MQ分发Webmagic爬虫任务项目实现
引言
一个基于垂直爬虫框架 webmagic 的 Java 爬虫实战项目,旨在提供一套完整的数据爬取,持久化存储和搜索分析的实践样例。
项目简介
本项目主要实现对媒体车系车型报价的爬取,解析主要车系车型数据,提醒预警报价数据的邮件和短信的通知,利用Elasticsearch实现数据的分析与搜索,形成数据的可视化分析与报表显示。
项目设计思想
基于爬虫任务统计与可配置开启需求下,针对垂直爬虫框架 webmagic在爬虫任务监控方面个性化定制方面,本项目给出自身的解决方案与思路。
本项目基于RocketMq分发爬虫任务管理系统采用了高性能消息中间件,在爬虫方面启动方面,配合LTS可配置爬虫任务的自定义开启时间,实现爬虫消息任务的分发与消费,利用RocketMq的消费可靠性与由业务逻辑实现的幂等性消费保证,更好异步解耦任务的分发与消费;在数据存储持久化方面,结合主流缓存Redis实现队列进行数据的解析,封装,通过分布式可扩展的实时搜索和分析引擎Elasticsearch实现数据的分析与搜索功能;在爬虫任务监控方面,搭配爬虫框架 webmagic实现爬虫监听器,有效地处理爬虫任务失败的入库统计与重试爬虫;在爬虫预警方面,通过前端页面录入预警条件、通知人、通过方式(支持短信与邮件通知),基于页面的截屏实现爬虫的有效总结。
本项目很好解决困扰爬虫监控与预警方面的一些问题,整合了爬虫的抓取与任务监控,数据有效输出,提供一种爬虫任务处理的具体实现方案。
项目流程

项目主要流程描述:
- 前端页面提供入口配置爬虫任务设置,设置任务的执行时间,执行间隔时间与是否启用,入库任务设置。
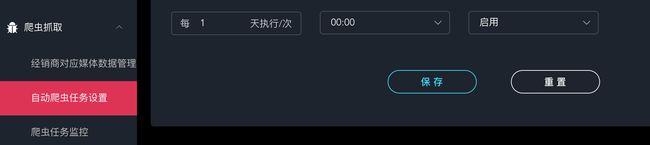
- 后端查询爬虫任务配置,通过LTS api接口生成Cron爬虫任务,更方便地启用任务,省去在LTS后台管理页面手动配置任务的中间操作,一步到位。
- Cron JobRunner通过媒体与车系信息的逻辑处理,拼装爬虫消息体,分发爬虫任务到RocketMq,启动任务信息统计线程。
- 配置MessageListener消息监听器,组装爬虫任务信息进行页面爬虫。
- 爬虫管道数据进行处理,原始数据入队列定时串行消费,推送预警数据RocketMq消息进行报价阈值校验截屏定时邮件或短信通知,推送业务数据入Redis进行定时批量数据添加到Elasticsearch执行报价数据的分析与搜索处理。
项目主要目录结构
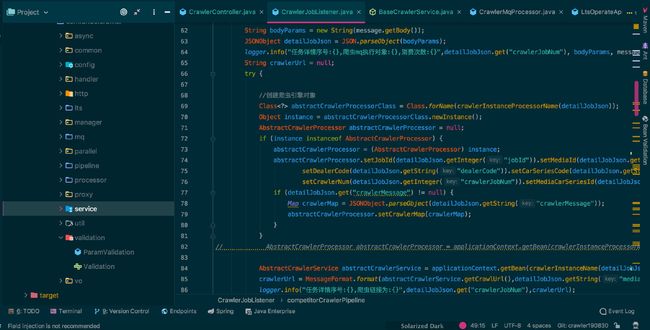
- async、parallel 主要为NamedThreadFactory线程池配置信息,拒绝策略配置和异步任务执行器的实现通用逻辑等
- common、config 爬虫配置通用常量信息,包括爬虫重试次数,爬虫休眠时间,详情任务统计间隔时间等
- handler 推送爬虫子任务处理器,预警通知处理器等
- http 主要为车系,车型,经销商映射信息请求接口等
- lts 主要为爬虫MQCron JobRunner,包括推送mq任务消息JobRunner,批量添加Elasticsearch业务数据JobRunner,原始数据队列入库JobRunner等
- manager 任务入库表的封装CURD处理实现
- mq 主要为mq配置信息,爬虫任务消息监听器,推送预警mq信息处理器等
