Prometheus 初探
首先-什么是 TSDB (Time Series Database):
我们可以简单的理解为.一个优化后用来处理时间序列数据的软件,并且数据中的数组是由时间进行索引的.
时间序列数据库的特点:
- 大部分时间都是写入操作
- 写入操作几乎是顺序添加;大多数时候数据到达后都以时间排序.
- 写操作很少写入很久之前的数据,也很少更新数据.大多数情况在数据被采集到数秒或者数分钟后就会被写入数据库.
- 删除操作一般为区块删除,选定开始的历史时间并指定后续的区块.很少单独删除某个时间或者分开的随机时间的数据.
- 数据一般远远超过内存大小,所以缓存基本无用.系统一般是 IO 密集型
- 读操作是十分典型的升序或者降序的顺序读,
- 高并发的读操作十分常见.
常见的时间序列数据库:
部分常见 TSDB 官网如下:
| TSDB | 官网 |
|---|---|
| influxDB | https://influxdata.com/ |
| RRDtool | http://oss.oetiker.ch/rrdtool/ |
| Graphite | http://graphite.readthedocs.org/en/latest/ |
| OpenTSDB | http://opentsdb.net/ |
| Kdb+ | http://kx.com/ |
| Druid | http://druid.io/ |
| KairosDB | http://kairosdb.github.io/ |
| Prometheus | https://prometheus.io/ |
关于 Prometheus
Prometheus是什么?
Prometheus 是由 SoundCloud 开发的开源监控报警系统和时序列数据库(TSDB).自2012年起,许多公司及组织已经采用 Prometheus,并且该项目有着非常活跃的开发者和用户社区.现在已经成为一个独立的开源项目核,并且保持独立于任何公司,Prometheus 在2016加入 CNCF ( Cloud Native Computing Foundation ), 作为在 kubernetes 之后的第二个由基金会主持的项目.
prometheus 的特点
和其他监控系统相比,Prometheus的特点包括:
- 多维数据模型(时序列数据由metric名和一组key/value组成)
- 在多维度上灵活的查询语言(PromQl)
- 不依赖分布式存储,单主节点工作.
- 通过基于HTTP的pull方式采集时序数据
- 可以通过中间网关进行时序列数据推送(pushing)
- 目标服务器可以通过发现服务或者静态配置实现
- 多种可视化和仪表盘支持
prometheus 相关组件
Prometheus生态系统由多个组件组成,其中许多是可选的:
- Prometheus 主服务,用来抓取和存储时序数据
- client library 用来构造应用或 exporter 代码 (go,java,python,ruby)
- push 网关可用来支持短连接任务
- 可视化的dashboard (两种选择,promdash 和 grafana.目前主流选择是 grafana.)
- 一些特殊需求的数据出口(用于HAProxy, StatsD, Graphite等服务)
- 实验性的报警管理端(alartmanager,单独进行报警汇总,分发,屏蔽等 )
promethues 的各个组件基本都是用 golang 编写,对编译和部署十分友好.并且没有特殊依赖.基本都是独立工作.
prometheus 的架构
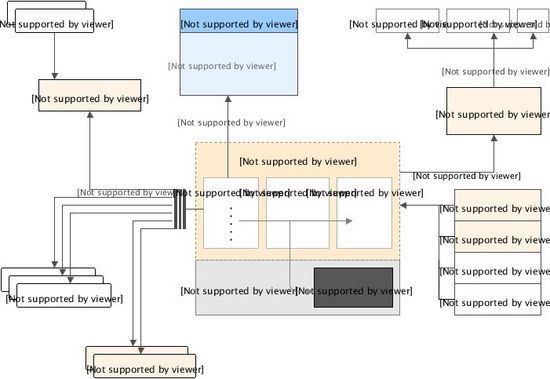

