ELK企业内部日志分析系统(elasticsearch/logstash/beats/kibana)centos7详解
一、软件介绍
1.Easticsearch搜索引擎:是一个基于Lucene的搜索引擎,提供索引,搜索功能。他提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
2.Logstash接收,处理,转发日志工具:
logstash是一个开源的服务器端数据处理流水线,它可以同时从多个数据源获取数据,并将其转化为最喜欢的“存储”(ours is elasticsearch,naturally.)主要是用来日志的搜集、分析、过滤日志的工具。用于管理日志和事件的工具,你可以用它去收集日志、转换日志、解析日志并将他们作为数据提供给其它模块调用,例如搜索、存储等。
3.Beats采集日志信息:GO语言开发,所以高效、很快:
filebeat:
隶属于Beats,轻量级数据收集引擎。基于原先 Logstash-fowarder 的源码改造出来。换句话说:Filebeat就是新版的 Logstash-fowarder,也会是 ELK Stack 在 Agent 的第一选择,目前Beats包含四种工具:
-
Packetbeat(搜集网络流量数据)
-
Metricbeat(搜集系统、进程和文件通过从操作系统和服务收集指标,帮助您监控服务器及其托管的服务。)
-
Filebeat(搜集文件数据)
-
Winlogbeat(搜集 Windows 事件日志数据)
4.Kibana:独立美观的图形数据展示界面: Kibana 是一个优秀的前端日志展示框架,它可以非常详细的将日志转化为各种图表,为用户提供强大的数据可视化支持,它能够搜索、展示存储在 Elasticsearch 中索引数据。使用它可以很方便的用图表、表格、地图展示和分析数据。让你可视化你的Elasticsearch数据并导航Elastic Stack,所以你可以做任何事情,从凌晨2:00分析为什么你得到分页,了解雨水可能对你的季度数字造成的影响。
二、实验环境
1.实验拓扑

2.实验准备
a.环境准备:
- els——192.168.11.132——elasticsearch(搜索引擎)
- logstash——192.168.11.139——logstash(日志处理) redis(缓冲队列)
- filebeat——192.168.11.140——filebeat(日志收集)httpd/mysql(生成日志)
- kibana——192.168.11.141——kibana(展示界面)
b.修改主机名
hostnamectl set-hostname els.along.com
hostnamectl set-hostname logstash.along.com
hostnamectl set-hostname filebeat.along.com
hostnamectl set-hostname kibana.along.com
注:分别在四台主机上操作,然后重启主机生效
c.修改hosts
vim /etc/hosts
192.168.11.132 els.along.com
192.168.11.139 logstash.along.com
192.168.11.140 filebeat.along.om
192.168.11.141 kibana.along.com
测试:互ping
[root@els ~]# ping logstash.along.com
[root@els ~]# ping filebeat.along.com
[root@els ~]# ping kibana.along.com
e.关闭防火墙、selinux
systemctl stop firewalld.service
systemctl status firewalld.service
setenforce 0
getenforce
f.同步时间
yum -y install chrony
vim /etc/chrony.conf

systemctl restart chronyd.service
chronyc sources -v
三、搭建elasticsearch和head插件
1.安装java环境
yum -y install java-1.8.0-openjdk-devel
2.安装下好的els(https://www.elastic.co)
yum -y install elasticsearch-5.5.1.rpm
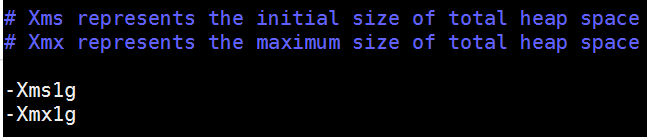
3.修改jvm的配置
vim /etc/elasticsearch/jvm.options
4.配置els
vim /etc/elasticsearch//elasticsearch.yml
cluster.name: alongels #集群名字
node.name: els #节点名
path.data: /els/data #索引路径
path.logs: /els/logs #日志存储路径
network.host: 192.168.11.132 #对外通信的地址,依次修改为自己机器对外的IP
#http.port: 9200 #默认端口
5.创建所需的路径,并修改权限
mkdir -pv /els/{data,logs}
chown -R elasticsearch.elasticsearch /els/*
6.重启服务
systemctl start elasticsearch.service
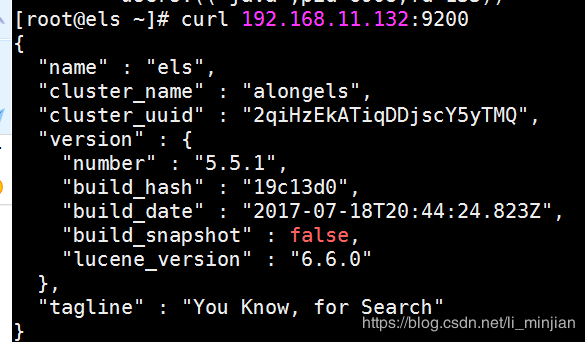
7.测试
ss -naput | grep 9200