- pipeline 爬虫管道实现封装逻辑,webmagic#Pipeline接口的实现
- processor 媒体页面解析器,webmagic#PageProcessor接口的实现
- service 媒体爬虫经销商,车系信息封装处理层
- util 工具类
- validation 前端入参校验器等
- vo 主要为项目pojo等
webmagic源码分析
webmagic组件
webmagic的各个功能分别通过组件来实现,很好的实现了各功能之间的解耦,主要包括四大组件:Scheduler、Downloader、Pipeline、PageProcessor,四大组件通过Spider类进行相互协作完成框架功能
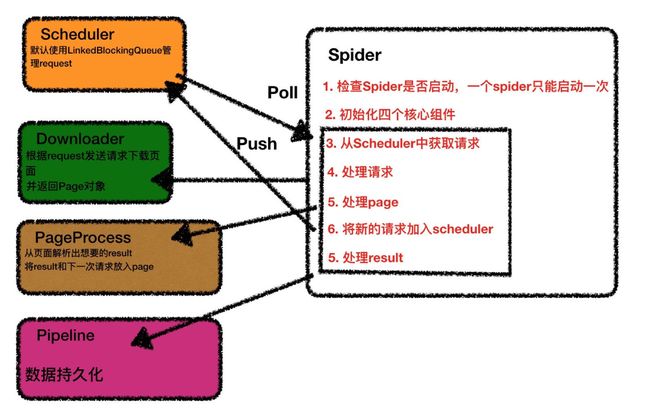
一、Scheduler
抓取url的管理,包含添加待抓取url以及取出需要抓取的url功能,分别通过push方法和poll方法完成两项功能,抓取url进行了抽象,以Request进行表示。
二、PageProcessor
如何对一个页面内容进行处理,是用户主要需要实现的接口,一般用户需要实现对页面内容的抽取以及更多待抓取url的获取
三、Pipeline
对PageProcessor的抽取结果进行持久化处理,比如写入文件、存入数据库、或者简单的打印到控制台
四、Downloader
负责对待抓取的url进行下载,可配置下载线程数
辅助类
一、CountableThreadPool
负责spider的线程管理,实现了一个堵塞线程池,可以实时获取线程池中正在使用的线程以及等待状态的线程数量,线程数的统计以AtomicInteger实现线程安全,内部默认的ExecutorService通过Executors.newFixedThreadPool生成,主要方法execute接受一个Runnable对象作为待执行任务,线程池中无可用线程时会进入阻塞状态
二、Proxy
进行spider的代理管理,抽取为单独的组件可以实现解耦
三、Selector
实现对下载后的页面内容进行选择的功能,主要实现有xpath、css、regex以及jsonPath
四、Request
对抓取url的封装
五、Page
存储抽取的内容以及抓取的url(非线程安全)
六、SpiderListener
页面爬取解析结果监听器
配置类
一、Spider
爬虫的入口,对各个组件进行协调,包含一个Downloader,一个PageProcessor,一个Scheduler以及一个PipeLine列表,抓取任务的执行线程调度以CountableThreadPool完成
二、site
抓取站点的配置,包括域名、ua、默认cookie、默认编码、默认http头等
webmagic源码分析
- 爬虫任务需要PageProcessor页面解析器,爬虫链接url,Pipeline管道参数,可以选择添加爬虫监听器等,同步或者异步启动,建议同步启动,框架对异步启动支持不是很好。
//官方案例
Spider.create(new ZhihuPageProcessor()).
addUrl("http://www.zhihu.com/search?type=question&q=java").
addPipeline(new FilePipeline("D:\\webmagic\\")).
thread(5).
