『MTCNN』2万多字教科书式详解
发现一篇关于MTCNN的博文,本来打算自己写一篇的,但看了这篇,我觉得不用我再写了,转载跟大家分享一下
尊重原创,转载自:https://blog.csdn.net/sinat_39783664/article/details/104269314
『MTCNN』2万多字教科书式详解
本文详细讲解了人工智能深度学习中最经典的神经网络之一:MTCNN。2万多字的内容,主要从理论和实践两方面对MTCNN进行详细分析,堪比教科书。话不说,开始你的旅程吧!
目录:
- 基础闲聊
- 人脸识别思想
- MTCNN理论分析
- 项目代码详细分析
一.基础闲聊
1.识别:
(1)数字识别:理想状态。图像大小一致,干扰项(噪声)很少;
(2)人脸识别:现实状态。
2.在视频识别中。
1秒帧,即24张图片。
3.打卡机识别人数有上限。
少的:50-70人;多的:100-200人。
4.熟人识别。
火车站、门禁等。目前,熟人识别只能做到百分之80多。
5.陌生人识别。
价值高。
6.公司。
旷世科技、商汤科技。
7.IOU
重点、难点。
8.NMS
重点、难点。
9.特征图的反向运算
重点、难点。
二.人脸识别思想
(1)人脸检测
追踪图片中的人脸。
(2)特征提取
取出人脸部分,放入神经网络,提取特征,得到特征向量。
(3)人脸对比
使用特征向量和现有注册库中的人脸特征做对比。做余弦相似度对比。
注:其中,人脸检测最重要。
三.MTCNN理论分析
1.神经网络历史简介
2.神经网络历史
(1)RCNN变种
- RCNN–>fast RCNN–>faster RCNN–>YOLO ( V1、V2、V3 )
其中,YOLO v3
-
YOLO V2–>YOLO9000(可以识别9000个物体)
-
YOLO–>SSD
3.特点
网络小、计算快、笔记本CPU训练
4.级联
-
分解
-
串联
5.研发院
中国科学院深圳先进技术研究院,乔宇老师组
6.损失和模型
(1)损失:
神经网络中最重要的部分是损失。损失解决了,神经网络项目问题就基本解决的90%。损失是解决问题的最终目标。有价值的论文是在设计损失上钻研;灌水论文只专注的模型上,论文价值不高。
(2)模型:
提高网络精度。
7.图像跟踪
(1)单目标跟踪
在一副图像上需要寻找的目标只有一个。单目标追踪的方法有两种:
-
在图像上找到目标所在区域的左上角和右下角共四个坐标值。
-
简单、实现容易、被大多网络使用。
-
输出四个值:左上角、右下角点。样本标签也这样做。
-
-
在图像上找到目标所在区域的中心点和宽与高共四个坐标值。
-
缺点:中心点对框的影响大;中心点和宽高的计算量大:首先需要找到左上角点和右下角点,然后再计算得到中心点。
-
优点:假如中心点在图片外边,即图片中有部分追踪物体(如:半只猫)。这样的情况需要在样本中做特殊处理,但是在通常情况下,追踪半只目标很少。
-
(2)多目标跟踪
-
三个目标跟踪
-
解决方法
三组值,每一组值(四个坐标点)代表一个目标。使用三组值框选三个目标。
-
存在问题
只框中一个目标。如下图1。如:选苹果一样,三个人总会选最大的一个苹果。
-
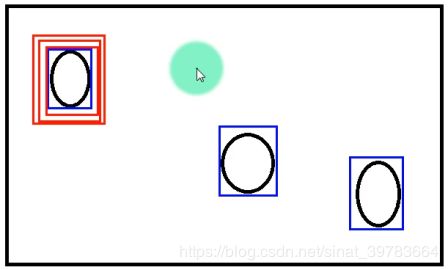
- 问题解决
这个问题不应该从标签出发解决。如,在街上进行人识别,街上有建筑物、车辆等很多背景,再这样的环境中识别出来人是因为人具有人的特征。同理,让神经网络在一张图片上识别有多少人,并且找到人的位置。怎么找到的呢?是因为人有特征,特征有共性。所以,在多目标追踪过程中,简化问题为,让神经网络认识是人和不是人就行,即,只需要让神经网路训练提取人的特征就行。因此,不应该拿一堆人训练网络,只需要网神经网络做一件事即可,即提取人的特征就好,即拿一个人训练网络。在输出值中,置信度(0-1)表示是不是人,属于二分类问题。其余四个值为坐标。当有人脸时,置信度靠近1,此时,输出有意义的坐标值;当置信度靠近0,输出的坐标值没有意义,输出四个0即可,四个0没有意义。
三个框框会框到同一个目标是因为三个框没有关系。当将问题想成拿苹果,三个人拿三个苹果,该三个人排队,一人拿一个苹果,这样问题就解决了。同理,给三个框排序,当某一个框被框了,下次不能框这个目标,只能框剩余目标。
-
多个目标跟踪
- 解决思想
当问题换成10个、多个目标,使用循环思想可解决。首先,设计一个网络,将网络训练好,输出五个值,一个置信度和四个坐标值;然后,拿来网络使用,当框到一个人脸时,接下来使用循环思想继续框剩余人脸。
使用过程中,从左上角开始,过程如下图2。这种扫描方法类似于卷积,但是很有可能将一张脸分成两部分,如下图3所示。造成这样的问题是步长。解决方法是,对第一次结果做偏移,如图4、5所示。其实步长就是一种偏移,步长给小一点。这是会遇到一个脸会被框很多次,如图6所示,解决放下放在下文。这时我们给的框是固定框,存在的问题是,有些脸比较大,如图7所示,这里的解决办法有两种:多建议框、图像金字塔。多建议框:使用很多框进行扫描。准备一组框(图8),且每个框有三种大小,共9个框(YOLO使用多建议框),使用正方形可以框人脸,电线杆等使用竖行框。图像金字塔:固定框,框不变,缩放图像,当图像缩放到和框一样大小,停止缩放。缩放代码使用while循环实现。







- 整体过程
从左到右扫描图像–>步长不要过大–>人脸过大在MTCNN中使用图像金字塔解决–>当步长过小一个脸会被框很多框–>使用NMS解决,保留置信度较高的框
- 温馨提示
30x30的人脸可以识别,在于样本的制作。如图9所示。
现实生活中不会存在的情况,如图10所示,排除PS情况。
NTCNN中建议框大小最小为12x12还小的脸(最低下限),如图11中12x12的人脸放大2850倍。
MTCNN做人脸比较适合。
使用训练好的网络识别人,使用置信度和四个坐标值是识别的依据,接下来往网络中输入图片区域,然后使用金字塔手段缩放原图进行人脸识别,然后将人脸框出来,每次是从原图中裁剪一部分放进网络中进行识别,缩放时按照最短边进行缩放(按照最大边进行缩放时不能整除),缩放技巧为使用最短边,缩放结果如图12所示,步长为2进行平移框扫描(当原图最短边为12时停止缩放)。
训练简单,使用较难。




8.IOU
-
重叠度算法。
-
计算两个框的重叠度。
-
交集/并集。
(1)目的:
分框。
(2)作用:
识别是否为一堆框。如图13。当IOU为0,表示不是一堆框。

(3)交集计算:
简单计算如图14中左图,使用角点坐标可简单计算。难点在于图14中右侧计算交集:首先计算相交点的坐标,再计算交集面积。
找一种通用方法为:图15,如下所示:
-
交集左上角点坐标:两个原框中左上角X和Y各自取较大值;
-
交集右下角点坐标:两个相交原框中右下角X和Y各自取较小值。
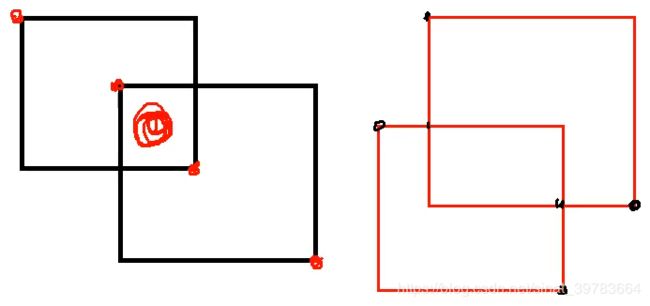

(4)并集计算:
两个矩形面积相加减去交集面积。即,算并集,首先得计算交集(如图14)。右下角-左上角的x和y,计算面积。
(5)使用场景:
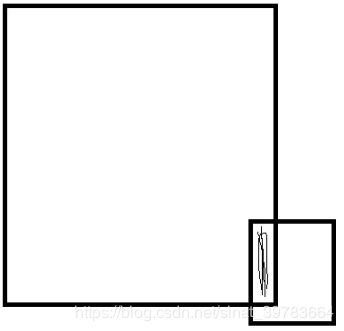
- P、R网络结果使用IOU,因为这两个网络精度较低,保留大框套小框的结果如图16所示。

- O网络中不使用IOU,使用交集/最小面积=1(置信度为1),去除套在大框里的小框。
(6)算法实现理论:
一个框和一堆框比较。
- 如何计算一堆框的面积?
答:如图17中,使用(第三列数据减去第一列数据)*第四列数据减去第二列数据。使用矩阵快速计算。
- 如何取出列数据?
答:切片。(box[:,2]-box[:,0])* (box[:,3]-box[:,1])

