全文检索技术Lucene
一. Lucene 简介
1. Lucene 是什么
Lucene 是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎。说到底它是一个信息检索程序库,而不是应用产品。因此它并不像百度或者 google 那样,拿来就能用,它只是提供了一种工具让你能实现这些产品。
2 . Lucene 能做什么
要回答这个问题,先要了解 lucene 的本质。实际上 lucene 的功能很单一,说到底,就是我们给它若干个字符串,然后它为我们提供一个全文搜索服务,最后告诉我们要搜索的关键词出现在哪里。知道了这个本质,我们就可以发挥想象做任何符合这个条件的事情了。比如我们可以把站内新闻都索引了,做个资料库;也可以把一个数据库表的若干个字段索引起来,那就不用再担心因为“%like%”而锁表了;学完 lucene,你也可以写个自己的搜索引擎了……
3 . Lucene 速度测试
下面给出一些测试数据,如果你觉得可以接受,那么可以选择。
测试一:250 万记录,300M 左右文本,生成索引 380M 左右,800 线程下平均处理时间 300ms。
测试二:37000 记录,索引数据库中的两个 varchar 字段,索引文件2.6M,800 线程下平均处理时间 1.5ms。
二. 深入lucene
1. 为什么 lucene 这么快
1、倒排索引
2、压缩算法
3、二元搜索
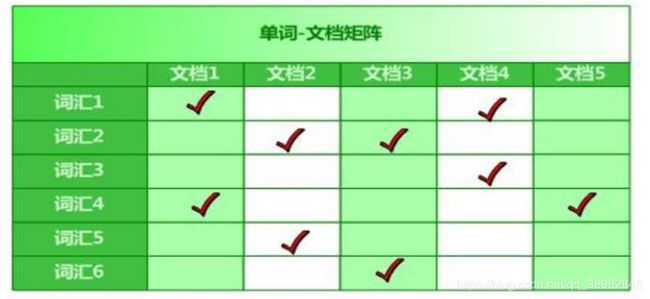
2. 倒排序索引
它是根据属性的值来查找记录。
这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址由于不是由记录来确定属性值,
而是由属性值来确定记录的位置,因而称为倒排索引(invertedindex) 如下简单的例子
3. 工作方式
Lucene 提供的服务实际包含两部分:一入一出。所谓入是写入,即将你提供的源(本质是字符串)写入索引或者将其从索引中删除;所谓出是读出,即向用户提供全文搜索服务,让用户可以通过关键词定位源。
4. 写入流程
- 源字符串首先经过 analyzer 处理,包括:分词,分成一个个单词去除 stopword(可选)。
- 将源中需要的信息加入 Document 的各个 Field(信息域)中,并把需要索引的 Field 索引起来,把需要存储的 Field 存储起来。
- 将索引写入磁盘。
5. 读出流程
- 用户提供搜索关键词,经过 analyzer 处理。
- 对处理后的关键词搜索它的索引,找出对应的 Document。
- 用户根据需要从找到的 Document 中提取需要的 Field。
6. Docement
用户提供的源是一条条记录,它们可以是文本文件, 字符串或者数据库表的一条记录等等。一条记录经过索引之后,就是以一个Document 的形式存储在索引文件中的, 用户进行搜索也是以Document 列表的形式返回。
7. Field
一个 Document 可以包含多个信息域,例如一篇文章可以包含“标题”、“正文”、“最后修改时间”等信息域,这些信息域就是通过 Field在 Document 中存储的。Field 有两个属性可选:存储和索引。通过存储属性你可以控制是否对这个 Field 进行存储;通过索引属性你可以控制是否对该Field 进行索引。这看起来似乎有些废话,事实上对这两个属性的正确组合很重要。
8. 实现原理
文本倒排处理:

Lucene 整体使用如图所示:

9. 环境配置
9-1 下载jar包的方式
下载 lucene jar
官网:https://lucene.apache.org/
导入 jar 到项目中
我下载的为7-5-0版本的zip,架包引入下面依赖中的jar就行,但是org.apache.commons.io
必须从依赖库里面引入,本人建议你可以建个maven项目,然后只引入org.apache.commons.io
依赖,其他的几个直接把你下载的zip解压,找到里面的对应架包引入就行,因为maven库里面的版本较低
9-2或者加入依赖,相关依赖如下:
<dependencies>
<!--测试环境-->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>compile</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.directory.studio/org.apache.commons.io -->
<dependency>
<groupId>org.apache.directory.studio</groupId>
<artifactId>org.apache.commons.io</artifactId>
<version>2.4</version>
</dependency>
<!-- http://mvnrepository.com/artifact/org.apache.lucene/lucene-analyzers-common -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>4.10.3</version>
</dependency>
<!-- http://mvnrepository.com/artifact/org.apache.lucene/lucene-queryparser -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
<version>4.10.3</version>
</dependency>
<!-- http://mvnrepository.com/artifact/org.apache.lucene/lucene-core -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>4.10.3</version>
</dependency>
</dependencies>
10. 创建索引
Lucene的最重要的工作流程就是先给你查询的东西创建索引,也即给你要查询的数据按照Lucene的方式创建索引,这样才会搜索的更快,使用第一步让我们给数据创建索引,直接上代码啦!!! 注释写的比较啰嗦.