curl 192.168.11.132:9200
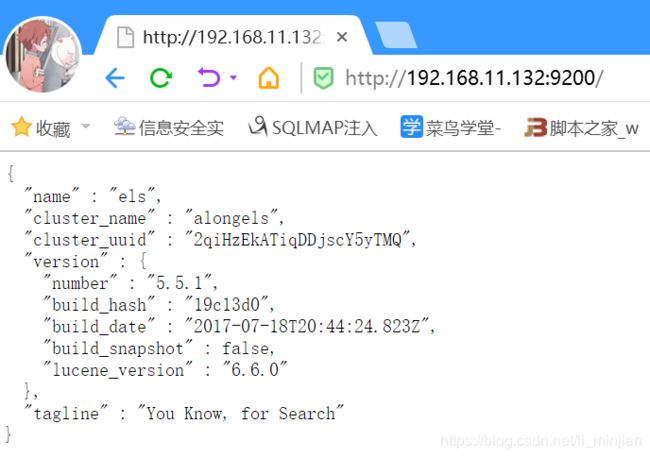
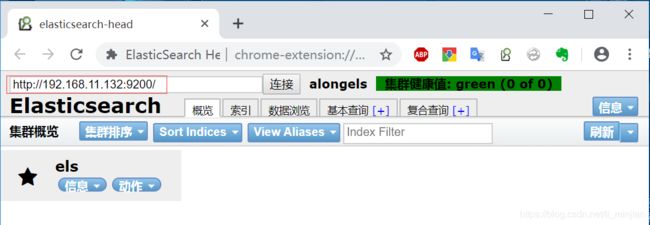
浏览器访问:
8.安装elasticsearch 的head插件
谷歌Elasticsearch head插件实现了此功能,所以直接使用谷歌插件
四、搭建介绍logstash
1.介绍(笔者自己做笔记用,可以直接忽略)
查看官方文档:https://www.elastic.co/cn/products/logstash
① 官方介绍:Logstash is an open source data collection engine with real-time pipelining capabilities。简单来说logstash就是一根具备实时数据传输能力的管道,负责将数据信息从管道的输入端传输到管道的输出端;与此同时这根管道还可以让你根据自己的需求在中间加上滤网,Logstash提供里很多功能强大的滤网以满足你的各种应用场景。
② Logstash的事件(logstash将数据流中等每一条数据称之为一个event)处理流水线有三个主要角色完成:inputs –> filters –> outputs:
logstash整个工作流分为三个阶段:输入、过滤、输出。每个阶段都有强大的插件提供支持:
Input 必须,负责产生事件(Inputs generate events),常用的插件有
- file 从文件系统收集数据
- syslog 从syslog日志收集数据
- redis 从redis收集日志
- beats 从beats family收集日志(如:Filebeats)
Filter常用的插件有, 可选,负责数据处理与转换(filters modify them)
- grok grok是logstash中最常用的日志解释和结构化插件
- mutate 支持事件的变换,例如重命名、移除、替换、修改等
- drop 完全丢弃事件
- clone 克隆事件
- geoip 给ip地址添加地址信息
output 输出,必须,负责数据输出(outputs ship them elsewhere),常用的插件有
- elasticsearch 把数据输出到elasticsearch
- file 把数据输出到普通的文件
- graphite 把数据输出到graphite (logstash 插件)
- statsd 把数据输出到statsd(logstash插件)

2.下载安装
去官网下载对应版本的logstash ,我下载的是5.5.1版本https://www.elastic.co/cn/downloads/logstash
yum -y install logstash-5.5.1.rpm
3.修改环境变量
vim /etc/profile.d/logstash.sh
export ![]()
. /etc/profile.d/logstash.sh
4.logstash演示用法(笔者做笔记,可忽略)
input => 标准输入
filter => 无
output => 标准输出
编辑配置文件,由于input、output还是标准输入输出