run();
- 项目同步启动方法,先检查爬虫运行状态,接着进行爬虫组件的初始化,设置线程数等,判断爬虫为运行状态,处理爬虫请求
@Override
public void run() {
//检查爬虫运行状态
checkRunningStat();
//初始化容器,包括downloader,pipeline,线程池等
initComponent();
logger.info("Spider {} started!",getUUID());
while (!Thread.currentThread().isInterrupted() && stat.get() == STAT_RUNNING) {
final Request request = scheduler.poll(this);
//待爬虫url为空,线程进入等待状态,通过waitNewUrl实现,阻塞状态通过signalNewUrl方法进行解除
if (request == null) {
if (threadPool.getThreadAlive() == 0 && exitWhenComplete) {
break;
}
// wait until new url added
waitNewUrl();
} else {
//执行爬虫任务
threadPool.execute(new Runnable() {
@Override
public void run() {
try {
//处理爬虫请求
processRequest(request);
//设置爬虫成功状态,可通过SpiderListener监听改状态,实现自身业务逻辑处理
onSuccess(request);
} catch (Exception e) {
//设置爬虫失败状态
onError(request);
logger.error("process request " + request + " error", e);
} finally {
//页面爬取计数
pageCount.incrementAndGet();
signalNewUrl();
}
}
});
}
}
//爬虫完成,设置状态停止
stat.set(STAT_STOPPED);
// release some resources
if (destroyWhenExit) {
close();
}
logger.info("Spider {} closed! {} pages downloaded.", getUUID(), pageCount.get());
}
- 初始化默认容器
protected void initComponent() {
if (downloader == null) {
//默认使用apache HttpClient进行页面的下载功能,实现了代理配置功能
this.downloader = new HttpClientDownloader();
}
if (pipelines.isEmpty()) {
//直接将结果输出到控制台,项目自定义实现
pipelines.add(new ConsolePipeline());
}
//设置线程数
downloader.setThread(threadNum);
if (threadPool == null || threadPool.isShutdown()) {
if (executorService != null && !executorService.isShutdown()) {
//堵塞线程池,可以实时获取线程池中正在使用的线程以及等待状态的线程数量
threadPool = new CountableThreadPool(threadNum, executorService);
} else {
threadPool = new CountableThreadPool(threadNum);
}
}
if (startRequests != null) {
//添加爬虫链接请求
for (Request request : startRequests) {
addRequest(request);
}
startRequests.clear();
}
startTime = new Date();
}
- 处理爬虫处理请求,加载爬虫页面,解析页面,数据管理处理
private void processRequest(Request request) {
//加载爬虫页面
Page page = downloader.download(request, this);
if (page.isDownloadSuccess()){
onDownloadSuccess(request, page);
} else {
onDownloaderFail(request);
}
}
private void onDownloadSuccess(Request request, Page page) {
//注意站点的状态码配置,匹配上了才进行页面的解析,通常页面加载被限状态码不为200,需在加上站点对应的状态码才可以进入页面解析逻辑
if (site.getAcceptStatCode().contains(page.getStatusCode())){
//页面解析,项目自身定义实现
pageProcessor.process(page);
//页面爬虫链接再次加入调度
extractAndAddRequests(page, spawnUrl);
//是否跳过数据管道处理
if (!page.getResultItems().isSkip()) {
//数据管道处理,项目自身定义实现
for (Pipeline pipeline : pipelines) {
pipeline.process(page.getResultItems(), this);
}
}
//打印日志,旧版本没有这块日志,注意版本升级
} else {
logger.info("page status code error, page {} , code: {}", request.getUrl(), page.getStatusCode());
}
//执行站点设置的睡眠时间
sleep(site.getSleepTime());
return;
}
- 页面加载
@Override
public Page download(Request request, Task task) {
//主要逻辑
Page page = Page.fail();
try {
//发起http请求页面
httpResponse = httpClient.execute(requestContext.getHttpUriRequest(), requestContext.getHttpClientContext());
//处理响应结果
page = handleResponse(request, request.getCharset() != null ? request.getCharset() : task.getSite().getCharset(), httpResponse, task);
