【深入理解C++11】第三章 通用为本,专用为末
通用为本,专用为末
- 3.1 继承构造函数
- 3.1.1 使用using声明
- 3.1.2注意继承构造函数使用过多造成的冲突问题
- 3.2 委派构造函数
- 3.3 右值引用:移动语义和完美转发
- 3.3.1 指针成员与拷贝构造
- 3.3.2 移动语义
- 3.3.3 左值、右值与右值引用
- 3.3.4 强制转化为右值
- 3.3.5 移动语义的一些其他问题
- 3.3.6 完美转发
- 3.5 列表初始化
- 3.5.1 初始化列表
- 3.5.2 防止类型收窄
- 3.6 POD类型
3.1 继承构造函数
派生类可以自动获得从基类的成员变量和接口,如果派生类需要使用基类的构造函数,通常需要在构造函数显示声明:
struct A { A(int) {} };
struct B { B(int i) : A(i) {} };
如果构造函数非常多,我们就需要把每个构造函数都需要写一遍,这样就很烦了,这种都属于“无用”代码,不能帮助有效理解代码而且让整个类比较乱。
3.1.1 使用using声明
在C++11之前using可以向如下使用:
struct A
{
void func(){}
};
struct B : A
{
using A::func;
void func(int a){} //其他版本
};
如上B类则继承来自A的func函数。
在C++11中这个想法被扩展到了构造函数上,子类可以通过使用using声明来声明继承基类的构造函数。
下面给出示例代码:
struct A
{
A(){}
A(int){}
A(string){}
};
struct B : A
{
using A::A;
};
B则全部拥有了来自A的不同类型的构造函数,另外更重要的一点,C++11标准将继承构造函数设计为“隐式声明”,意味着如果一个继承构造函数没有被使用,则相关代码不会被编译,不会产生真正的函数代码。
3.1.2注意继承构造函数使用过多造成的冲突问题
例如:
struct AA
{
AA(int a) {}
};
struct BB
{
BB(int a) {}
};
struct CC : AA, BB
{
using AA::AA;
using BB::BB;
};
如上使用,在类C中编译器或者在编译期都给给出错误提示:重复的构造函数声明,所以此时只能显式写出相应的构造函数。
最后注意,如果使用了继承构造函数,编译器就不会再为派生类生成默认构造函数了。
3.2 委派构造函数
委派构造函数的任务委派给了目标构造函数来完成这样一类构造的方式。
struct Base
{
public:
Base() {}
Base(int i) : Base() {}
Base(double b) : Base() {}
private:
int i;
double b;
};
和大家想的一样,调用2个有参数的构造函数则会先调用无参数的构造函数。
3.3 右值引用:移动语义和完美转发
3.3.1 指针成员与拷贝构造
主要注意类拷贝的时候,指针成员的深拷贝问题,但是这里深拷贝也会带来一些性能问题,比如指针指向的内存十分大,就会非常消耗内存。
3.3.2 移动语义
我们看一个类:
struct HasPtrMem
{
HasPtrMem() :d(new int(1)) {
cout << "construct" << endl;
}
HasPtrMem(const HasPtrMem& p) : d(new int(*p.d)) {
cout << "copy construct" << endl;
}
int *d;
};
HasPtrMem getTemp()
{
HasPtrMem h;
cout << "func:" << __func__ << " address:" << std::hex << h.d << endl;
return h;
}
int main()
{
HasPtrMem a = getTemp();
cout << "func:" << __func__ << " address:" << std::hex << a.d << endl;
getchar();
return 0;
}
理论上HasPtrMem a = getTemp();会发生以下步骤的代码:
- 创建一个对象h
- h对象通过getTemp返回赋值给一个临时的对象(此时调用拷贝构造函数)
- 该临时对象通过拷贝构造函数构造a对象