出现无法输出的情况可通过以下方法解决
a.示例1:标准输入输出(可忽略)
----编辑配置文件
cd /etc/logstash/conf.d/
vim test.conf

logstash -f ./test.conf -t
有Configuration OK表明测试成功
logstash -f ./test.conf

b.示例2:从文件输入数据,经grok 拆分插件过滤之后输出至标准输出(必做)
input => 文件输入
filter => grok、date 模块
grok:拆分字段
date:修改时间格式
output => 标准输出
----下载http服务
yum -y install httpd
systemctl start httpd
vim /var/www/html/index.html
home page
----生成20个测试页面
for i in {1…20}; do echo "Test Page i " > / v a r / w w w / h t m l / t e s t i" > /var/www/html/test i">/var/www/html/testi.html; done
ls /var/www/html
curl 192.168.11.139
curl 192.168.11.139/test1.html
—循环生成httpd日志
for i in {1…200}; do j= ( ( (( ((i %20+1)); curl http://192.168.11.139:80/test$j.html; done**(重要)**
----vim test2.conf

logstash -f ./test.conf -t
有Configuration OK表明测试成功
logstash -f ./test.conf

c.示例3:filter 的date、mutate 插件(可忽略)
input => 标准输入
filter => date、mutate 模块
mutate:修改字段
output => 标准输出
vim test3.conf

logstash -f ./test.conf -t
有Configuration OK表明测试成功
logstash -f ./test.conf
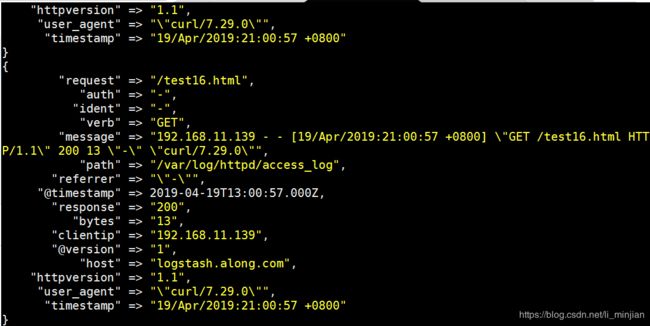
d.示例4:filter 的 geoip 模块(记录世界ip地址)
input => 标准输入
filter => geoip 模块
geoip:利用这个模块解析ip的地址,利于后边kibana 的地理位置展示图
output => 标准输出
----(1)准备ip 数据库
网上下载数据库,因为是记录世界的IP 地址,所以经常有变动,可以写一个计划任务,每隔一周去网上下载一次,解包,链接到maxmind 下:
tar xf GeoLite2-City.tar.gz
mv GeoLite2-City_20190416/ /etc/logstash/
cd /etc/logstash/
mv GeoLite2-City_20190416/ maxmind
----模拟一个公网ip 访问
echo ‘112.168.1.102 - - [08/Feb/2018:15:28:53 +0800] “GET /test6.html HTTP/1.1” 200 12 “-” “curl/7.29.0”’ >> /var/log/httpd/access_log
vim /etc/logstash/conf.d/test4.conf

logstash -f ./test.conf -t
有Configuration OK表明测试成功
logstash -f ./test.conf

e.示例5:output 输出给elasticsearch
input => 来自httpd 的访问日志
filter => geoip 模块
output => 输出给elasticsearch
vim test5.conf

logstash -f test5.conf -t
logstash -f test5.conf
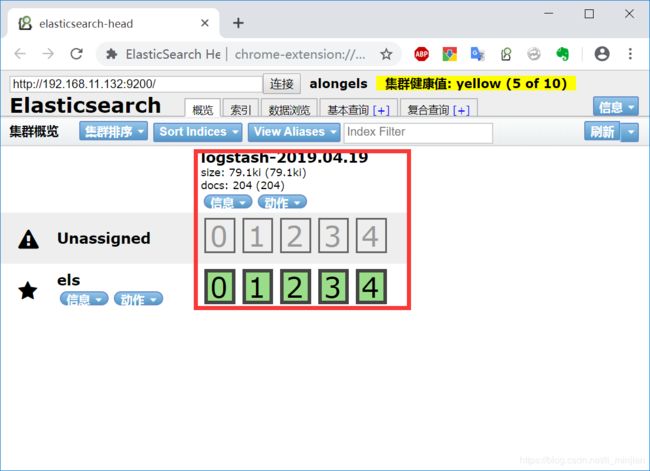
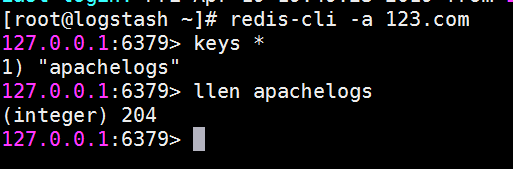
f.示例6:output 输出给redis
input => 来自httpd 的访问日志
filter => geoip 模块
output => 输出给redis
yum -y install redis
vim /etc/redis.conf