(7)代码:
import numpy as np """IOU""" def iou(box,boxes,isMin=False):#框的格式定义为:[X1,Y1,X2,Y2,C]。一个框和一堆框做比较。为了区分交集是与并集作比较还是和最小面积做比较,先将最小面积赋予默认值0. #计算每个框的面积 box_area=(box[2]-box[0])*(box[3]-box[1])#先计算box的面积。一个框的面积计算:(X2-X1)*(Y2-Y1)。索引拿到坐标值:(box[2]-box[0])*(box[3]-box[1]) boxes_area=(boxes[:,2]-boxes[:,0])*(boxes[:,3]-boxes[:,1])#一堆框的格式:[[],[],[],[],[],...]"""计算交集面积""" xx1=np.maximum(box[0],boxes[:,0])#左上角X。交集左上角点坐标:两个相交原框中左上角X和Y各自取较大值,作为交集左上角坐标。用于比较的框的左上角x值:box[0];被比较的框的左上角x值:boxes[0]。去两者较大值。 yy1=np.maximum(box[1],boxes[:,1])#同理.左上角Y。 xx2 = np.minimum(box[2], boxes[:, 2]) # 同理.右下角X。 yy2 = np.minimum(box[3], boxes[:, 3]) # 同理.右下角Y。 #判断是否有交集 w=np.maximum(0,xx2-xx1)#当xx2-xx1的值为负值时,表示没有交集,将没有交集的结果变成0即可。使用maximum函数取较大值。 h=np.maximum(0,yy2-yy1)#同理。 #计算交集面积 inter=w*h if isMin:#如果isMin为True,表示除以最小面积。 over=np.true_divide(inter,np.minimum(box_area,boxes_area))#true_divide:除法。isMin为True时,除以最小面积。如何得到最小面积呢?比较box_area和boxes_area,取最小值就可得到最小面积。 else:#否则,除以并集面积。 over = np.true_divide(inter, (box_area+boxes_area-inter))#两个矩形面积相加减去交集面积 return over
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
9.阈值
当大框套小框,且有重叠度,此时IOU较小,图18,给阈值,如0.3,当IOU大于0.3,视为一堆,当IOU小于0.3,视为两堆数据。
(1)目的
继续分框。
10.NMS
(1)目的:
去出多余框。
(2)思想
图19。首先,将置信度进行排序;然后,使用最大值与其余值进行IOU对比;0.98和0.83的IOU值大,框到的是同一物体,删除0.83;接着,对0.98和0.81做IOU,值为0,是两个物体,保留;依次进行,最后保留0.98、0.81、0.67;接下来,使用0.81和0.67进行IOU比较。最终结果如图20所示。
如:0.98 0.83 0.81 0.75 0.67
NMS是在每张图上做的,由于有金字塔的原因,固在使用NMS后回保留很多框。


(3)NMS算法代码:
将一堆框按照置信度排序;
取出第一个框。当一堆框中维度小于等于1时,表示取完;
将取出的第一个框保存起来;
同时,保留剩余的框;
比较IOU。
"""NMS""" def nms(boxes,thresh=0.3,isMin=False):#需要所有框、阈值、最小面积(传到IOU中,因为IOU是放在NMS里边计算的) #根据置信度从大到小排序。 _boxes=boxes[(-boxes[:,4]).argsort()] #得到一堆按照置信度排序的框 #框的格式定义为:[[X1,Y1,X2,Y2,C],[],[],[],[],...]。#保留剩余的框 r_boxes=[] #取出第一个框。因为要取很多次,使用循环。(重点) while _boxes.shape[0]>1:#循环取出第一个框(shape[0]),当循环过程中取出的维度大于1,说明有框;当维度小于1,表示框已经取完,循环结束。 #取出第一个框 a_box=_boxes[0] #取出剩余框 b_boxes=_boxes[1:] #保留第一个框 r_boxes.append(a_box) #比较IOU后,保留阈值较小的值 index=np.where(iou(a_box,b_boxes,isMin)<thresh)#将iou于阈值作比较:iou(a_box,b_boxes,isMin)<thresh,如果iou小于阈值,保留。使用np.where,当小于为True。 _boxes=b_boxes[index] #保存结果 if _boxes.shape[0]>0: r_boxes.append(_boxes[0]) #组装为矩阵 return np.stack(r_boxes)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
11.坐标值激活函数的使用
- Softmax:
- 损失函数不能用Softmax。值域不满足需求(大于1);
- Softmax排他性。输出为概率分布,其和为1,输出结果之间是有关系的。本网络输出结果是由中心点和宽高组成的,四个值之间没有关系。
-
ReLU:
-
值域不满足。当跟踪对象靠近图片边缘,且一大半在图片外部,图片中只保留一部分跟踪对象,此时跟踪对象中心点在图片外部,中心点为负值,ReLU函数没有负值。
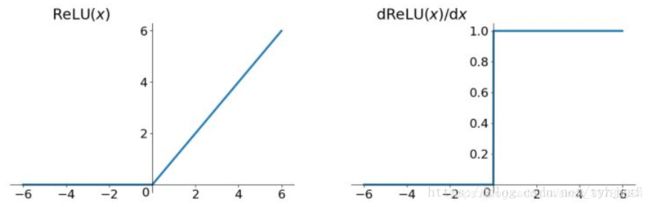
-
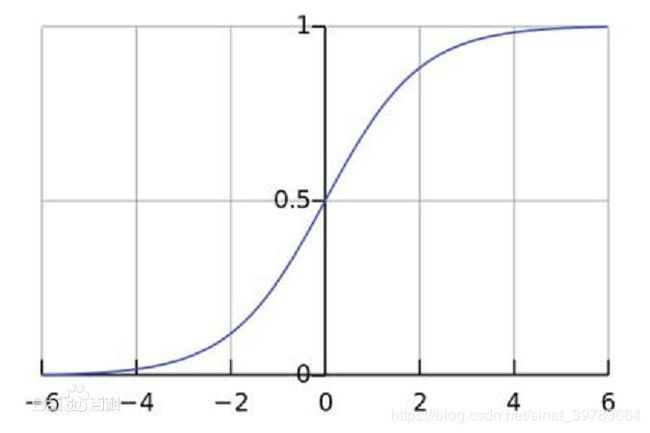
Singmod:
-
同理,singmod也没有负值。值域为0-1之间,但是给本网络输出值做归一化即可,但因结果有负值,固不能用。

-
Tanh:
-
Tanh有负值,有激活,改变了值,也不用(勉强可以用)。
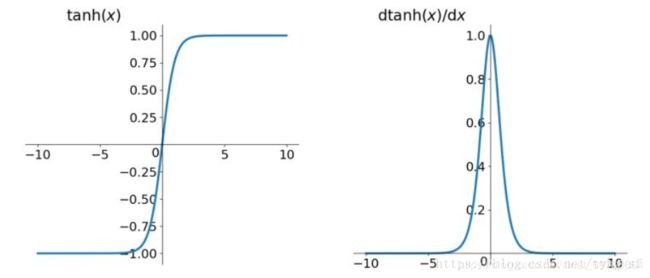
- 最好用Y=X。不激活
12.程序编写方法
使用矩阵(并行)代替for循环(串行)计算,提高计算速度。例如:矩阵一次可计算所有建议框的面积。
13.特征图的反向运算
(1)基本思想
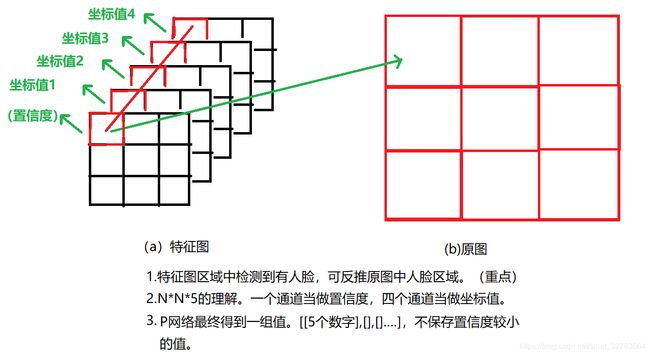
使用MTCNN进行人脸识别时,将网络当做卷积核进行图像扫描,网络输入大小相当于在图像上逐个寻找有人脸的区域,这个区域叫做建议框。建议框中有没有人脸是通过5个值进行判断的,1个置信度,4个坐标点值。当置信度接近1,说明建议框有人脸。在逐个移动建议框的时候,为了更大可能不错过有人脸的区域,需要将建议框重叠,这就要设置步长大小。有了步长,建议框最后会得到一大堆(暂不说金字塔引起的建议框数量增加)。因为最终要得到一个人脸有一个建议框,就需要使用IOU和NMS进行减去大多置信度不高的建议框。在IOU和NMS的计算过程中都要计算IOU,而IOU的计算是两个建议框的交集除以并集,并集的计算过程中用到计算两个建议框的面积大小(交集的计算是直接通过相交部分左上角和右下角坐标值计算,上文有详细说明;并集的计算是通过计算两个建议框的面积和,然后减去交集面积)。在计算面积时,首先要知道建议框左上角和右下角坐标值。下面,我们就通过网络计算得到的特征图反向求解原图中建议框左上角和右下角坐标值。
(2)中间卷积一次的计算
-
理想状况。
假如,原图经过卷积得到2x2大小的特征图,卷积核大小为4x4,步长为3。如何反向计算原图大小?
解:
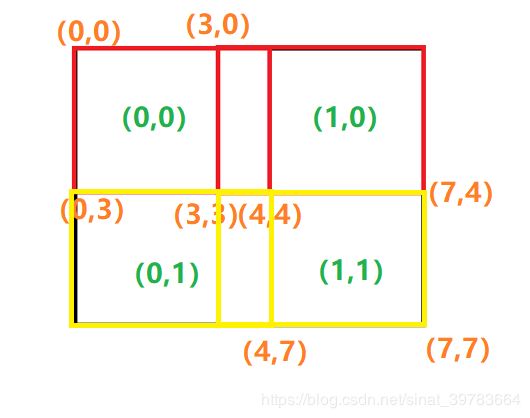
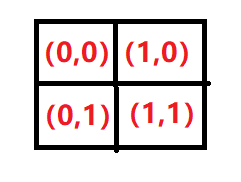
如下图25,(a)是原图;(b)是经过卷积之后得到的特征图,图中标有索引值,索引值(0,1)在原图中左上角坐标为(3,0),这里的3是步长;右下角坐标是(7,3),这里7是步长3+卷积核大小4,4是卷积核大小。