//添加页面加载成功状态,可以覆盖 Downloader#onSuccess实现页面加载成功失败处理逻辑
onSuccess(request);
logger.info("downloading page success {}", request.getUrl());
return page;
} catch (IOException e) {
logger.warn("download page {} error", request.getUrl(), e);
onError(request);
return page;
}
}
项目实现逻辑
- LTS爬虫任务Cron JobRunner实现,获取LST context上下文参数,入库爬虫任务信息,获取具体媒体爬虫service类进行爬虫详情mq任务分发。
@JobRunnerItem(shardValue = CrawlerCommonConstant.CRAWLER_JOB_LTS_NAME)
public Result addCrawlerJob(JobContext context) {
String crawlerJobDesc = null;
try {
Map<String, String> extParams = context.getJob().getExtParams();
CrawlerJobVo crawlerJobVo = JSON.parseObject(JSON.toJSONString(extParams), CrawlerJobVo.class);
//更新爬虫任务
CrawlerJob crawlerJob = crawlerJobService.doHandlerCrawlerJob(crawlerJobVo);
crawlerJobDesc = MediaTypeEnum.getEnum(crawlerJob.getMediaId()).getDesc() +
CrawlerTypeEnum.getEnum(crawlerJob.getCrawlerType()).getDesc();
//映射抽象类处理
AbstractCrawlerService abstractCrawlerService = applicationContext.getBean(crawlerInstanceName(crawlerJobVo), AbstractCrawlerService.class);
abstractCrawlerService.crawlHandler(crawlerJob.getId(),crawlerJob.getMediaId(),crawlerJob.getCrawlerType());
context.getBizLogger().info(crawlerJobDesc+"爬虫任务推送成功" );
return new Result(Action.EXECUTE_SUCCESS, crawlerJobDesc+"爬虫任务推送成功" );
} catch (Exception e) {
logger.warn(crawlerJobDesc + "爬虫任务推送失败,{}", e);
return new Result(Action.EXECUTE_FAILED, e.getMessage());
}
}
- AbstractCrawlerService初始化任务详情计数集合,计数锁,失败计数锁,任务详情失败计数集合,实现HttpClientDownloader页面加载失败的逻辑处理,提供了获取爬虫实现的方法,获取爬虫链接正则表达式的抽象方法,提供爬虫任务与详情子任务的入库与统计方法等
public abstract class AbstractCrawlerService implements InitializingBean {
/**
* 获取爬虫连接
*/
public abstract String getCrawlUrl();
/**
* 需要具体爬虫实现的方法
* 默认实现
* @param jobId
* @param mediaId
* @param crawlerType
*/
public abstract void crawlHandler(Integer jobId,Integer mediaId,Integer crawlerType);
@Override
public void afterPropertiesSet() throws Exception {
//任务详情失败计数集合
failCountMap = new ConcurrentHashMap<>();
//任务详情计数集合
countMap = new ConcurrentHashMap<>();
//计数锁
countlock = new ReentrantLock();
//失败计数锁
failCountlock = new ReentrantLock();
httpClientDownloader = new HttpClientDownloader(){
@Override
protected void onError(Request request) {
String crawlerJobNum = JSON.parseObject(request.getExtra("crawler_param").toString()).getString("crawlerJobNum");
failCountlock.lock();
try {
AtomicInteger countInteger = countMap.get(crawlerJobNum);
if (countInteger == null) {
countInteger = new AtomicInteger(0);
countInteger.incrementAndGet();
countMap.put(crawlerJobNum, countInteger);
}else {
countInteger.incrementAndGet();
}
} finally {
failCountlock.unlock();
}
logger.warn("页面加载异常,爬虫任务序号{}重试次数为:{}", crawlerJobNum, countMap.get(crawlerJobNum).get());
if (countMap.get(crawlerJobNum).get() == CrawlerCommonConstant.SPIDER_RETRY_TIMES) {
logger.warn("页面加载异常,爬虫任务序号:{}链接抓取失败",crawlerJobNum);
//任务状态,0成功,1失败
dealWithDetailJob(request.getExtra("crawler_param").toString(), request.getUrl(),1, "爬虫链接页面加载失败");
failCountMap.remove(crawlerJobNum);
}
}
};
