Improved Dense Trajectory用法及源码分析
cvpr2014的Ivan Laptev大神的tutorial 中总结IDT+fisher coding是目前state-of-art的人体动作行为算法。现在基本涉及的论文效果都要跟iDT进行比对。在此写下自己对整个代码的理解,以方便学习。若有不当之处敬请指出。转载请提供原文链接出处。
LEAR实验室 这个实验室个人感觉很不错,放出来的代码基本都能work,而且有不错的的效果。
早期版本的dense trajectory代码下载,后来加入了SURF消除camera jitter以及Bounding Boxes消除了其他背景噪声,于是有了现在的iDT(improved Dense Trajectory)(http://lear.inrialpes.fr/people/wang/dense_trajectories).
首先我们先让代码运行起来看到效果再来分析一下它的实现机制吧。首先解压文件,在DenseTrackStab.cpp文件中看到:
int show_track = 0; // set show_track = 1, if you want to visualize the trajectories
为了有更好的可视化效果,我们把show_track变量改成1。
下面开始编译:在解压的Improved_trajectory_release文件夹的目录中输入make命令。如果编译成功的话,会产生release文件夹,里面有DenseTrackStab和Video两个文件。若编译为成功可能是你的opencv没有装好,根据给出的错误提示再仔细检查一下。
在目录下输入:
./release/DenseTrackStab ./test_sequences/person01_boxing_d1_uncomp.avi
便可看到如下程序运行画面,同时Terminal中闪过一堆一堆数字。下面我们就深入源码中探寻这个程序都干了些什么。

Video.cpp部分
先看Video.cpp,这是个很简单的显示视频并在控制台打印出帧编号的程序。
char* video = argv[1];
capture = cvCreateFileCapture(video);
从命令行参数获得视频的地址,再通过地址把视频存到capture结构中。
frame = cvQueryFrame( capture );
在用一个while循环读出cpature结构中的frame,再按照frame的大小和通道造一个img,把frame复制到img中,再把img展示出来,顺便输出多少帧(这个程序的帧也是从0开始)。
总得来这个程序就是测试一下视频能不能被opencv支持解码出来,这个代码太简单了,我们看复杂一点的。
DenseTrackStab部分
几个头文件:
×DenseTrackStab.h 定义了Track等的数据结构。最重要的track类里面可以看出:
std::vector point; //轨迹点
std::vector disp; //偏移点
std::vector hog; //hog特征
std::vector hof; //hof特征
std::vector mbhX; //mbhX特征
std::vector mbhY; //mbhY特征
int index;// 序号
结合他们的论文可以知道,基本方法就是在重采样中提取轨迹,在轨迹空间中再提取hog,hof,mbh特征,这些特征组合形成iDT特征,最终作为这个动作的描述。
×Initialize.h:涉及各种数据结构的初始化,usage()可以看看,毕竟readme里面讲的用法没那么细。
×OpticalFlow.h: 主要用了Farneback计算光流,把金字塔的方法也写进去了,金字塔方法主要是为了消除不同尺寸的影响,让描述子有更好的泛化能力。这个函数具体看不懂的小朋友还是好好把光流计算补补吧。
×Descriptors.h:提供一些工具函数。
主函数程序
还是从main函数开始看吧,整体思路清晰一些。只说些不太好理解的关键代码。
TrackInfo trackInfo;
DescInfo hogInfo, hofInfo, mbhInfo;
这几个变量用来存放hog,hof,mbh,track的特征信息。然后对这几个变量进行了初始化,初始化参数可以在命令行配置中改。
SeqInfo seqInfo;
这个变量把视频信息存到seqInfo当中。
std::vector bb_list;
if(bb_file) {
LoadBoundBox(bb_file, bb_list);
assert(bb_list.size() == seqInfo.length);
}
这个是从文件中载入boundingBox的信息到bb_list变量中,bb_list就是没一
最后还要保证bb_list的大小和seqInfo长度相等,意思就是说每帧都对应有boundingBox数据。这个bb_file的文件格式是什么呢?
frameID a1 a2 a3 a4 a5 b1 b2 b3 b4 b5 …
每行开始由帧序数标出,后面每5个为一组定义一个boudingBox,分别为左上的xy,右下的xy以及置信度,就是对这个矩形的确定概率。因为一帧图像可能框出来的人有好多个,这种细粒度的控制比大致框出一个范围能更有效地滤去噪声。
PS:关于BoundingBox本人写了一个手动框[BoundingBox的小工具](https://github.com/zackzhaoyang/ManualBoudingBoxTool)。有兴趣的同学可以自己下载下来用。
下面通过surf特征比对来消除相机抖动。通常颜色信息对动作判断并没有什么作用,一般我们都将其灰度化。提取前后两帧的surf特征(使用human_mask提取的surf特征更准确一些)来比对,如果差距过大(pts_all.size(>50),就用来校正。
Mat temp = findHomography(prev_pts_all, pts_all, RANSAC, 1, match_mask);
用来寻找一个最佳的mapping,用这种方法来消除镜头剧烈晃动造成的光流计算不准确的问题。
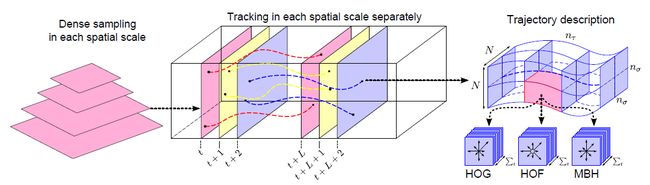
修正完相机抖动。我们开始开始提iDT特征了。首先为了消除尺寸的影响,我们构建了金字塔模型,因为HOG是对表面特征描述,HOF是对局部动作信息描述,MBH是相对运动信息,这些都需要光流信息,我们可以直接建立光流金字塔。另外,轨迹的track也是根据光流的哦。
//track feature points in each scale separately
std::list这段是轨迹追踪的最主要的代码,我们沿着轨迹的x,y,t方向分别取bin计算其hog,hof,mbh特征,再线性排列起来。就是我们的iDT特征了。
GetRect(prev_point, rect, width, height, hogInfo);
GetDesc(hogMat, rect, hogInfo, iTrack->hog, index);
GetDesc(hofMat, rect, hofInfo, iTrack->hof, index);
GetDesc(mbhMatX, rect, mbhInfo, iTrack->mbhX, index);
GetDesc(mbhMatY, rect, mbhInfo, iTrack->mbhY, index);
iTrack->addPoint(point);
代码当中轨迹也作为特征输出了。另外一些细枝末节的地方,比如最长长度超过了之后从0开始计算啊,gap是隔了几帧进行取样啊,应该都很容易看懂。经本人实验,轨迹特征对效果提升并不是很明显。如果和其他特征共同组成高维度特征的话,可以考虑不用轨迹特征。最后送上论文中的说明图,希望大家对iDT会有更新和更深的了解。