- 在反向计算原始图片位置是以坐标(x,y)显示的,x对应图片的w,y对应图片的h,即,图片格式为wh。但是,卷积得到的特征图结果是nchw格式,此时,需要将直接反算得到的坐标进行转换,即需要将索引转换位置。
解:
左上角点坐标:索引x步长。例如,索引(0,0)反向求解原图左上角坐标为:(0,0)*3=(0,0);索引(1,0)反向求解原图左上角坐标为:(1,0)*3=(3,0);索引(0,1)反向求解原图左上角坐标为(0,3);索引(1,1)反向求解原图左上角坐标为(3,3)。
右下角点坐标:索引x步长+卷积核大小。例如,索引(0,0)反向求解原图左上角坐标为:(0,0)*3+4=(4,4);索引(1,0)反向求解原图左上角坐标为:(1,0)*3+4=(7,4);索引(0,1)反向求解原图左上角坐标为:(4,7);索引(1,1)反向求解原图左上角坐标为:(7,7)。
注:如果有缩放,两个结果分别除以缩放比例。
(3)中间卷积多次计算
-
思想
-
将很多次卷积看称一次卷积(例如:两个33卷积代替一个55卷积),即将很多层神经网络看成一个大的卷积核。
-
卷积核大小等于原图大小。
-
大卷积核步长等于单个小卷积核步长的乘积。
(4)特征图反向计算的应用
使用网络卷积结果反向计算建议框大小。

14.网络结构
P—R—O网络相当于现实中面试过程中的HR—技术—主管
P网路处理时间短,处理时间最快,即网络小,精度低,不标准(寥寥草草决你你这人还行,没有思想上的大问题,健康状况好就行,总之,是个人就行),但是P网络在实际应用中画的时间最长(处理的数据量大);R网络精度较高(例如:面试中针对每个人要考量技术,技术难度本身难度较大),处理时间较慢;O网络处理时间长,网络最大,处理精度最高(理解时参考实际面试中,主管要跟面试的员工聊很久,不是一次就能决定的。主管会给你画一个很大的饼,慢慢去吸引你,给你“洗脑”。不是一时的事)。

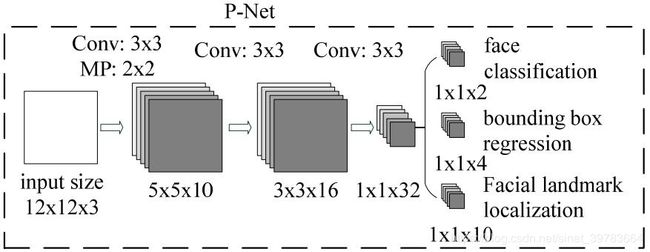
(1)P网络
- 网络设计
输入12X12,输出1X1,中间可看成12X12的卷积核。
- 首先,经过3x3的卷积核,步长为1,得到10x10的特征图;
- 再进过3x3的最大池化,步长为2(有一部分重叠,不丢的多,保留更多的信息),得到5x5大小的特征图;
- 再经过3x3的卷积核步长为1,得到3x3的特征图;
- 最后,再进过33的卷积核,得到11大小的特征图。
共3层3x3的卷积,第一层使用池化,最终得到1x1x32大小特征图。最后一层使用全卷积代替全连接(全连接融合通道,但是图片大小会受到限制。全连接将W和H相乘,会受到数据的影像。卷积神经网络格式为NCHW,全连接格式为NV,使用全连接时需要将CHW相乘)。
将最终结果输出为三类结果:第一,使用两个卷积核对1x1x32做卷积得到1x1x2,即置信度(原论文置信度使用Softmax激活得到两个置信度。建议使用1x1x1的结果,使用Sigmoid激活,这样得到一个值。因为置信度只要一个值,更改原论文,毕竟原论文发表较早,思想还是不够全面);第二,使用两个卷积核对1x1x32做卷积得到1x1x4,得到人脸四个坐标值(两个坐标点共四个值);第三,1x1x10的结果为原论文标出五官(两个眼睛,一个鼻子,一个嘴巴)关键点,眼睛两个点,鼻子一个点,嘴巴两个点(可先不考虑)。
-
网络使用
-
P网络最终得到1x1x1为置信度,1x1x4为脸部坐标值。两者分别对待,分别使用激活函数。训练置信度和训练坐标所使用的数据集是不同的。训练置信度是二分类问题,训练时使用有人脸和没有人脸的数据集。训练坐标点时,需要数据集全部有脸,只是脸的坐标值不一样。
-
四个坐标点使用什么激活?(前文有讲解)
不能使用Softmax函数激活,该函数有排他性。四个坐标点不应该有联系,该函数输出值和为1。Sigmoid值域(只有正值)不满足,当只有部分人脸时,会有坐标值在图片外部,出现负值,但是将负值归零可使用,又但是,半张人脸和一张人脸的训练过程中是不一样的概念。样本一般为整张人脸,此时,坐标就会产生负值。Tanh、ReLU、Y=X三个激活函数可以使用,Y=X最好,因为结需要具体的坐标点,网络算出来的值是什么,就使用什么值。Tanh虽然值域满足,但是对值做了变形。ReLU对负半轴对结果做了变形。
- 图片格式为坐标值时如何进行归一化?
用坐标值除以最长边的边长值。
- 图片格式为像素值时如何进行归一化?
像素值除以255。即,除以最大值。
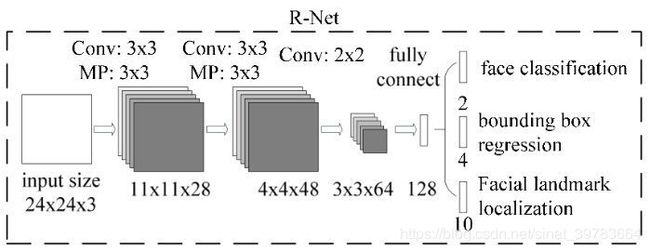
(2)R网络
- 首先,使用3x3的卷积,步长为1;
- 3x3的池化,步长为2;
- 接着,使用3
- 3x3的池化,步长为2;
- 继续,使用2x2的卷积,;
- 最后跟一个全连接层。
因为R网络输入大小固定,输入是P网络处理之后的结果,将全连接换成全卷积也没问题。R网络相比P网络更大,权重更多,精度更高。最终,输出结果为1个置信度,4个坐标点。
(3)O网络
将R网络处理之后的结果交给O网络。O网络中使用四个卷积层,三个池化层,相比R网路更大。最终,输出一个置信度和两个坐标点(四个值)。

(4)提示
-
P网络相当于12*12的卷积核。
P网络12x12的输入是指建议框,每次扫描12x12的区域。当将输入12x12更改为14x14,但因为中间三层3x3的卷积层相当于12x12的卷积核,固,更改输入大小也不会更改网络的本质(12x12)。建议框大小等于卷积核大小,即12x12的卷积核。
-
如果输入P网络图片大小为13x13,P网络输出大小为2x2x32(有填充)。原始结果1x1x5有5个值,输入图片大小为13x13时,输出有4x5个值,即将图片分成四个区域。如果输入一张图片得到NxNx32大小的特征图,即得到Nx5的形状(一个NxNx1(置信度)和一个NxNx4(四个坐标值)),即将输入图片扫描了5次。换句话,输入任意大小图片,P网络以12x12的卷积核进行扫描,得到NxNx5的值,此时,要检查每个区域中5个值(置信度,坐标值)来判断有没有人脸。

- P网络使用12x12大小的建议框进行人脸扫描时,如果建议框中有人脸,就会框出人脸区域。如图26所示。实景情况会框处很多框(与步长有关)。框处的人脸有很多种情况,如:部分人脸,整个人脸(正方形&长方形)。将结果(P网络处理后的结果,框处的区域,如图27所示)交给R网络,做为R网络的输入数据。P网络得到的框框大小不一致,原论文中R网络只能接收24x24大小的输入,因此,需要将P网络的输出结果变换为24x24大小。不能使用resize,会失真;使用按比例缩放(H和W按照一定比例同时缩放),结果小于24x24,然后使用填充(第一种填充方法:保证人脸在中间,给两边进行填充;第二种填充方法:首先,生成24x24的白色图片,然后将框出来的图片进行最长边压缩到24,最后放进白色图片中。)。
- P网络到R网络的整个过程是:P网络得到一堆框,即一堆数据,以这堆数据在原图上抠出框出区域,然后进行形状变换,输入R网络。
- R网络到O网络的整个过程是:R网络输出结果与P网络得到结果一样(一个置信度,两个偏移量),得到之进度大的值,然后扣出原图,进行缩放为48x48,输入进O网络。


- 三个网络输入大小不一样有什么道理?
P网络精度最低,R网络精度稍微高,O网络精度最高。因此,网络输入特征图的大小是逐渐增大的,加大计算力度,增加计算精度。
- R和O网络如何反算原图位置?
与P网络反算相同。如图28所示为三个网络框到的结果
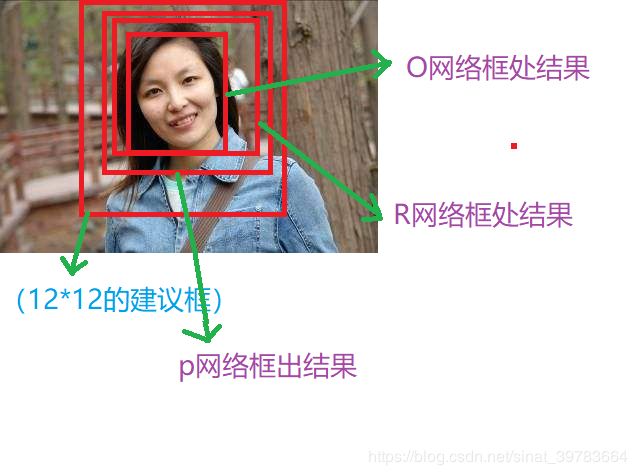
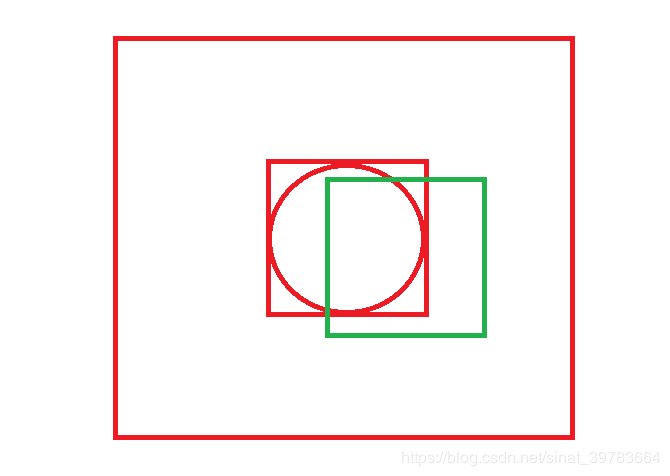
- 偏移量替换坐标点。
在网络中使用偏移量代替坐标值。如图37所示,绿色框表示建议框,红色框表示实际框。为什么使用偏移量?1)在使用图像金字塔进行图片缩放时,求坐标点的意义不大,偏移量具有意义,换言之,将图片进行缩放后,坐标点不可用,但偏移量依然可用;2)偏移量容易做归一化,坐标值不好做归一化。偏移量如何计算?实际框左上角相对于建议框左上角,实际框右下角相对于建议框右下角计算偏移量(P网络结果实际框对应的建议框为12x12,R网络结果实际框对应的建议框是P网络的实际框,O网络结果的实际框对应的建议框是O网络的实际框;实际框偏移量的参考点不全参照建议框左上角点,是因为实际框右下角点的坐标值较大,相对于建议框左上角点值会得到较大值,使用较大值除以建议框对应边长会得到较大商,不能达到归一化效果)。如图37中, b点的偏移量:X的偏移量为(Xa-X1)/W,Y的偏移量(Ya-Y1)/H。当神经网络训练好,得到的结果是偏移量。如何反算实际框中原始影像位置?b点处为X为:Xa-偏移量W,Y为:Ya-偏移量*H。