我们可以看到打印(特别说明,以上理想情况被编译器处理后可能就看不到了):

但是C++11中提供了一种方法,“偷走”临时变量中资源的构造函数,这就被称为“移动构造函数”,这种“偷”的行为称之为:移动语义。
我们可以看下移动构造函数的样子:
HasPtrMem(HasPtrMem&& p) : d(p.d) {
cout << "move construct" << endl;
}
运行之后可以看到:

可以看到直接把申请的内存“偷”走了。
3.3.3 左值、右值与右值引用
一个典型的判断左值右值的方法:出现在等号的左边就是左值,在右边可以称为右值。
或者可以取地址的、有名字的就是左值,否则不能取地址的、没有名字的就是右值。
例如:
a = b + c
&a是可以通过的,但是&(b + c)则不能通过编译。所以a是左值,b + c是右值。
C++中右值有两个概念构成,将亡值和纯右值。
纯右值就是C++98中右值的概念呢,将亡值则是C++11新增的跟右值引用相关的表达式,这样的表达式通常是将要被移动的对象(移为他用),比如返回右值引用T&&的函数返回值,std::move的返回值,或者转换为T&&的类型转换函数返回值。
所有的值都必须是左值,将亡值,右值三者之一。
例如:
T&& a = returnRValue(); //返回一个右值
//但是以下方式就会出错
int c;
int &&d = c;
我们可以使用以下方式完成一个右值引用的函数:
void acceptRValueRef(Copyable && s)
{
Copyable news = std::move(s);
}
在这里我们使用了std::move来强制让一个左值成为了右值!当然我们使用移动语义的前提是需要添加一个右值引用类型为参数的移动构造函数,否则就会调用默认的拷贝函数。
下面的表很好的说明了各种引用类型的含义和使用。

我们可以通过:is_rvalue_reference、is_lvalue_reference、is_reference来判断一个类型是否是引用类型。
3.3.4 强制转化为右值
C++11中提供了一个函数std::move它唯一的功能就是把一个左值转换为右值引用,之后我们可以通过右值引用该值,以用于移动语义。从实现上讲,std::move基本等同于一个类型转换:static_cast。
特别注意的是被转换为左值之后,其生命周期并没有随着左右值转化而改变。
为了保证移动语义的传递,程序员在编写移动构造函数时候,应该总是记得使用std::move来转换拥有形如堆内存、文件句柄等资源成为右值,这样成员支持移动构造,就可以实现其移动语义。
3.3.5 移动语义的一些其他问题
实现移动语义一定要注意排除不必要的const关键字。
C++11中,拷贝和移动构造函数实际上有以下3个版本。
T object(T&)
T object(const T&)
T object(T&&)
另一个点就是关于移动构造的异常问题。
因为可能移动语义没有完成,却抛出了异常,可能就会导致例如指针没有被正确移动。
3.3.6 完美转发
完美转发:函数模板中,完全依照模板参数的类型,将参数传递给函数模板中调用的另一个函数。
template<typename T>
void IamForwording(T t) {func(t);}
我们希望IamForwording作为一个转发函数模板,如果传入对象是左值,那么函数体就可以获取到左值,同样可以获取到右值。
C++11中引用了一条规则:引用折叠,结合新的模板推到规则完成完美转发。
例如在C++11之前如下代码编译是有问题的:
typedef const int T;
typedet T& TR;
TR& val = 1;
引用折叠就是将复杂的未知表达式折叠为已知的简单表达式。
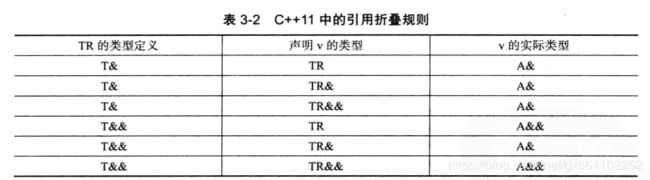
一旦定义中出现了左值引用,那么引用折叠总是优先将其折叠为左值引用。
通过以上规则我们可以将刚刚的抓发函数修改为:
template<typename T>
void IamForwording(T&& t) {func(static_cast<T&&>(t));}
当然我们传入左值,最后参数类型就是T& &&t折叠后还是左值,当然我们此时的static_cast是留给右值的,如果不是static_cast就会有问题了。