httpClientDownloader.setProxyProvider(dndcProxyPoolProvider);
}
}
- 详情子任务参数封装,加锁计算任务总数,通过while循环每间隔5分钟计算成功子任务数与失败子任务数,遇到异常退出循环
public abstract class BaseCrawlerService extends AbstractCrawlerService{
//推送爬虫 实时任务
asyncInvoker.execute(new Runnable() {
@Override
public void run() {
//并发计数
countlock.lock();
try {
AtomicInteger countInteger = countMap.get(crawlerDetailJobMap.get("jobId"));
if (countInteger == null) {
countInteger = new AtomicInteger(0);
countInteger.incrementAndGet();
countMap.put(crawlerDetailJobMap.get("jobId"), countInteger);
}else {
countInteger.incrementAndGet();
}
//crawlerDetailJobMap消息body数据封装
crawlerDetailJobMap.put("mqKey", MessageFormat.format(CrawlerCommonConstant.CRAWLER_JOB_MQ_KEY,jobId.toString(),
String.valueOf(countMap.get(crawlerDetailJobMap.get("jobId")).get())));
crawlerDetailJobMap.put("crawlerJobNum", String.valueOf(countMap.get(crawlerDetailJobMap.get("jobId")).get()));
} finally {
countlock.unlock();
}
//mq任务推送
mqCrawlerJobHandler.handle(crawlerDetailJobMap);
}
});
//启动任务间隔计数
asyncInvoker.execute(new Runnable() {
@Override
public void run() {
try {
//获取爬虫任务
CrawlerJob crawlerJob = getCrawlerJob(jobId);
long crawlerStartTime = SystemClock.now();
if (crawlerJob != null) {
while (crawlerJob.getSuccessTasks() + crawlerJob.getFailureTasks() != countMap.get(String.valueOf(jobId)).get()) {
int successTasks = getJobDetailStatusStatistics(jobId, 0);
int failureTasks = getJobDetailStatusStatistics(jobId, 1);
logger.info("{}{}爬虫任务id:{},推送爬虫mq总任务数:{},成功任务数:{},失败任务数:{}",MediaTypeEnum.getEnum(mediaId).getDesc(),CrawlerTypeEnum.getEnum(crawlerType).getDesc(),jobId,
countMap.get(String.valueOf(jobId)).get(), successTasks, failureTasks);
boolean exitFlag = dealWithJob(jobId, countMap.get(String.valueOf(jobId)).get(), successTasks, failureTasks);
crawlerJob = getCrawlerJob(jobId);
//计数完成或者计数异常退出循环
if (!exitFlag || crawlerJob.getSuccessTasks() + crawlerJob.getFailureTasks() == countMap.get(String.valueOf(jobId)).get()) {
break;
}
Thread.sleep(CrawlerCommonConstant.JOB_STATISTICAL_INTERVAL);
}
logger.info("{}{}爬虫任务id:{}统计完成,耗时{},循环方法次数:{}",MediaTypeEnum.getEnum(mediaId).getDesc(),CrawlerTypeEnum.getEnum(crawlerType).getDesc(),jobId,
SystemClock.now() - crawlerStartTime,totalCount.get());
}
} catch (Exception e) {
logger.warn("{}{}爬虫任务id:{}统计异常 {},{}", MediaTypeEnum.getEnum(mediaId).getDesc(), CrawlerTypeEnum.getEnum(crawlerType).getDesc(), jobId, e.getMessage(), e);
}finally {
countMap.remove(String.valueOf(jobId));
}
}
});
}
- 推送mq爬虫任务,设置key,唯一定位消息,排查与定位问题事半功倍,延时10秒推送,测试环境项目由于使用RocketMq配置默认10秒推送,线上环境使用阿里云ONS消息服务,可指定具体时间定时消息。
Tip:RocketMQ 支持定时消息,但是不支持任意时间精度,仅支持特定的 level,例如定时 5s, 10s, 1m 等。其中,level=0 级表示不延时,level=1 表示 1 级延时,level=2 表示 2 级延时,以此类推。
@Component
public class CrawlerMqProcessor {
/**
* 推送爬虫链接子任务数据
* @param crawlerDetailJobMap
*/
public void sendCrawlerDetailJob(Map<String,String> crawlerDetailJobMap) {
Message jobMessage = new Message();
jobMessage.setTopic(config.getChebabaCrawlerJobTopic());
//延迟10秒推送
jobMessage.setStartDeliverTime(System.currentTimeMillis() + 10000);