-
偏移量的使用:
训练和使用。
-
偏移量代码如下:
# 计算坐标的偏移值
offset_x1 = (x1 - x1_) / side_len
offset_y1 = (y1 - y1_) / side_len
offset_x2 = (x2 - x2_) / side_len
offset_y2 = (y2 - y2_) / side_len
- 1
- 2
- 3
- 4
- 5
15.网络训练
(1)三个网络
可单独训练。
(2)两个损失 :
一个用于求置信度,一个用于求偏移量。
-
置信度:
标签用0(没有人脸)和1(有人脸),所以,数据有两种:一组有人脸的数据和一组没人脸的数据。标签:0和1。
-
偏移量:
要求每幅图像上要有人脸,才会有偏移量。那么,有人脸的数据有什么区别呢?人脸的位置不一样,即,偏移量不一样。数据:正样本和部分样本。部分样本的偏移量较大。当神经网络在训练时训练了部分样本人脸,在使用网络进行人脸识别时,就会识别出框出来的部分人脸。图所示。
(3)训练数据集 :
Wider_face和celebA
- Wider_face数据集的使用情况:
人脸比较小,一张图片上有多张人脸,可以追踪较小的人脸。优点:使用Wider_face训练的网络进行较多人脸识别时,追踪的人脸只会多,不会少,召回率较大。缺点:训练数据集中人脸较小,识别精度较低,即误框几率较大。
- celebA数据集的使用情况:
优点:使用celebA训练的网络进行人脸识别时,精度较高。
缺点:但是,召回率较低,即,会丢弃较小的人脸,即,不能框到较小的人脸。
- 两种数据集因情况不同使用不同。
本例使用celebA数据集。
- 查看celebA数据集(正样本):
from PIL import Image,ImageDraw
import os
IMG_DIR = r"E:\Data\Data_AI\CelebA\Img\img_celeba.7z\img_celeba"#数据
AND_DIR = r"E:\Data\Data_AI\CelebA\Anno"#标签
#读图
img=Image.open(os.path.join(IMG_DIR,“000002.jpg”))
img.show()
#读标签,将标签位置画到图像上
imgDraw=ImageDraw.Draw(img)
imgDraw.rectangle((72,94 ,72+221 ,94+306),outline=“red”)#标签文本值:72 94 221 306:X1,X2,宽,高。转换为画图坐标值:72,94,72+221,94+306:X1,Y1,X2,Y2
img.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14


这个框偏大。即,celebA标签偏大,使用偏大标签数据训练得到的网络识别得到的框也是偏大的。在使用时,可手动将数据框调小(一般使用程序缩小,会有偏差),或者将偏移量调大。如果要做出高精度的结果,数据集需要买或者造。得到好的结果大约需要100万-120万张人脸数据。
- 查看Wider_face数据集:
数据标签的框较标准。但是,误框率较高(会框出一些头发、鞋子(红鞋子和红头发的误判)等当成人脸,误框)。
(4)样本增样:
- 理论:
已知正样本框,计算框的中心点;接着,沿着上下左右随机平移中心点,最大距离不超过:上下不超过高度的1/2,左右不超过宽度的1/2;接着,以平移之后的中心点生成正方形框(因为P、R、O三个网络的输入为正方形),框的边长最大不超过原有正样本最短边长,让正样本的边长在这样本区间随机变化。这样就可画出很多框,这些框的特点:有些框的人脸多,有些矿的人脸少。将这堆框当成正负样本。那么,怎样区分正负样本呢?使用IOU。将原始正样本框与这些框进行IOU比较。以下是原论文给出的建议IOU值:
0-0.3:非人脸(使用上述方法不能造出非人脸数据。)
0.65-1.00:人脸(正样本)
0.4-0.65:部分人脸(部分样本)
0.3-0.4:负样本
- 训练样本比例:
负样本:正样本:部分样本:地标=3:1:1:2
- 实际:
将原始框中心点在一定范围内随机平移;以平移后的点为正方形中心点,创建正方形;正方形的创造原则为:最小正方形边长为原框的宽和高中最小边的倍,最大正方形边长为原框的宽和高中最大边的倍(值偏大,可自行调整)。代码如下:
for _ in range(5): #让人脸中心有少许的偏离 w_=np.random.randint(-w*0.2,w*0.2) h_=np.random.randint(-h*0.2,h*0.2) cx_=cx+w_ cy_=cy+h_#让人脸形成正方形,并且让坐标有少许的偏离 side_len=np.random.randint(int(min(w,h)*0.8),np.ceil(1.25*max(w,h)))#np.ceil():向上取整 #正方形左上角坐标点 x1_=np.max(cx_-side_len/2,0) y1_=np.max(cy_-side_len/2,0) # 正方形右下角坐标点 x2_=x1_+side_len y2_=y1+side_len crop_box=np.array([x1_,y1_,x2_,y2_])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
-
制造负样本:
-
第一种方法:
在原始数据框以外的部分裁剪,作为非人脸,如图33所示。
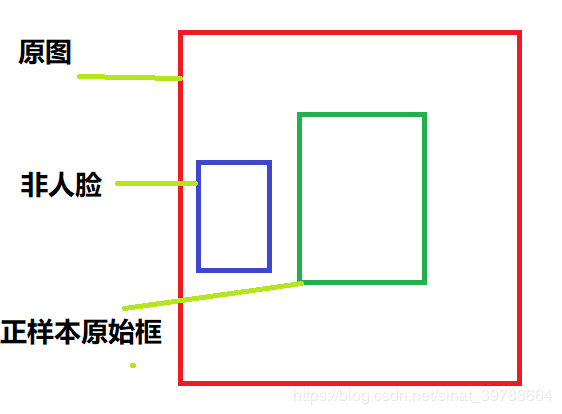
- 第二种方法:
根据样本增样方法增样。使用IOU划分负样本。
- 第三种方法:
单独增样。首先,设置一个范围值:最小值为:face_size,最大值为:图片最短边的一半。左上角坐标范围为:x1:0-图片宽度减去范围值,y1: :0-图片高度减去范围值。右下角坐标范围为:x2:x1+范围值,y2:y1+范围值。(这种方法有时会扣到部分人脸,有时会扣到完整人脸。可以调小IOU值,但是生成的负样本就会减少。)示意图如下:

for i in range(5): side_len = np.random.randint(face_size, min(img_w, img_h) / 2) x_ = np.random.randint(0, img_w - side_len) y_ = np.random.randint(0, img_h - side_len) crop_box = np.array([x_, y_, x_ + side_len, y_ + side_len])if np.max(NMS.iou(crop_box, _boxes)) < 0.3: face_crop = img.crop(crop_box) face_resize = face_crop.resize((face_size, face_size), Image.ANTIALIAS) negative_anno_file.write("negative/{0}.jpg {1} 0 0 0 0 0 0 0 0 0 0 0 0 0 0\n".format(negative_count, 0)) negative_anno_file.flush() face_resize.save(os.path.join(negative_image_dir, "{0}.jpg".format(negative_count))) negative_count += 1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 第四种方法:
爬虫任意图片,在图片上任意抠出来,作为非人脸数据。背景色要复杂。
- 温馨提示
使用celebA数据集,可制作负样本,不需要自己另行下载人脸图片制作部分样本数据,减少工作量。种方法即:样本增样。
- 样本情况
12x12大小的正样本、负样本、部分样本;24x24大小的正样本、负样本、部分样本;48x48大小的正样本、负样本、部分样本。三个网络可同时训练。
- 性能需求
可使用笔记本训练(每个网络结构非常小)。
-
标签情况:
-
标签:一个置信度和四个偏移量。
-
样本:正样本、部分样本、负样本。
-
置信度:正样本(1),负样本(0),部分样本(2)(随便给一个置信度值,保证格式一样)。说明:在训练置信度时,只使用正样本(1)和负样本(0)的置信度数值,不使用偏移量值;在训练迁移量时,只使用正样本(1)和部分样本(2)的偏移量值,不使用置信度值。固,给负样本置信度可随便赋一个值。编程上将数据分开。
-
造出数据格式为:


- 更改原论文:
不能使用原论文划定IOU值造样本。如下图45为使用原论文给定IOU值制造样本集得到的负样本里含有部分人脸。
- 负样本标签值:
- 部分样本标签值:
- 正样本标签值:

16.网络的使用
(1)详解
首先,对传入的一张图片(图50-(0)),做图像金字塔(P网络的输入大小为12x12,传入图片一般都大于12x12的尺寸,这时,对图像做金字塔处理,框选图片中较大的人脸。),得到一堆人脸,如图50-(1)所示;然后,将这一堆框传入P网络,得到图50-(2)中所示的一堆框(为什么会大框套小框?图像金字塔的影响。缩放越严重,得到的框越大);然后,经过NMS去掉部分框,NMS去掉的是每一张图片上的框,结果依然保留一堆框,但是比之前较少(图50-(3));接着,根据这堆框从原图上找出这对框的区域,并抠出原始区域,resize成24x24的正方形,再传入到R网络中,R网络再进行一次框选(图50-(4)),将框选的结果再做NMS,留下一堆框(图50-(5));接着,从这对框中找到R网络识别到的区域,并扣下来,resize成48x48的正方形,再传入到O网络中,0网络再进行一次框选(图50-(6)),得到一个框,将框画出来即可,不需抠图(图50-(7))。








(2)温馨提示
- P网络精度低:
因为在使用P网路之前将大于12x12的相片缩小,使得图片像素较低,固,网络识别精度较低。
- R网络精度较高:
R网络是在P网络框出来的区域放大,然后在放大后区域的原图上进行框选,像素高,识别精度固然提高。
- O网络精度最高:
同理,R网络的识别精度也提高。O网络的数据量最大(输入4848大小的图片),使得训练得到的网络精度最高。
- 问题1:对一副图片统一做完金字塔(图40-(1)),再到图40-(2)中是怎样对应到每一张图片上的?
答:首先,不是一起进行计算。在编程上,先传入P网络一张图片,接着做NMS留下一部分框(使用[[]]存储);接着,将图片给定一定缩放比例(如0.7),再传入P网络,得到一堆框(存储在[[],[]]中);接着,重复上述操作,最后保障在原图上画出一堆框(图40-(2));接着,传入R网络,R网络是基于P网络框出来的框上进行计算的;以此类推……
- 问题2:如何分组计算置信度和偏移量?
答:在一组值[X1,Y1,X2,Y2,C]…中,当计算置信度时,只取出C,当计算偏移量时,只取出X1,Y1,X2,Y2。
17.MTCNN优缺点
(1)优点
通用跟踪
(2)缺点
虚警高:容易将不是人脸的东西识别成人脸。最主要的原因在于:网络结构浅。用途:迅速将非人脸过滤掉,再使用其他网络。
四.项目代码详细分析
:观察样本数据–根据网络设计损失–整理数据–设计网络–训练训练–验证
- 观察样本数据:样本数据决定最终结果;
- 设计损失:损失设计出来,即项目大体设计完毕。(核心、难点)
- 整理数据:一般的,提供的数据不能满足自身需求。如:MTCNN中12x12、24x24、48x48中包含正样本、负样本、部分样本;
- 设计网络:设计网络结构。
- 训练网络:使用样本数据训练网络参数,使得参数达到最优。
- 验证:测试网络能否达到预期结果。
注:前三步最为重要。
1.整理数据
(1)样本存储路径:
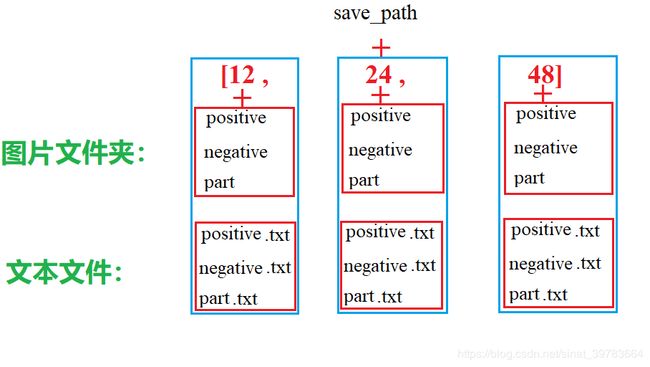
(2)在记事本创建文件:
open权限的w模式:如果存在文件,会覆盖;如果空文件,创建文件。
项目过程:制造样本–编写网络–制造数据集–
(3)完整代码
-
首先,定义一次性设计尺寸属性;
-
接着,声明图片存储路径。如果路径不存在,进行创建;
-
接着,声明标签存储路径;
-
接着,对三类样本分别计数。图片存储名称根据计数存储,保证不重复;
-
接着,读入标签文件。遍历每一行,且不读前两行;
-
接着,读取每行中的内容。读出图片名称;
-
接着,根据图片名称和图片路径读取图片;
-
接着, 造数据;
-
获取图片的宽和高。
-
获取建议框左上角点坐标。
-
获取建议框的宽和高。
-
得到建议框右下角点坐标。
-
五个关键点忽略。
-
过滤字段。排除过小的框。(排除样本中不标准的框。如果样本框小于40,学习到的人脸很不标准,训练出来的网络误框率很高,导致精度较低)
-
存储符合要求的四个坐标点。
-
计算人脸中心点点坐标。
-
随机产生样本数。
-
随机中心点的偏移值。
-
根据偏移值产生新的中心点。
-
制作正方形框,并且让框偏移,中心点为随机生成的中心点。
-
计算坐标偏移值。计算生成框与数据样本实际框的偏移量。
-
抠图,并进行缩放(根据12x12,24x24,48x48大小进行缩放)。
-
判断样本属于正样本、负样本还是部分样本?
- 将生成的框传入IOU中计算IOU值。
- 正样本:写入标签(置信度为1);保存图片。
- 部分样本:写入标签(置信度为2);保存图片。
- 负样本:写入标签(置信度为0);保存图片。(这样造出来的负样本很少,甚至得不到负样本)
-
单独生成负样本。
首先,设置一个范围值:最小值为:face_size,最大值为:图片最短边的一半。左上角坐标范围为:x1:0-图片宽度减去范围值,y1: :0-图片高度减去范围值。右下角坐标范围为:x2:x1+范围值,y2:y1+范围值。(这种方法有时会扣到部分人脸,有时会扣到完整人脸。可以调小IOU值,但是生成的负样本就会减少。)
-
存储样本。
-
关闭制造。
import os
from PIL import Image
import numpy as np
from MTCNN import NMS
import traceback
anno_src=r"E:\Data\Data_AI\CelebA\Anno\list_bbox_celeba.txt"#标签
img_dir=r"E:\Data\Data_AI\CelebA\Img\img_celeba.7z\img_celeba"#图片
save_path=r"E:\project_folder\project_AI\MTCNN\celeba1"#存放整理后的数据
for face_size in [12,24,48]:
print("gen %i image" % face_size)
#样本图片存放路径
positive_image_dir=os.path.join(save_path,str(face_size),"positive")
negative_image_dir=os.path.join(save_path,str(face_size),"negative")
part_image_dir=os.path.join(save_path,str(save_path),"part")
#判断三个文件夹是否存在,如果不存在,创建。
for dir_path in [positive_image_dir,negative_image_dir,part_image_dir]:
if not os.path.exists(dir_path):
os.makedirs(dir_path)
#样本标签存储路径
positive_anno_filename=os.path.join(save_path,str(face_size),"positive.txt")
negative_anno_filename=os.path.join(save_path,str(face_size),"negative.txt")
part_anno_filename=os.path.join(save_path,str(face_size),"part.txt")
#对三类样本分别计数,目的:用不重复的数编写图片名称。
positive_count=0
negative_count=0
part_count=0
try:
# open权限的w模式创建文本文件
positive_anno_file=open(positive_anno_filename,"w")
negative_anno_file=open(negative_anno_filename,"w")
part_anno_file=open(part_anno_filename,"w")
"""获取样本信息"""
#打开标签
for i ,line in enumerate(open(anno_src)):
if i<2:
continue
try:
"""读取图片"""
#拿出行文本间的内容
# strs=line.strip().split("")
# strs=list(filter(bool,strs))
strs = line.strip().split()
image_filename=strs[0].strip()#读取图片名称。strip():防止前后有空格
print(image_filename)
image_file=os.path.join(img_dir,image_filename)
"""造数据"""
with Image.open(image_filename) as img:#打开图片
img_w,img_h=img.size#获取图片的宽和高
x1=float(strs[1].strip())
y1=float(strs[2].strip())
w=float(strs[3].strip())
h=float(strs[4].strip())
x2=float(x1+w)
y2=float(y1+h)
#5个关键点(暂不要求做)
px1=0#float(strs[5].strip())
py1=0#float(strs[6].strip())
px2=0#float(strs[7].strip())
py2=0#float(strs[8].strip())
px3=0#float(strs[9].strip())
py3=0#float(strs[10].strip())
px4=0#float(strs[11].strip())
py4=0#float(strs[12].strip())
px5=0#float(strs[13].strip())
py5=0#float(strs[14].strip())
#过滤字段(排除样本中不标准的框。如果样本框小于40,学习到的人脸很不标准,训练出来的网络误框率很高,导致精度较低)
if max(w,h)<40 or x1<0 or y1<0 or w<0 or h<0:
continue
boxes=[[x1,y1,x2,y2]]#存储符合要求的坐标点
#计算出人脸中心点位置
cx=x1+w/2
cy=y1+h/2
#使正样本和部分样本数量翻倍
for _ in range(5):
#让人脸中心有少许的偏离
w_=np.random.randint(-w*0.2,w*0.2)
h_=np.random.randint(-h*0.2,h*0.2)
cx_=cx+w_
cy_=cy+h_
#让人脸形成正方形,并且让坐标有少许的偏离
side_len=np.random.randint(int(min(w,h)*0.8),np.ceil(1.25*max(w,h)))#np.ceil():向上取整
#正方形左上角坐标点
x1_=np.max(cx_-side_len/2,0)
y1_=np.max(cy_-side_len/2,0)
# 正方形右下角坐标点
x2_=x1_+side_len
y2_=y1+side_len
crop_box=np.array([x1_,y1_,x2_,y2_])
#计算坐标的偏移值
offset_x1=(x1-x1_)/side_len
offset_y1=(y1-y1_)/side_len
offset_x2=(x2-x2_)/side_len
offset_y2=(y2-y2_)/side_len
#五个关键点(暂不考虑)
offset_px1=0 # (px1-x1)/side_len
offset_py1 = 0 # (py1-y1)/side_len
offset_px2 = 0 # (px2-x2)/side_len
offset_py2 = 0 # (py2 -y2 )/side_len
offset_px3 = 0 # (px3-x3)/side_len
offset_py3 = 0 # (py3-y3)/side_len
offset_px4 = 0 # (px4-x4)/side_len
offset_py4 = 0 # (py4-y4)/side_len
offset_px5 = 0 # (px5 -x5 )/side_len
offset_py5 = 0 # (py5-y5)/side_len
#裁剪下图片,并进行缩放
face_crop=img.crop(crop_box)#crop:抠图
face_resize=face_crop.resize((face_size,face_size))#缩放到12*12、24*24、48*48大小
#判断样本为正样本、负样本、部分样本哪一类
iou=NMS.iou(crop_box,np.array(boxes))[0]#计算IOU值
if iou >0.65: #正样本
#存储图片
positive_anno_file.write(
"positive/{0}.jpg{1}{2}{3}{4}{5}{6}{7}{8}{9}{10}{11}{12}{13}{14}{15}\n".format(
positive_count,1,offset_x1,offset_y1,offset_x2, offset_y2, offset_px1, offset_py1, offset_px2, offset_py2, offset_px3,
offset_py3, offset_px4, offset_py4, offset_px5, offset_py5
)
)
positive_anno_file.flush()
#存储标签
face_resize.save(os.path.join(positive_image_dir,"{0}.jpg".format(positive_count)))
positive_count+=1
elif iou >0.4: #部分样本
# 存储图片
part_anno_file.write(
"part/{0}.jpg {1} {2} {3} {4} {5} {6} {7} {8} {9} {10} {11} {12} {13} {14} {15}\n".format(
part_count, 2, offset_x1, offset_y1, offset_x2,
offset_y2, offset_px1, offset_py1, offset_px2, offset_py2, offset_px3,
offset_py3, offset_px4, offset_py4, offset_px5, offset_py5)
)
part_anno_file.flush()
# 存储标签
face_resize.save(os.path.join(part_image_dir,"{0}.jpg".format(part_count)))
part_count+=1
elif iou<0.3:#负样本(负样本很少,或者没有)
# 存储图片
negative_anno_file.write(
"negative/{0}.jpg {1} 0 0 0 0 0 0 0 0 0 0 0 0 0 0\n".format(negative_count, 0)
)
negative_anno_file.flush()
# 存储标签
face_resize.save(os.path.join(negative_image_dir,"{0}.jpg".format(negative_count)))
negative_count+=1
#单独生成负样本(会扣到一部分人脸,)
_boxes=np.array(boxes)
for i in range(5):
side_len=np.random.randint(face_size,min(img_w,img_h)/2)#最小值为:face_size,最大值为:图片最短边的一半