systemctl restart redis
vim /etc/logstash/conf.d/test6.conf
测试如图
五、Beats 轻量型数据采集器
1.下载官网:
https://www.elastic.co/cn/products/beats
2.安装
yum -y install filebeat-5.5.1-x86_64.rpm
3.修改配置文件
vim /etc/filebeat/filebeat.yml
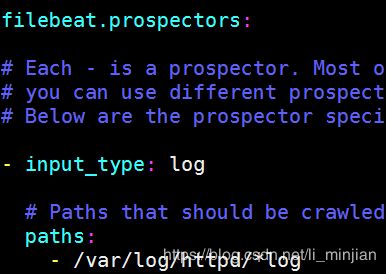
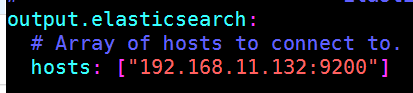
***-----示例1:配置filebeats,目标***elasticsearch
4.安装httpd服务
systemctl start filebeat.service
yum install httpd
systemctl start httpd
vim /var/www/html/index.html
for i in {1…20}; do echo "Test Page i " > / v a r / w w w / h t m l / t e s t {i}" > /var/www/html/test i">/var/www/html/test{i}.html; done
ls /var/www/html/

curl 192.168.11.140
curl 192.168.11.140/test1.html

for i in {1…200}; do j= ( ( (( ((i %20+1)); curl http://192.168.11.140:80/test$j.html; done(生成日志文件)
5.测试
filebeat.sh -e /etc/filebeat/filebeat.yml

----示例1:完整的ELK —> 配置filebeat,目标给logstash
1.配置filebeat
vim /etc/filebeat/filebeat.yml
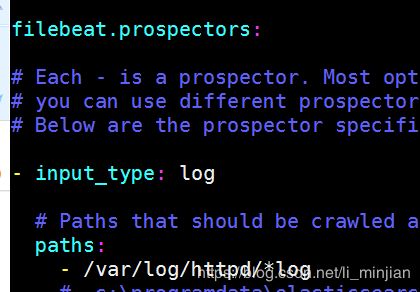
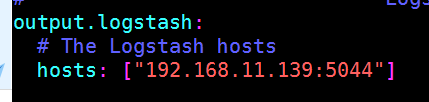
systemctl restart filebeat.service
ss -anput | grep 5044
![]()
2.logstash服务器的配置
input => 来自filebeat
filter => geoip 模块
output => 输出给elasticsearch
vim /etc/logstash/conf.d/apachelogs.conf

logstash -f apachelogs.conf -t
3.filebeat的操作
systemctl restart filebeat.service
for i in {1…200}; do j= ( ( (( ((i %20+1)); curl http://192.168.11.140:80/test$j.html; done(生成日志)
4.测试
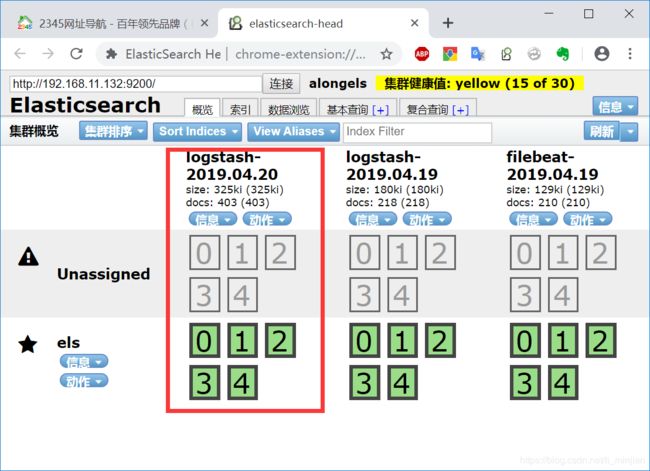
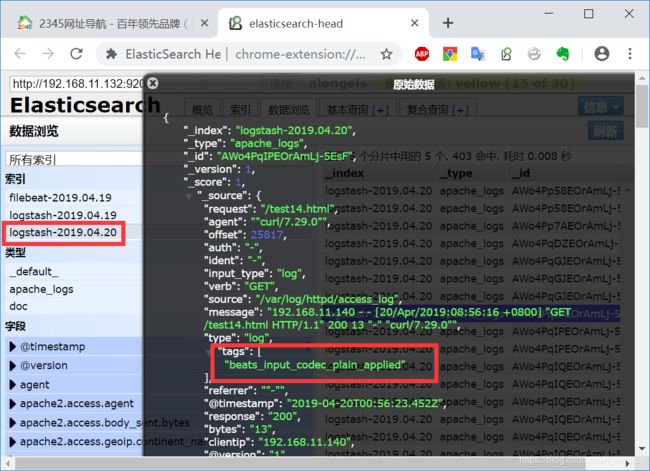
----示例2:完整的els搭建
1.filebeat的操作
vim /etc/filebeat/filebeat.yml
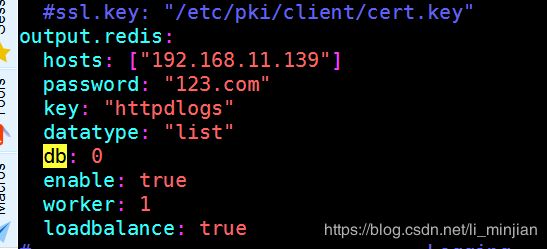
redis-cli -a 123.com