对于一个左值如果我们想要用右值转换掉,那么我们可以使用std::move通常它的实现就是一个static_cast,不过在C++11中用于完美转发的函数不再是move,而是:forward。所以最终我们的函数可以改写成如下方式:
template<typename T>
void IamForwording(T&& t) {func(forward(t));}
3.5 列表初始化
3.5.1 初始化列表
C++11提供了多种新的初始化方式比如:
//C++11的初始化方式
int arr[] = {1,2,3};
int b[]{4,5,6};
vector<int> c{ 7,8,9 };
map<int, double> d{ {1,2.3},{3,4.5} };
不仅如此,在C++11中集合(列表)的初始化方式已经成为C++语言的基本功能,这种初始化方式成为“初始化列表”。下面也是C++11初始化列表支持的方式:
//自动变量和全局变量的初始化被丰富了
int e = 3 + 4;
int f = { 3 + 4 };
int g{ 3 + 4 };
int h(3 + 4);
//也可同理获得堆内存new的操作符
int* i = new int(1);
double* j = new double{ 1.25f };
标准总是倾向于使用更为通用的方式来支持新特性,标准模板库对于初始化列表的支持来自于initializer_list类模板支持,见下面的例子:
enum Gender { Boy, Gril };
struct People
{
People(initializer_list<pair<string, Gender>> list)
{
std::copy(list.begin(), list.end(), std::back_inserter(data));
}
vector<pair<string, Gender>> data;
};
People ps{ { "Jenny", Gender::Boy },{ "Make", Gender::Gril } };
同样的initializer_list也可以用于普通的函数入参。
3.5.2 防止类型收窄
类型收窄一般是一些可以使数据变化或者精度丢失的隐士类型转换。
例如int a= 1.2 这里a实际值是正数1,可以视为类型收窄。
C++11中对类型收窄做了特别的处理如下:
//防止类型收窄
const int x = 1024;
const int y = 10;
char a = x; //类型收窄 可以通过编译
char* b = new char(1234); //类型收窄 可以通过编译
char c = { x }; //收窄 无法通过编译
char d = { y }; //不收窄 可以通过编译
unsigned char e{ -1 }; //收窄 无法通过编译
float f{ 7 }; //可以通过编译
int g{ 2.0f }; //收窄无法通过编译
3.6 POD类型
POD类型,也就是一个普通的类型(plain),他可以和C(old)兼容,所以可以使用memcpy函数进行复制,使用memset进行初始化。C++11将POD类型划分为两种含义:平凡的(trivial)和标准布局(standard layout)。
一个平凡的类或者结构体应该符合以下定义:
- 平凡的默认构造函数和析构函数
- 平凡的拷贝函数和移动构造函数
- 平凡的拷贝赋值运算符和移动赋值函数
- 不能包含虚函数及虚基类
另外:C++11可以通过template判断是否是一个平凡的类型。
POD包含的另一个概念是标准布局,符合以下定义的类或者结构体属于标准布局:
-
所有非静态成员拥有相同的访问权限
-
派生类有非静态成员,且只有一个仅包含静态成员的基类
-
基类有非静态成员,派生类没有非静态成员
言外之意,非静态成员只要同时出现在派生类和基类间,则不属于标准布局。 -
类中第一个非静态成员的类型与其基类不同
-
没有虚函数和虚基类
-
所有非静态数据成员均符合标准布局类型,其基类也同理。
C++11中借助:template判断一个类型是否是标准布局类型
POD在C++11中定义就是平凡的和标准布局
C++11中借助:
为什么要有POD类型?
- 字节赋值,代码可以安全的使用memcpy和memset进行POD的类型初始化和拷贝操作。
- 提供和C内存布局兼容。C++程序可以和C函数进行互相操作,因为POD类型的数据在C和C++之间的操作总是安全的。
- 保证了静态初始化的安全有效,静态初始化很多时候都能提高程序性能,