jobMessage.setTag(crawlerDetailJobMap.get("dataType"));
jobMessage.setBody(JSON.toJSONString(crawlerDetailJobMap).getBytes());
jobMessage.setKey(crawlerDetailJobMap.get("mqKey"));
SendResult priceSendResult = producer.send(jobMessage);
LOGGER.info("推送爬虫链接子任务数据,job_id:{},media_id:{},crawler_type:{},crawler_unique_id:{},crawler_job_num:{},{}",crawlerDetailJobMap.get("jobId"),
crawlerDetailJobMap.get("mediaId"), crawlerDetailJobMap.get("crawlerType"),crawlerDetailJobMap.get("crawlerUniqueId"),
crawlerDetailJobMap.get("crawlerJobNum"),priceSendResult);
}
}
- mq消息监听器
@Component("crawlerJobListener")
public class CrawlerJobListener implements MessageListener {
@Override
public Action consume(Message message, ConsumeContext consumeContext) {
//创建爬虫实例
Request crawlerRequest = new Request(crawlerUrl);
crawlerRequest.putExtra("crawler_param",detailJobJson);
Spider.create(abstractCrawlerProcessor).setDownloader(abstractCrawlerService.getHttpClientDownloader()).addRequest(crawlerRequest)
.setSpiderListeners(addSpiderListeners(bodyParams, crawlerUrl)).addPipeline(baseCrawlerPipeline).thread(threadNums).run();
return Action.CommitMessage;
} catch (Exception e) {
logger.warn("{}爬虫链接执行失败,{},{}", crawlerUrl, e.getMessage(), e);
//任务失败
//任务状态,0成功,1失败
dealWithDetailJob(bodyParams, crawlerUrl,1, "爬虫链接执行失败");
return Action.ReconsumeLater;
}
}
/**
* 添加爬虫监听器
* @param bodyParams
* @param crawlerUrl
* @return
*/
private ArrayList<SpiderListener> addSpiderListeners(String bodyParams,String crawlerUrl) {
ArrayList<SpiderListener> spiderListeners = new ArrayList<>();
spiderListeners.add(new SpiderListener() {
volatile int failureCount = 0;
@Override
public void onSuccess(Request request) {
}
@Override
public void onError(Request request) {
failureCount++;
logger.info("爬虫任务序号{}重试次数为:{}", JSON.parseObject(bodyParams).get("crawlerJobNum"), failureCount);
if (failureCount == CrawlerCommonConstant.SPIDER_RETRY_TIMES) {
logger.warn("爬虫任务序号:{}链接解析失败",JSON.parseObject(bodyParams).get("crawlerJobNum"));
//任务状态,0成功,1失败
dealWithDetailJob(bodyParams, crawlerUrl,1, "爬虫链接解析失败");
}
}
});
return spiderListeners;
}
}
- AbstractCrawlerProcessor实现通用方法,process方法爬虫页面解析具体处理
public abstract class AbstractCrawlerProcessor implements PageProcessor{
public Site getSiteConfig() {
Site site = Site.me().setCycleRetryTimes(CrawlerCommonConstant.SPIDER_RETRY_TIMES).setRetryTimes(CrawlerCommonConstant.SPIDER_RETRY_TIMES).
setSleepTime(CrawlerCommonConstant.SPIDER_SLEEP_TIME).setTimeOut(CrawlerCommonConstant.SPIDER_TIME_OUT_TIME);
site.addHeader("Accept",
"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8");
site.addHeader("Accept-Encoding", "gzip, deflate");
site.addHeader("Accept-Language", "zh-CN,zh;q=0.8,en;q=0.6");
site.addHeader("Cache-Control", "max-age=0");
site.addHeader("Connection", "keep-alive");
site.addHeader("Cookie", "_lxsdk_cuid=" + UUID.randomUUID().toString().replaceAll("-", "") + ";SESSION="
+ UUID.randomUUID().toString());
site.addHeader("Upgrade-Insecure-Requests", "" + Math.random());