两个成员变量:
//要搜索的目录路径
String pathSearch = "C://Users//威威//Desktop//课堂内容//第15周//day 5";
//索引要存放的路径
String pathIndex = "C://Users//威威//Desktop//课堂内容//第16周//day 5//testLucene";
正式的建索引代码:
@Test
public void createIndex() throws IOException {
//索引存放的目录文件夹
File indexRepositoryFile = new File(pathIndex);
//得到目录的文件路径(不能直接用上面的path,不然会报错)
Path directoryPath = indexRepositoryFile.toPath();
//lucene进行搜索的目录
Directory directory = FSDirectory.open(directoryPath);
//准备你想要搜索的目录文件
File searchFiles = new File(pathSearch);
//获取一个标准分词器
Analyzer analyzer = new StandardAnalyzer();
//配置indexWriterConfig
//IndexWriterConfig indexWConfig = new IndexWriterConfig();
IndexWriterConfig indexWConfig = new IndexWriterConfig(analyzer);
//指定索引写入的模式
indexWConfig.setOpenMode(IndexWriterConfig.OpenMode.CREATE_OR_APPEND);
//通过索引目录与配置信息得到writer
IndexWriter writer = new IndexWriter(directory, indexWConfig);
//遍历读取文件目录pathSearch里的所有文件,非常重要,如果直接遍历杜会报错(文件存在,但它是个目录)
Collection<File> files = FileUtils.listFiles(searchFiles, TrueFileFilter.INSTANCE,TrueFileFilter.INSTANCE);
//遍历读取目录里的所有文件
for(File file : files){
//得到文件名
String fileName = file.getName();
//文件内容
String fileContent = FileUtils.readFileToString(file);
//文件路径
String filePath = file.getPath();
//文件大小
Long fileSize = FileUtils.sizeOf(file);
//创建一个document对象
Document document = new Document();
// 向Document对象中添加域信息
// 参数:1、域的名称;2、域的值;3、是否存储;
Field nameField = new TextField("name",fileName,Store.YES );
Field contentField = new TextField("content", fileContent, Store.YES);
// storedFiled默认存储
Field pathField = new StoredField("path",filePath );
Field sizeField = new StoredField("size",fileSize );
// 将域添加到document对象中
document.add(nameField);
document.add(contentField);
document.add(pathField);
document.add(sizeField);
//将信息写入到检索库中
writer.addDocument(document);
}
//关闭indexWriter
writer.close();
}
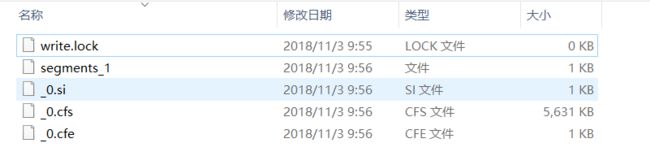
点击运行会在你索引目录生成索引文件:
11. 查询索引
上面索引建立好了,此时你要全文检索,检索已经建好索引的目录就行了,不再索引源文件的目录.
正式搜索代码:
@Test
public void search() throws IOException, ParseException {
//指定索引的目录并打开,路径不能直接给,必须转化一下
File file = new File(pathIndex);
Path path = file.toPath();
Directory directory = FSDirectory.open(path);
//得到一个基础分词器,查询也需要分词操作,假如用户输入的内容很长
Analyzer analyzer = new StandardAnalyzer();
IndexReader indexReader = DirectoryReader.open(directory);
//创建IndexSearch对象
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
//创建一个分析器
QueryParser parser = new QueryParser("content",analyzer);
//要查询的东西
Query query = parser.parse("用");
/*// 创建一个查询对象
TermQuery termQuery = new TermQuery(new Term("name", "crm"));*/
// 执行查询
// 返回的最大值,在分页的时候使用
TopDocs topDocs = indexSearcher.search(query, 10);
// 取查询结果总数量
System.out.println("总共的查询结果:" + topDocs.totalHits);
