五个数据data=[data1;data2;data3;data4;data5]。这样我们就得到一个50000*3072大小的矩阵了,这样整个的数据就都导出来了。方法如下:

图六:导入所有训练数据
这样数组sumdata中的数据就包含所以训练数据了,sumdata1中的数据就是每一幅图片的label了,表明每幅图片属于哪个类。
特征提取
这里我们使用的是Gist特征提取,下载的gistdescriptor包中已经有了一个Gist函数,我们只要进行调用就可以,如下:
[gist1,param] = LMgist(Image,'',param);
这里的Image就是数据导入的Image图片,直接放入LMgist当中,可以返回一个gist1数组,
我们每导入一幅图片的内容就进行相应的特征提取,用一个1:50000的循环,将每一幅图片都提取特征。
过程如下:

图七:调用LMgist进行特征提取
将提取的特征保存到相应的文件当中:
fid= fopen('E:/Feartrues.txt','w');
fprintf(fid,'%d',sumdata1(t));
fprintf(fid,'%d:%g', ii, gist1(1, ii));
fprintf(fid,'\n');
上面代码将会在E盘Feartures.txt文件中保存提取的特征,格式是按照前面提到的heart_scale文件中的格式的,labelID:Feartures。其中Feartures用一个512的向量进行保存。
分类器训练
在前面我们介绍到,下载的数据包为Liblinear-1.94,我们找到其中一个文件heart_scale,已经介绍了,相应的数据格式,在第二步中已有详细介绍。
将特征提取的Feartures.txt文件作为训练数据的输入,即Train Feartures.tx 我们可以得到一个Feartures.model,这个model就是由训练得出的分类器模型。其中在windows环境下,我们可以直接使用已经编译连接好的可执行文件,该文件在解压后windows目录下。
Train的格式为:
train[options] training_set_file [model_file];其中train_set_file为我们要测试的文件,就是上面的Feartures.txt,model_file为输出文件。
Options的一些操作,如multiclassclassification:
-stype :对于多分类,指定使用的分类器(默认是1):
0-- L2-regularized logistic regression(primal)
1-- L2-regularized L2-loss support vectorclassification (dual)
2-- L2-regularized L2-loss support vectorclassification (primal)
3-- L2-regularized L1-loss support vectorclassification (dual)
4-- support vector classification by Crammerand Singer
5-- L1-regularized L2-loss support vectorclassification
6-- L1-regularized logistic regression
7-- L2-regularized logistic regression (dual)
我们可以在训练的时候使用multiclassclassification。
标签预测
我使用的是下载包中自带的Predict程序,在下载包中windows目录下面可以找到。然后用上面生成的Feartures.txt.model文件作为一个输入,然后从CIFAR-10中提出test_batch.mat文件作为测试数据,然后output.txt为输出文件。
Predict用法:
predict[options] test_file model_file output_file
options:
-bprobability_estimates:是否输出概率估计。默认是0,不输出。只对logistic回归有用
-q:安静模式(无输出信息)
需要注意的是-b只在预测阶段用到。这个和LIBSVM不同。
结果及其分析
实验结果
特征提取的结果:】

图八:特征提取结果
从上面可以看出,总共50000幅图片,特征提取的时间为55.808367分钟,电脑CPU是OCRE-i5,执行速度还是相对较快的。特征提取完之后,在E盘下面生成了一个Feartures.txt文件,打开要花点时间,有300多MB。

图九:Feartures.txt内容
文件中的格式,跟我们设计的是一样的,总共50000行,每一行有512个特征值,第一个数字为label,符合项目要求。
按照前面训练数据提取特征的方法,将test_batch.mat测试文件中的数据也进行特征提取,存进Test_data.txt中,然后就可以当作Predict程序的一个输入了。
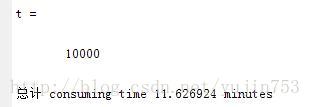
图十:提取测试数据
下表是Train的不同方法所用的时间和相应Predict的结果:
Train–S type Feartures.txt默认为1
表一:训练和预测结果表
| -Stypemulticlass classification |
Train 时间 |
Predict时间 |
Predict结果 Accuracy |
| -S0L2-regularizedlogistic regression(primal) |
91s |
4.6s |
58.23%(5823/10000) |
| -S1L2-regularizedL2-loss support vectorclassification (dual) |
48s |
7.9s |
58.23%(5823/10000) |
| -S2L2-regularizedL2-loss support vectorclassification (primal) |
75s |
3.8s |
58.2%(5820/10000) |
| -S3L2-regularizedL1-loss support vectorclassification (dual) |
39s |
3.6s |
56.08%(5608/10000) |
| -S4supportvector classification by Crammerand Singer |
45s |
3.9s |
57.84%(5784/10000) |
| -S5L1-regularizedL2-loss support vectorclassification |
591s |
2.6s |
58.2%(5820/10000) |
| -S6L1-regularizedlogistic regression |
46s |
3.9s |
57.98%(5798/10000) |
| -S7L2-regularizedlogistic regression (dual) |
28.2s |
3.4s |
58.23%(5823/10000) |
结果分析
从表中可以看出不同模式下面的Train时间和Predict时间有所差距,但是差距都不是特别大,其中和其他有较大差距的-S5的Train时间,是其他的十倍左右。Predict时间集中模式都差不多,predict结果Accuracy都在60%以下,其中有几项数据一样,比如-S0、-S1、-S7都为58.23%,-S2和-S5都是58.2%,其中-S7的train时间和Predict时间和结果综合起来是这8种模式中最好的。