site.addHeader("User-Agent",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36");
//添加站点接收状态码
Set<Integer> acceptStatCode = new HashSet<>();
//成功标识码
acceptStatCode.add(200);
//错误网关
acceptStatCode.add(502);
//请求过多
acceptStatCode.add(429);
site.setAcceptStatCode(acceptStatCode);
return site;
}
}
- 管道数据处理,原始数据入队列Queue添加LTS任务每5分钟消费,推送预警mq任务等待报价数据阈值校验与截屏邮件或短信定时通知,推送业务数据到redis添加LTS任务每5分钟批量添加到Elasticsearch
@Component
public class BaseCrawlerPipeline implements Pipeline {
@Override
public void process(ResultItems resultItems, Task task) {
CrawlerDetailJobVo detailJobVo = resultItems.get("crawlerDatas");
if( null == detailJobVo ){
return;
}
if (StringUtil.isBlank(detailJobVo.getRemark())) {
detailJobVo.setRemark("爬虫链接执行成功");
}
//添加爬虫详情任务
CrawlerCommonConstant.queue.offer(detailJobVo);
//推送原始数据,及预警数据
List<Map> mqCrawlerDatas = JSONArray.parseArray(detailJobVo.getCrawlerData(), Map.class);
if (detailJobVo.getCrawlerData() != null && mqCrawlerDatas != null && mqCrawlerDatas.size() > 0) {
CrawlerMqVo mqVo = new CrawlerMqVo();
mqVo.setJobId(detailJobVo.getJobId());
if (detailJobVo.getCrawlerType().equals(CrawlerCommonConstant.CRAWLER_TYPE_PRICE_FLAG)) {
mqVo.setCrawlerCode(CrawlerCommonConstant.CRAWLER_TYPE_PRICE);
}
if (detailJobVo.getCrawlerType().equals(CrawlerCommonConstant.CRAWLER_TYPE_CMS_ARTICLE_FLAG)) {
mqVo.setCrawlerCode(CrawlerCommonConstant.CRAWLER_TYPE_CMS_ARTICLE);
}
if (detailJobVo.getCrawlerType().equals(CrawlerCommonConstant.CRAWLER_TYPE_ACTIVITY_SALES_FLAG)) {
mqVo.setCrawlerCode(CrawlerCommonConstant.CRAWLER_TYPE_ACTIVITY_SALES);
}
mqVo.setCrawlerPkData(detailJobVo.getDealerCode());
mqVo.setMediaId(detailJobVo.getMediaId());
//过滤掉 es 显示数据
if (mqCrawlerDatas != null && mqCrawlerDatas.size() > 0) {
mqCrawlerDatas = mqCrawlerDatas.stream().map(x -> {
x.remove("esParamMap");
return x;
}).collect(Collectors.toList());
}
mqVo.setCrawlerData(JSONArray.toJSONString(mqCrawlerDatas));
mqVo.setCrawlerUrl(detailJobVo.getCrawlerUrl());
mqVo.setCrawlerDate(ConcurrentDateUtil.format(new Date()));
crawlerMqProcessor.sendCrawlerInstanceData(mqVo);
}
//添加本品数据到缓存
List<Map> crawlerDatas = JSONArray.parseArray(detailJobVo.getCrawlerData(), Map.class);
if (crawlerDatas!=null && crawlerDatas.size() > 0) {
crawlerDatas = crawlerDatas.stream().filter(x -> x.get("esParamMap") != null).map(x -> {
Map esCrawlerMap = new HashMap();
esCrawlerMap.putAll(JSONObject.parseObject(MapUtils.getString(x, "esParamMap")));
return esCrawlerMap;
}).collect(Collectors.toList());
detailJobVo.setCrawlerData(JSONArray.toJSONString(crawlerDatas));
redisTemplateUtil.setCacheList(CrawlerCommonConstant.CRAWLER_LIST_CACHE_COMPETITOR_KEY,detailJobVo );
}
}
}
总结
这次爬虫项目的重构,是锻炼自己的一次很好机会,见证了一个项目的设计到实现的全过程。在设计的过程中把自己的想法付诸实践,一点点实现它,感觉蛮有成就感的。
当然也有一些困难的需要克服。一个系统从设计到实现是一个不易的过程,不可能一蹴而就,很多问题会反复出现,一个功能模块的实现,要经历数据库字段的增加删除,算法的改进,逻辑的错误实现等一系列改进,才能最终完成目标。
特别是这次项目爬虫的爬取数量一多,定位问题变得极其花费心力,多打印日志,细心点,多抱怀疑的态度看待项目用的框架,才能定位到问题,再具体想解决的办法。例如这次使用的webmagic框架,在爬虫请求过多被限时,爬取的页面信息状态码429(成功状态码200)在新版源码才有日志打印,配合站点设置,才能进行后面爬虫失败监听器处理逻辑,还有download页面失败带来的问题以及怎么想办法记录这次爬虫任务的失败情况,方便后面进行爬虫任务计数与重试。很感谢有这次经历,让自己积累经验,慢步前进。