// 查询结果,就是documentID列表
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for (ScoreDoc scoreDoc : scoreDocs) {
// 取对象document的对象id
int docID = scoreDoc.doc;
// 相关度得分
float score = scoreDoc.score;
// 根据ID去document对象
Document document = indexSearcher.doc(docID);
/*System.out.println("相关度得分:" + score);
System.out.println("");
System.out.println("文件的名字: "+document.get("name"));
System.out.println("");*/
// 另外的一种使用方法
System.out.println(document.getField("content").stringValue());
System.out.println(document.get("path"));
System.out.println();
System.out.println("=======================");
}
indexReader.close();
}
12. Lucene的其他功能
12-1 分词器
Lucene 自带的 StandardAnalyzer 分词器,只能对英语进行分词。
在对中文进行分词的时候采用了一元分词,即每一个中文作为一个词,
如“我是中国人”,则分词结果为“我”,“是”,“中”,“国”,“人”,
可以看出分词效果很差。在这里推荐一个比较好用的中文分词器
IKAnalyzer。
12-2 停用词
停用词是指在信息检索中,为节省存储空间和提高搜索效率,在
处理自然语言数据(或文本)之前或之后会自动过滤掉某些字或词,
这些字或词即被称为 Stop Words(停用词)。比如中文中“了”, “么”,
“呢”,“的”等意义不大且在一篇文章中出现频率又很高的词,又比
如英文中的”for”,”in”,”it”,”a”,”or”等词。
在使用 IKAnalyzer 分词器的时候,可以在 IKAnalyzer.cfg.xml
里配置相关信息,如下图:
<?xml version="1.0" encoding="UTF-8"?>
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户在这可以配置自己的扩展字典-->
<entry key="ext_dict">ext_dict;</entry>
<!--用户可以在这里配置自己的停止词字典-->
<entry key="ext_stopwords">stopword.dic;chinese_stopword.dic</entry>
</properties>
12-2 高亮-Highlighter
高亮是什么?来看一下百度就知道了
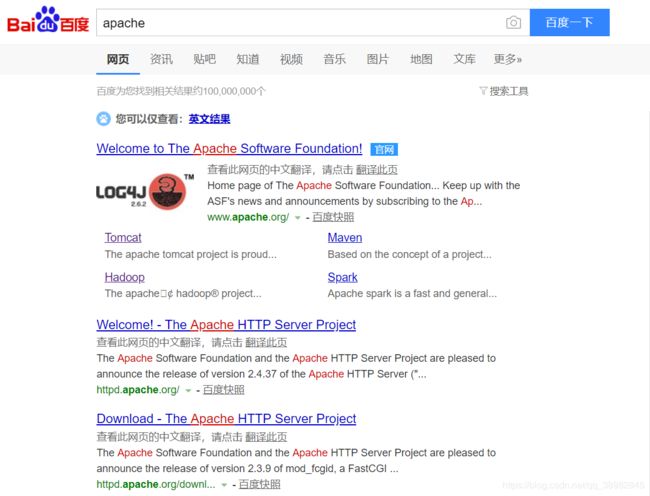
红色的就是关键词高亮显示了,引入里面的高亮jar包就行了,自己可以设置.
三. Lucene相关概念补充
1. Field属性
Field 是文档中的域,包括 Field 名和 Field 值两部分,一个文档可以包括多个 Field,Document 只是 Field 的一个承载体,Field值即为要索引的内容,也是要搜索的内容。
- 是否分词(tokenized)
- 是:作分词处理,即将 Field 值进行分词,分词的目的是为了索引。比如:商品名称、商品简介等,这些内容用户要输入关键字搜索,由于搜索的内容格式大、内容多需要分词后将语汇单元索引。
- 否:不作分词处理比如:商品 id、订单号、身份证号等
- 是否索引(indexed)
- 是:进行索引。将 Field 分词后的词或整个 Field 值进行索引,索引的目的是为了搜索比如:商品名称、商品简介分词后进行索引,订单号、身份证号不用分词但也要索引,这些将来都要作为查询条件。
- 否:不索引。该域的内容无法搜索到比如:商品 id、文件路径、图片路径等,不用作为查询条件的不用索引。
- 是否存储(stored)
- 是:将 Field 值存储在文档中,存储在文档中的 Field 才可以从
Document 中获取。比如:商品名称、订单号,凡是将来要从 Document 中获取的 Field都要存储。 - 否:不存储 Field 值,不存储的 Field 无法通过 Document 获取
比如:商品简介,内容较大不用存储。如果要向用户展示商品简介可以从系统的关系数据库中获取商品简介。如果需要商品描述,则根据搜索出的商品 ID 去数据库中查询,然后显示出商品描述信息即可。
- 是:将 Field 值存储在文档中,存储在文档中的 Field 才可以从
2. Field 常用类型
开发中常用 的 Filed 类型,注意 Field 的属性,根据需求选择:

3. 例子
- 图书 id:
- 是否分词:不用分词,因为不会根据商品 id 来搜索商品
- 是否索引:不索引,因为不需要根据图书 ID 进行搜索
- 是否存储:要存储,因为查询结果页面需要使用 id 这个值
- 图书名称:
- 是否分词:要分词,因为要将图书的名称内容分词索引,根据关键搜索图书名称抽取的词。
- 是否索引:要索引。
- 是否存储:要存储
- 图书价格:
- 是否分词:要分词,lucene 对数字型的值只要有搜索需求的都要分词和索引,因为 lucene 对数字型的内容要特殊分词处理,本例子可能要根据价格范 围搜索,需要分词和索引。
- 是否索引:要索引
- 是否存储:要存储
- 图书图片地址:
- 是否分词:不分词
- 是否索引:不索引
- 是否存储:要存储
- 图书描述:
- 是否分词:要分词
- 是否索引:要索引
- 是否存储:因为图书描述内容量大,不在查询结果页面直接显示,不存储。 不存储是来不在 lucene 的索引文件中记录,节省 lucene的索引文件空间, 如果要在详情页面显示描述,思路: 从 lucene中取出图书的 id,根据图书的 id 查询关系数据库中 book 表 得到描述信息。