x_=np.random.randint(0,img_w-side_len)#
y_=np.random.randint(0,img_h,side_len)
crop_box=np.array([x_,y_,x_+side_len,y_+side_len])
if np.max(NMS.iou(crop_box,_boxes))<0.3:#值不标准
face_crop=img.crop(crop_box)
face_resize=face_crop.resize((face_size,face_size),Image.ANTIALIAS)
negative_anno_file.write("negative/{0}.jpg {1} 0 0 0 0 0 0 0 0 0 0 0 0 0 0\n".format(negative_count,0))
negative_anno_file.flush()
face_resize.save(os.path.join(negative_image_dir, "{0}.jpg".format(negative_count)))
negative_count += 1
except Exception as e:
traceback.print_exc()
finally:
positive_anno_file.close()
negative_anno_file.close()
part_anno_file.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
2.网络结构
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets,transforms
class PNet(nn.Module):
def __init__(self):
super(PNet,self).__init__()
self.pre_layer=nn.Sequential(
nn.Conv2d(3,10,kernel_size=3,stride=1),#conv1
nn.PReLU(),#PReLU1
nn.MaxPool2d(kernel_size=3,stride=2),#pool1
nn.Conv2d(10,16,kernel_size=3,stride=1),#conv2
nn.PReLU(),#PReLU2
nn.Conv2d(16,32,kernel_size=3,stride=1),#conv3
nn.PReLU()#PReLU3
)
self.conv4_1=nn.Conv2d(32,1,kernel_size=1,stride=1)#一个置信度
self.conv4_2=nn.Conv2d(32,4,kernel_size=1,stride=1)#四个偏移量
def forward(self,x):
x=self.pre_layer(x)
cond=F.sigmoid(self.conv4_1(x))#激活置信度
offset=self.conv4_2(x)#不激活偏移量
return cond,offset
class RNet(nn.Module):
def init(self):
super(RNet,self).init()
self.pre_layer=nn.Sequential(
nn.Conv2d(3,28,kernel_size=3,stride=1),#conv1
nn.PReLU(),#prelu1
nn.MaxPool2d(kernel_size=3,stride=2),#pool1
nn.Conv2d(28,48,kernel_size=3,stride=1),#conv2
nn.PReLU(),#prelu2
nn.MaxPool2d(kernel_size=3,stride=2),#pool2
nn.Conv2d(48,64,kernel_size=2,stride=1),#conv3
nn.PReLU()#prelu3
)
self.conv4=nn.Linear(6422,128)# conv4
self.prelu=nn.PReLU()# prelu4
“”“直接在全线性的基础上做置信度和偏移量。如果要使用全卷积做,又需要将线性转回卷积,操作麻烦”""
# detection
self.conv5_1=nn.Linear(128,1)#一个置信度
# bounding box regression
self.conv5_2=nn.Linear(128,4)#四个偏移量
def forward(self,x):
x=self.pre_layer(x)
x=x.view(x.size(0),-1)#变形
x=self.conv4(x)
x=self.prelu4(x)
# detection
label=F.sigmoid(self.conv5_1(x))
# bounding box regression
offset=self.conv5_2(x)
return label,offset
class ONet(nn.Module):
def init(self):
super(ONet,self).init()
self.pre_layer=nn.Sequential(
nn.Conv2d(3,32,kernel_size=3,stride=1),#conv1
nn.PReLU(),#prelu1
nn.MaxPool2d(kernel_size=3,stride=2),#Pool1
nn.Conv2d(32,64,kernel_size=3,stride=1),#conv2
nn.PReLU(),#prelu2
nn.MaxPool2d(kernel_size=3,stride=2),#Pool2
nn.Conv2d(64,64,kernel_size=3,stride=1),#conv3
nn.PReLU(),#prelu3
nn.MaxPool2d(kernel_size=2,stride=2),#Pool3
nn.Conv2d(64,128,kernel_size=2,stride=1),#conv4
nn.PReLU()#prelu4
)
self.conv5=nn.Linear(128*2*2,256)# conv5
self.prelu5=nn.PReLU()# prelu5
# detection
self.conv6_1=nn.Linear(256,1)
# bounding box regression
self.conv6_2=nn.Linear(256,4)
def forward(self,x):
x=self.pre_layer(x)
x=x.view(x.size(0),-1)
x=self.conv5(x)
x=self.prelu5(x)
# detection
label=F.sigmoid(self.conv6_1(x))
# bounding box regression
offset=self.conv6_2(x)
return label,offset
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
3.数据集
-
继承Dataset;
-
重写三个方法:把数据集加到list;将标签中的正样本、负样本和部分样本分别读出来加载到list中;重写len方法。
-
getitm:
- 从数据集中拿到图片、置信度、偏移量。将图片当成x,置信度和偏移量当成y。(数据集样本数据[P,C,X1,Y1,X2,T2])。
- 取出数据,拿到图片路径,取出图片。
- 取出置信度,并转成Tensor。
- 偏移量同上。
- 将图片归一化。
- 并返回图片、置信度、偏移量。
-
图片换轴
NHWC–>NChw
-
代码
from torch.utils.data import Dataset
import os
import numpy as np
import torch
from PIL import Image
class FaceDataset(Dataset):
def __init__(self, path):
self.path = path
self.dataset = []
self.dataset.extend(open(os.path.join(path, "positive.txt")).readlines())
self.dataset.extend(open(os.path.join(path, "negative.txt")).readlines())
self.dataset.extend(open(os.path.join(path, "part.txt")).readlines())
def __getitem__(self, index):
strs = self.dataset[index].strip().split(" ")
img_path = os.path.join(self.path, strs[0])
cond = torch.Tensor([int(strs[1])])
offset = torch.Tensor([float(strs[2]), float(strs[3]), float(strs[4]), float(strs[5])])
img_data = torch.Tensor(np.array(Image.open(img_path)) / 255. - 0.5)
# print(img_data.shape)
#
# a = img_data.permute(2,0,1)
# print(a.shape)
return img_data, cond, offset
def __len__(self):
return len(self.dataset)
if name == ‘main’:
dataset = FaceDataset(r"D:\celeba4\12")
print(dataset[0])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
4.训练网络
-
三个网络同时训练:
-
输出结果一样;
-
训练过程一样;(加载数据,得到结果)
-
数据集不一样、网络不一样、结果一样(置信度和偏移量的损失);
-
写一个模块(训练器)同时训练三个网络。主要传入两个参数(训练的数据集、网络)、保存最终结果(网络要保存的参数)。
-
训练器详细分析:
- 传入网络、保存路径、数据集、GPU
- 初始化上述四个参数
- 置信度损失用交叉熵函数激活。
- 偏移量损失用均方差损失函数激活。
- 用Adam()优化器优化传进来的参数。
- 如果,以前有保存的模型,继续训练。
- 加载数据。
- 读取图片、置信度、偏移量。
- 先,拿图。将图片传入网络,返回置信度和偏移量。置信度做形状变换(原因1:P网络输出结果形状:NCHW(N111),R和O网络输出形状:NV(N1)。需要将输出形状变统一结构。变为NV(N1)结构,而不变为NCHW(N111)结构,是因为标签结构为NV。原因2:当P网络输入较大图片时,得到结果为N1AA,要变为NV结构:NxAxA,1结构。如N122–>Nx4,1)。
- 偏移量做变形。
- 计算置信度损失:排除部分样本标签。从标签中取出置信度小于2的置信度掩码,利用掩码取出置信度为0和1的标签数据;从网络输出置信度结果中取出小于2的置信度结果(因为网络中传入图片中包含所有置信度种类包含的置信度对应的图片。)。利用标签置信度和网络输出结果置信度做损失计算。
- 计算偏移量损失:排除负样本标签。从标签中取出置信度大于0的置信度掩码,利用掩码取出置信度为1和2的标签数据;从网络输出置信度结果中取出大于0的置信度结果(因为网络中传入图片中包含所有置信度种类包含的置信度对应的图片。)。利用标签偏移量和网络输出结果偏移量做损失计算。
- 计算置信度和偏移量损失和。
- 反向传播。
- 优化损失。
-
完成。
(1)保存和加载网络的两种方法
- 方法一:网络参数
0.4版本以后,新版本中增加对模型参数的形状要求。保存参数时,要指定形状。
保存:
torch.save(model.state_dict(), PATH)
- 1
在保存模型进行推理时,只需要保存训练过的模型的学习参数即可。一个常见的PyTorch约定是使用.pt或.pth文件扩展名保存模型。
加载:
model = TheModelClass(*args, **kwargs)
model.load_state_dict(torch.load(PATH))
model.eval()
- 1
- 2
- 3
注意:
a.必须调用model.eval(),以便在运行推断之前将dropout和batch规范化层设置为评估模式。如果不这样做,将会产生不一致的推断结果。
b. load_state_dict()函数接受一个dictionary对象,而不是保存对象的路径。这意味着您必须在将保存的state_dict传至load_state_dict()函数之前反序列化它。
- 方法二:网络模型(推荐使用)
保存:
torch.save(model, PATH)
- 1
加载:
# Model class must be defined somewhere
model = torch.load(PATH)
model.eval()
- 1
- 2
- 3
(2)接着训练
- 使用网络参数
if os.path.exists(self.save_path):
net.load_state_dict(torch.load(self.save_path))
- 1
- 2
- 使用网络模型
if os.path.exists(self.save_path):
torch.load(self.save_path)
- 1
- 2
(3)输出结果形状变换
-
置信度形状变换:
-
P网络最后一层因为卷积层输出置信度结果形式为:NCHW,实质为:N111。
注释:N:批次;第一个1:置信度为1(通道为1。因为网络最后设计为1x1x32大小变为1x1x1。);第二个1:图片H(网络输入图片大小12x12,输出大小为1x1);第三个1:图片W(网络输入图片大小12x12,输出大小为1x1)。
-
R网络最后一层因为线性层输出置信度结果形式为:NV,实质为:N1
-
O网络最后一层因为线性层输出置信度结果形式为:NV,实质为:N1
-
置信度标签本身是1个数字,当输入批次图片时,标签形状变为:NV
主要是将P网络的NCHW结构变换为N1结构。当P网络输入图像较大,输出结果大小为2x2,即N122。此时,需要变换为Nx4 1 结构。如下图,为传入一张图片,得到2x2大小特征图,形状为:1x1x2x2,将其变换成NV结构:4x1,即[1 1 1 1]。程序将大特征图单独处理。当输入图片大小为12x12,输出置信度为[[1]];当图片大小大于12x12时,输出置信度为[[1],[2],[3],…],程序依次判断置信度即可。
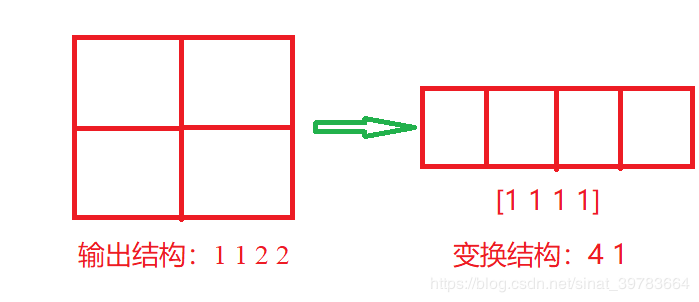
output_category =_output_category.view(-1,1)
- 1
- 偏移量形状变换:
同上。
output_offset = _output_offset.view(-1, 4)
- 1
- 10个关键点形状变换
同上。
output_landmark = _output_landmark.view(-1, 10)
- 1
(4)计算分类的损失
- 从标签中取出正负样本
即,排除部分样本。如下图为文本数据,在其中取出正样本和负样本。取出置信度为0和1的样本数据,排除置信度为2的样本数据。