2.logstash的操作
input => 来自redis
filter => geoip 模块
output => 输出给elasticsearch
vim /etc/logstash/conf.d/apachelogs2.conf

logstash -f apachelog.conf -t
3.filebeat的操作
systemctl restart filebeat
filebeat.sh -e /etc/filebeat/filebeat.yml
另开窗口产生日志
for i in {1…200}; do j= ( ( (( ((i %20+1)); curl http://192.168.11.140:80/test$j.html; done
4.测试

六、kibana
1.介绍
kibana 是您走进 Elastic Stack 的窗口,Kibana 让您能够可视化 Elasticsearch 中的数据并操作Elastic Stack,因此您可以在这里解开任何疑问:例如,为何会在凌晨 2:00 被传呼,雨水会对季度数据造成怎样的影响。
① 一张图片胜过千万行日志
Kibana 让您能够自由地选择如何呈现您的数据。或许您一开始并不知道自己想要什么。不过借助Kibana 的交互式可视化,您可以先从一个问题出发,看看能够从中发现些什么。
② 从基础入手
Kibana 核心搭载了一批经典功能:柱状图、线状图、饼图、环形图,等等。它们充分利用了Elasticsearch 的聚合功能。
③ 将地理数据融入任何地图
利用我们的 Elastic Maps Services 来实现地理空间数据的可视化,或者发挥创意,在您自己的地图上实现自定义位置数据的可视化。
④ 时间序列也在菜单之列
您可以利用 Timelion,对您 Elasticsearch 中的数据执行高级时间序列分析。您可以利用功能强大、简单易学的表达式来描述查询、转换和可视化。
⑤ 利用 graph 功能探索关系
凭借搜索引擎的相关性功能,结合 graph 探索,揭示您 Elasticsearch 数据中极其常见的关系。
2.官网下载
https://www.elastic.co/cn/downloads/kibana
3.安装配置
yum -y install kibana-5.5.1-x86_64.rpm
vim /etc/kibana/kibana.yml
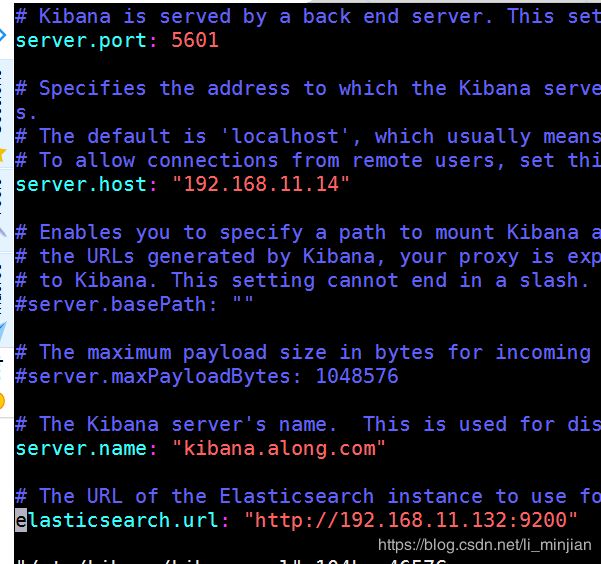
systemctl start kibana
打开网页192.168.11.141:5601

kibana目前不会操作,日后更新。