部署及配置
promethues 官方给出了多重部署方案,包括但不限于 docker 容器,ansible,chef,saltstack 等.
其实官方已经给了预编译的二进制文件.如果没有修改代码的特殊需求,直接拿到二进制文件进行部署也是可以的.
下载地址: https://prometheus.io/download/
部署方式十分简单
tar xvfz prometheus-*.tar.gz
cd prometheus-*
在 prometheus 目录下有一个名为 prometheus.yml 的主配置文件.其中包含大多数标准配置及 prometheus 的自检控配置,配置文件如下.
global:
scrape_interval: 15s # 默认抓取间隔, 15秒向目标抓取一次数据
# 和外部系统交互时每一条从本机获取的数据都会打上如下标签
external_labels:
monitor: 'codelab-monitor'
# 这里是抓去 promethues 自身的配置
scrape_configs:
# job name 会以标签`job=`添加到每一条由该配置抓去到的时序数据
- job_name: 'prometheus'
# 覆盖默认抓取间隔
scrape_interval: 5s
static_configs:
- targets: ['localhost:9090']
# 添加两个线上抓取实例
- job_name: 'ceph'
scrape_interval: 5s
static_configs:
- targets: ['k0140v:9128']
labels:
group: 'shbt' # 会对该配置生成的时序数据添加一条 `group=`的标签
- targets: ['ceph01:9128']
labels:
group: 'bjyt'
- job_name: 'openstack'
scrape_interval: 30s
static_configs:
#target 可以使用 "," 分割,添加多个目标
- targets: ['openstack185:9128', 'openstack194:9128']
labels:
group: "bjyt"
然后我们通过该配置文件启动 promethues
./prometheus -config.file=prometheus.yml
prometheus 本身是自带 exporter 的,我们通过请求 http://localhost:9090/metrics 可以查看从 exporter 中能具体抓到哪些数据
监控数据
数据样本
和大多数 TSDB 类似,promethus 支持的数据样本非常简单:
- 一个 float64 的值
- 一个毫秒精度的时间戳
标识
标识监控数据的方式十分简单,给一个监控项名称和一些标签,时序数据经常使用这种标识方法
{ 举例来说, 一个时间序列的监控名称为 api_http_requests_total 标签为 method="POST" 和 handler="/message" ,那么监控数据的标识如下:
api_http_requests_total{method="POST", handler="/messages"}这种标识方式与 OpenTSDB 相同.
监控结果
我们实际收集到的数据大多如下:
ceph_osd_avail_bytes{osd="osd.0"} 3.205084244e+12
ceph_osd_avail_bytes{osd="osd.1"} 2.892447332e+12
ceph_osd_avail_bytes{osd="osd.10"} 3.21853432e+12
ceph_osd_avail_bytes{osd="osd.100"} 3.062200424e+12
ceph_osd_avail_bytes{osd="osd.101"} 3.126474844e+12
ceph_osd_avail_bytes{osd="osd.102"} 3.079620512e+12
ceph_pool_available_bytes{pool="backups"} 1.30342001987587e+14
ceph_pool_available_bytes{pool="images"} 1.30342001987587e+14
ceph_pool_available_bytes{pool="rbd"} 1.30342001987587e+14
ceph_pool_available_bytes{pool="rgw-test"} 1.30342001987587e+14
ceph_pool_available_bytes{pool="test_crush"} 1.30342001987587e+14
ceph_pool_available_bytes{pool="vms"} 1.30342001987587e+14
ceph_pool_available_bytes{pool="vmscache"} 2.301547932444e+12
监控数据类型
- Counter:计数器是一个累加的度量类型,记录单调递增的数据.一般用于记录服务的请求数,任务完成数,错误发生数.
- Gauge:量表用于记录可任意变大变小的数值,如cpu idle,内存使用率,磁盘IO等。
- Historgram:直方图用于度量数据中值的分布情况,如请求时间或响应大小。
- Summary: 用于度量数据累价值或总数.
自带 dashboard及查询语句
prometheus 自带一个比较简单的dashboard 可以查看表达式搜索结果,报警配置,prometheus 配置,exporter 状态等
我们以一些真实数据为例看一下表达式及查询结果.
1. 我们可直接查询监控项ceph_pool_read_total并绘图如下

2. 我们也可以在查询语句中通过添加一组标签,并用 {} 阔起来,来细化查询.
例如我们只想查看 bjyt 这个 group 各个 pool 全局读取的数据.
ceph_pool_read_total{group="bjyt"}
另外,也可以也可以将标签值反向匹配,或者对正则表达式匹配标签值:
- =:选择相等的字符串标签
- !=:选择不相等的字符串标签
- =~:选择匹配正则表达式的字符串标签(或子标签)
- !=:选择不匹配正则表达式的字符串标签(或子标签)
例如
ceph_pool_read_total{pool=~"vms.*"}会如上图但只查询出 pool 名为 vms 及 vmscahe 的数据.
3. 如果我们以时间窗口来作为筛选纬度计算各个 pool 读IO的真实速率,可以用以下语句查询
irate(ceph_pool_read_total{pool=~"vms"}[1m])
这里的 irate() 为 promethues 的查询函数.与之对应的是rate().
这两个函数在 promethues 中经常用来计算增量或者速率,在使用时需要指定时间范围如[1m]
- irate(): 计算的是给定时间窗口内的每秒瞬时增加速率.
- rate(): 计算的是给定时间窗口内的每秒的平均值.
如果还是以前面的监控项进行查询但是以 rate() 计算速率的话,绘制的结果如下:

rate(ceph_pool_read_total{pool=~"vms"}[1m])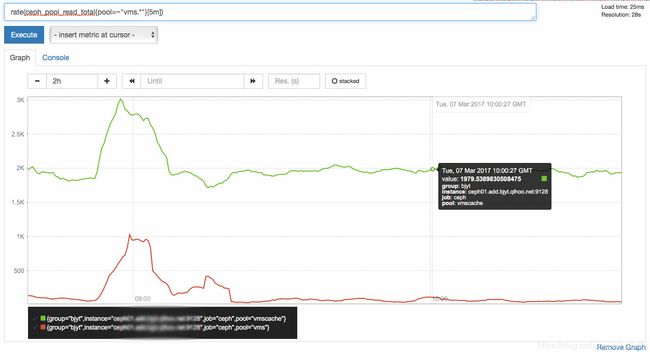
promethues 支持的函数还有很多,具体的函数说明可详见官方文档 Functions
如果在线上使用的话,可以将 Prometheus 和 grafana 相结合.可以进行十分丰富的监控结果展示.
比如 ceph 单机房集群的监控可以是这样的:
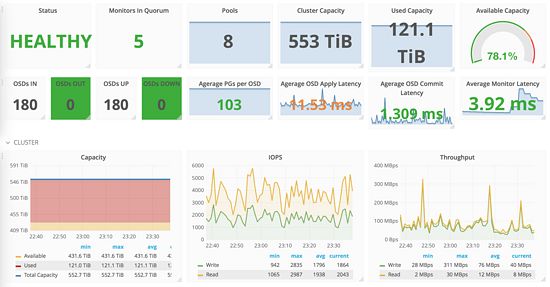
先简单介绍这么多.
后面会通过几篇文章详细介绍一些常用的查询方法, exporter的编写及使用方法,以及 promethues 如何结合 grafana使用和promethues 是如何进行报警的.
参考文献 :
- http://liubin.org/blog/2016/02/18/tsdb-intro/
- https://www.xaprb.com/blog/2014/06/08/time-series-database-requirements/
- https://www.xaprb.com/blog/2014/03/02/time-series-databases-influxdb/
- https://zhuanlan.zhihu.com/p/24811652