- 练习方法一:
import numpy as np
a= np.array([8,2,7,5,1,4])
print(a<5)#小于5的布尔值
print(a[a<[5]])#小于5的数值
- 1
- 2
- 3
- 4
- 5
打印结果:
[False True False False True True]
[2 1 4]
- 1
- 2
- 练习方法二:
import numpy as np
a= np.array([8,2,7,5,1,4])
print(np.where(a<5))#小于5的索引值
print(a[np.where(a<5)])#小于5的数值
- 1
- 2
- 3
- 4
- 5
打印结果:
(array([1, 4, 5], dtype=int64),)
[2 1 4]
- 1
- 2
- 练习方法三:
import torch
a=torch.Tensor([1,2,3,4,5])
print(a<4)#输出布尔值。pytorch中用1和0表示True和False。
print(torch.lt(a,4))#lt:小于;gt:大于;eq:等于;le:小于等于;ge:大于等于.
#以下两个方法等价
print(a[a<4])
print(torch.masked_select(a,a<4))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
打印结果:
tensor([ 1, 1, 1, 0, 0])
tensor([ 1, 1, 1, 0, 0])
tensor([1., 2., 3.])
tensor([1., 2., 3.])
- 1
- 2
- 3
- 4
代码:(采用练习方法三)
category_mask=torch.lt(category_,2)#排除部分样本。拿出置信度小于2的掩码
category=torch.masked_select(category_,category_mask)#根据掩码从标签中取出置信度为0和1的数据
- 1
- 2
- 从网络结果中取出正负样本
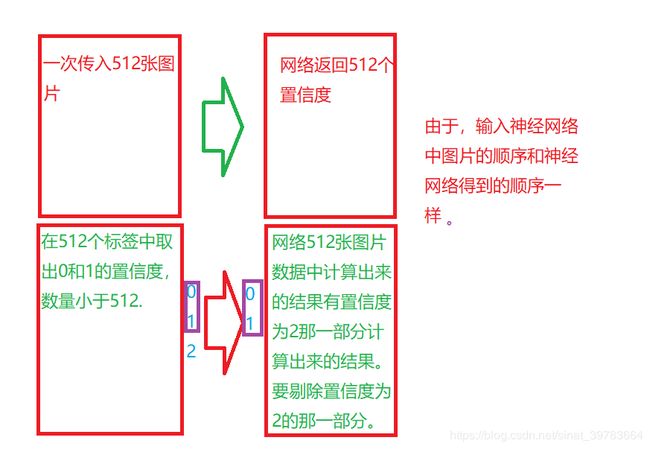
output_category=torch.masked_select(output_category,category_mask)#据掩码从网络结果中取出置信度为0和1的数据。
- 1
- 最终代码
category_mask=torch.lt(category_,2)#排除部分样本。拿出置信度小于2的掩码
category=torch.masked_select(category_,category_mask)#根据掩码从标签中取出置信度为0和1的数据
output_category=torch.masked_select(output_category,category_mask)#据掩码从结果中取出置信度为0和1的数据。
cls_loss=self.cls_loss_fn(output_category,category)
- 1
- 2
- 3
- 4
(5)计算偏移量的损失
- 练习_取出二维数组偏移量
import torch
import numpy as np
a=torch.Tensor([[1,2],[3,4],[5,6],[7,8],[9,10]])
b=torch.Tensor([1,2,3,4,5])
#一维取二维
print(a[b>3])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
打印结果:
tensor([[ 7., 8.],
[ 9., 10.]])
- 1
- 2
- 最终代码
offset_mask=torch.gt(category_,0)#负样本不参与运算
offset=offset_[offset_mask]
output_offset=_output_offset[offset_mask]
offset_loss =self.offset_loss_fn(output_offset,offset)
- 1
- 2
- 3
- 4
(6)打印损失
numpy不支持CUDA,GPU没办法直接转为numpy。要将CUDA转为cpu,并转为.data(loss是value),再转为numpy。
print(" loss:", loss.cpu().data.numpy(), " cls_loss:", cls_loss.cpu().data.numpy(), " offset_loss",offset_loss.cpu().data.numpy())
- 1
(7)保存模型
torch.save(self.net.state_dict(), self.save_path)
print("save success")#每保存一次,显示保存成功
- 1
- 2
(8)训练网络代码
import os
from torch.utils.data import DataLoader
import torch
from torch import nn
import torch.optim as optim
from MTCNN.simpling import FaceDataset
class Trainer:
def init(self,net,save_path,dataset_path,isCuda=True):
self.net=net
self.save_path=save_path
self.dataset_path=dataset_path
self.isCuda=isCuda
if self.isCuda:
self.net.cuda()
self.cls_loss_fn=nn.BCELoss()#the Binary Cross Entropy。置信度损失
self.offset_loss_fn=nn.MSELoss()#均方差损失。
self.optimizer=optim.Adam(self.net.parameters())#优化器
#当有网路模型时加载。作用:接着训练。
if os.path.exists(self.save_path):
net.load_state_dict(torch.load(self.save_path))
def train(self):
faceDataset=FaceDataset(self.dataset_path)
dataloader=DataLoader(faceDataset,bath_size=512,shuffle=True,num_workers=4)#数据读到内存
while True:
for i,(img_data_,category_,offset_) in enumerate(dataloader):#图片、置信度、偏移量
if self.isCuda:
img_data_=img_data_.cuda()
category_=category_.cuda()
offset_=offset_.cuda()
_output_category, _output_offset =self.net(img_data_)#输入图片,返回置信度和偏移量
output_category =_output_category.view(-1,1)#置信度形状变换。P网络输出形状:nchw。R网络和O网路输出形状:nv
# output_offset = _output_offset.view(-1, 4)#偏移量形状变换
# output_landmark = _output_landmark.view(-1, 10)#是个关键点形状变换。(暂不考虑)
# 计算分类的损失
category_mask=torch.lt(category_,2)#排除部分样本。拿出置信度小于2的掩码
category=torch.masked_select(category_,category_mask)#根据掩码从标签中取出置信度为0和1的数据
output_category=torch.masked_select(output_category,category_mask)#据掩码从结果中取出置信度为0和1的数据。
cls_loss=self.cls_loss_fn(output_category,category)
#计算bound的损失
offset_mask=torch.gt(category_,0)#负样本不参与运算
offset=offset_[offset_mask]
output_offset=_output_offset[offset_mask]
offset_loss =self.offset_loss_fn(output_offset,offset)
loss=cls_loss+offset_loss
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
print(" loss:", loss.cpu().data.numpy(), " cls_loss:", cls_loss.cpu().data.numpy(), " offset_loss",
offset_loss.cpu().data.numpy())
torch.save(self.net.state_dict(), self.save_path)
print("save success")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
(9)注意事项
-
结果达到自己要求时,训练结束,可直接关闭,因为有保存参数。
-
1050或者1060训练48-72小时,效果非常完美。
-
训练超过72个小时会出现过拟合,学习过度,把一些不是人脸的东西当做人脸。
-
网络讲到0.2时下降非常慢,切勿关闭。
-
P网络下降到0.02左右即可。
-
数据集中很多照 照片有手,网络会将收认为人脸。
5.同时分开训练网路
- P网络
import nets
import train
if name == ‘main’:
net = nets.PNet()
trainer = train.Trainer(net, './param/pnet.pt', r"C:\celeba4\12")#调入网络、填写保存参数位置、传入数据集
trainer.train()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- R网络
import nets
import train
if name == ‘main’:
net = nets.RNet()
trainer = train.Trainer(net, './param/rnet.pt', r"C:\celeba4\24")
trainer.train()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- O网络
import nets import train if __name__ == '__main__': net = nets.ONet()trainer = train.Trainer(net, './param/onet.pt', r"C:\celeba4\48") trainer.train()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
6.网络的使用
- 实例化三个网络;
- 读入三个网络权重;
- 归一化(归一化参数使用训练时的数据);
- 将传入的图片转为Terson;
- 使用:
- P网络:P网络输出一堆框框。输入一张图片,获取图片的宽和高,获取最小边长,做图片金字塔使用;将原图变为Tensor并放到CUDA中,升高维度(传进去1张图片,而训练时使用一批图片),将图片传入P网络,得到置信度(NCHW)和偏移量(NCHW),取置信度(_cls [0] [0])大于0.6的值,取偏移量(_offes[0])。根据索引、偏移量,置信度、缩放比例反算:特征图反算原图左上角和后下角点坐标;原图和偏移量反算实际框。将这些结果保存。注意形状和IOU形状相同。进行MNS计算。
- R网络:传入P网络得到的置信度满足要求的框框在原图上的区域图片。P网络输出的结果有长方形、正方形,变为24x24的正方形(将框变成正方形:长方形变成正方形,拿到正方形的坐标点然后抠图)。将图片缩放变形,输入,结果进行组装。注:拿R网络满足置信度的结果取P网络的结果(P网络的实际框)。
- O网络:同R网络。
- 测试。
(1)初始化
- 导入三个网络权重
def __init__(self, pnet_param="./param/pnet.pt", rnet_param="./param/rnet.pt", onet_param="./param/onet.pt",
isCuda=True):#读入三个网络权重
- 1
- 2
- 实例化三个网络
#实例化三个网络
self.pnet = nets.PNet()
self.rnet = nets.RNet()
self.onet = nets.ONet()
- 1
- 2
- 3
- 4
- 是否使用CUDA
self.isCuda = isCuda
if self.isCuda:
self.pnet.cuda()
self.rnet.cuda()
self.onet.cuda()
- 1
- 2
- 3
- 4
- 5
- 将参数加载到网络
self.pnet.load_state_dict(torch.load(pnet_param))
self.rnet.load_state_dict(torch.load(rnet_param))
self.onet.load_state_dict(torch.load(onet_param))
- 1
- 2
- 3
-
batch normalization
归一化在训练和使用是有差别的。训练的时候使用一批图片,使用的时候是一张图片。均值和方差不一样。在使用网络时,不用使用时的图片数据的batch normalization,使用训练网路时的batch normalization。
如下为使用训练网络时候的batch normalization的代码。(本例不使用batch normalization。可自行加载batch normalization)
self.pnet.eval()
self.rnet.eval()
self.onet.eval()
- 1
- 2
- 3
-
图片转Tensor
ToTensor():
Converts a PIL Image or numpy.ndarray (H x W x C) in the range[0, 255] to a torch.FloatTensor of shape (C x H x W) in the range [0.0, 1.0]if the PIL Image belongs to one of the modes (L, LA, P, I, F, RGB, YCbCr, RGBA, CMYK, 1)or if the numpy.ndarray has dtype = np.uint8
self.__image_transform = transforms.Compose([
transforms.ToTensor()
])
- 1
- 2
- 3
- 最终代码
def __init__(self, pnet_param="./param/pnet.pt", rnet_param="./param/rnet.pt", onet_param="./param/onet.pt", isCuda=True):#读入三个网络权重self.isCuda = isCuda #实例化三个网络 self.pnet = nets.PNet() self.rnet = nets.RNet() self.onet = nets.ONet() if self.isCuda: self.pnet.cuda() self.rnet.cuda() self.onet.cuda() #将参数加载到网络 self.pnet.load_state_dict(torch.load(pnet_param)) self.rnet.load_state_dict(torch.load(rnet_param)) self.onet.load_state_dict(torch.load(onet_param)) # self.pnet.eval() self.rnet.eval() self.onet.eval() self.__image_transform = transforms.Compose([ transforms.ToTensor() ])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
(2)P网络
-
分析
-
传入一张图片,得到一堆框框(boxes = []:接收),格式为:[x1,y1,x2,y2,c],格式同IOU格式。
-
传入一张图片,并宽和高,得到图片最小边长,用于控制制作金字塔。(最小边长缩到12)
-
将原图转为Tensor,放进CUDA,并升高纬度。因为传入一张图片没有批次,要升高一个维度,保证维度相同,维度变为:1CHW。
-
升高位图的图片数据传入P网络,得到置信度和偏移量。此时,置信度和偏移量格式为:NCHW。
-
取置信度。取N和C。格式如:1x1x2x2
_cls[0][0].cpu().data# _cls[0][0]:取N和C- 1

- 取偏移量。取N。格式如:1x4x2x2
_offest[0].cpu().data#_offest[0]:取
- 1
- 保留置信度大于0.6的值,接着取出置信度大于0.6的索引。(置信度大于0.6结果为人脸。这里给的置信度较低,得到的结果较差。缘由是:宁误选,不放过。)
idxs = torch.nonzero(torch.gt(cls, 0.6))
- 1
- 特征图的反向运算
在原图上找到这些保留的结果区域。需要知道:索引(两个值)、偏移量、置信度、缩放比例。
for idx in idxs:
boxes.append(self.__box(idx, offest, cls[idx[0], idx[1]], scale))#cls[idx[0], idx[1]]:置信度
- 1
- 2
反向计算原图左上角和右下角点坐标:
原图中左上角点:(索引*步长)/缩放比例
原图中右下角点:(索引*步长+卷积核大小 )/缩放比例
_x1 = (start_index[1] * stride) / scale
_y1 = (start_index[0] * stride) / scale
_x2 = (start_index[1] * stride + side_len) / scale
_y2 = (start_index[0] * stride + side_len) / scale
- 1
- 2
- 3
- 4
根据偏移量计算框的坐标点:
偏移量公式:(内部x-外部x)/外部边框
x1 = _x1 + ow * _offset[0]
y1 = _y1 + oh * _offset[1]
x2 = _x2 + ow * _offset[2]
y2 = _y2 + oh * _offset[3]
- 1
- 2
- 3
- 4
总代码:
def __box(self, start_index, offset, cls, scale, stride=2, side_len=12):#索引、偏移量、置信度、缩放比例、步长(固定值)、卷积核(12)。#原图左上角和右下角点 _x1 = (start_index[1] * stride) / scale _y1 = (start_index[0] * stride) / scale _x2 = (start_index[1] * stride + side_len) / scale _y2 = (start_index[0] * stride + side_len) / scale ow = _x2 - _x1 oh = _y2 - _y1 _offset = offset[:, start_index[0], start_index[1]] x1 = _x1 + ow * _offset[0] y1 = _y1 + oh * _offset[1] x2 = _x2 + ow * _offset[2] y2 = _y2 + oh * _offset[3] return [x1, y1, x2, y2, cls]#P网络最终结果。形状同IOU形状。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 网络调优
置信度小,阈值大,造成的问题:P网络保留下来的框较多,意味着传入R网络的图片大,计算量大,网络慢。
- P网络置信度
idxs = torch.nonzero(torch.gt(cls, 0.6))
- 1
- P网络阈值
return utils.nms(np.array(boxes), 0.5)
- 1
- 最终代码
def __pnet_detect(self, image):#传入图片boxes = []#接收结果(一堆框框) img = image#图片 w, h = img.size#获取图片宽和高 min_side_len = min(w, h)#获取最小边长制作金字塔 scale = 1#缩放比例为1 while min_side_len > 12: img_data = self.__image_transform(img)# if self.isCuda: img_data = img_data.cuda() img_data.unsqueeze_(0) _cls, _offest = self.pnet(img_data) cls, offest = _cls[0][0].cpu().data, _offest[0].cpu().data idxs = torch.nonzero(torch.gt(cls, 0.6)) for idx in idxs: boxes.append(self.__box(idx, offest, cls[idx[0], idx[1]], scale)) scale *= 0.7 _w = int(w * scale) _h = int(h * scale) img = img.resize((_w, _h)) min_side_len = min(_w, _h) return utils.nms(np.array(boxes), 0.5) # 将回归量还原到原图上去 def __box(self, start_index, offset, cls, scale, stride=2, side_len=12): _x1 = (start_index[1] * stride) / scale _y1 = (start_index[0] * stride) / scale _x2 = (start_index