机器学习--scikit-learn库(2)
上一节讲的是scikit-learn库的最简单的用法。
现在要更加进阶啦~
头一节的第三个问题是如何使用scikit-learn的官网,其实我现在也不太清楚,还是跟着练习的时候到需要查看官方文档的时候自己慢慢摸索吧。
这篇笔记要记录的是,库里面的datasets到底有哪些?以及模型的参数如何查看的问题,还有归一化数据的问题。
首先我想去看看scikit-learn中到底有多少自带的数据库。
点进官网先~官网大概长成这样滴

然后点首页上方的documentation中的API,意思是接口的意思。

进API页面的左边部分找找找~总算找到啦,也不是很难嘛。
sklearn.datasets。里面写了库中自己加载了多少datasets,比如datasets.load_iris()就是上一篇文章里面用到的花的数据。
还有波士顿房价、乳腺癌发病率记录之类的,都可以用作练习使用。甚至还可以自己生成数据。

这个问题解决之后,我们再来看一个例子。这个例子我们使用逻辑回归模型来对花的种类进行分类。
#先拟合模型
model = LogisticRegression()
model.fit(x_train,y_train)
#测试模型性能
print(model.predict(x_test))
print(model.score(x_test,y_test))
print(model.get_params())#得到模型中设置的参数
print(model.coef_)#y = αx + γ 中的参数α也就是权重
print(model.intercept_)#γ,是偏置bias在测试模型性能的部分,model.get_params()是得到对每个模型设置的参数。比如对于逻辑回归模型来说,有14个参数,可以设置正则惩罚项之类的。我现在直接用的model = LogisticRegression()意思就是按照默认值。
参数会看了之后,现在来谈论数据归一化的问题。
归一化的意思实际上是数据压缩到某个范围内,比如很常见的高斯分布,标准高斯分布。这个标准就是把归一化之后的高斯过程,这样把各个样本数值偏差很大的数据放在了0-1之间,更利于ml得到更加精准的结果。(也就是每个样本值减去均值然后除以方差)
在sklearn中是利用sklearn.preprocessing.scale()实现的。
我们可以对比一下归一化和没有归一化的数据的模型训练准确率。
例子如下:
from sklearn.preprocessing import scale
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.datasets.samples_generator import make_classification
from sklearn.svm import SVC
import matplotlib.pyplot as plt
# a = np.array([[10,2.7,3.6],[-100,5,-2],[120,20,40]],dtype=np.float64)
# #这个数据跨度就非常大了,可以归一化。
# print(scale(a))
#加载数据 在这个练习中我们自己生成数据
x,y = make_classification(n_samples=300,n_features=2,
n_redundant=0,n_informative=2,
random_state=22,
n_clusters_per_class=1,scale=100
)
#300个data,两个比较相关的feature,random_state=22意味着每次产生的数都是一样的。
plt.scatter(x[:,0],x[:,1],c=y)#画散点图
plt.show()
运行上述程序之后,发现数据跨度很大。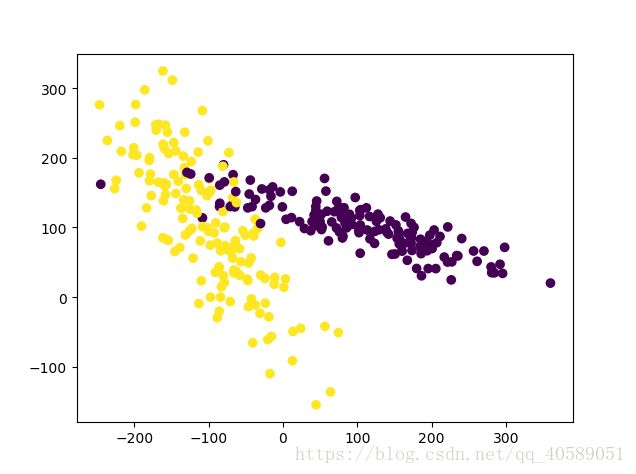
随后我们添加如下代码:
#压缩数据到0-1
X = scale(x)#压缩数据
x_train,x_test,y_train,y_test = train_test_split(X,y,
test_size=0.3,
random_state=0)
clf = SVC()#用支持向量机模型来进行分类
clf.fit(x_train,y_train)
print(clf.score(x_test,y_test))运行后的准确率为: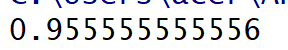
如果不压缩,准确率会骤降到:

所以在数据跨度比较大的时候,需要对数据进行标准化的预处理。
后续文章会记录我学习交叉检验的心得体会~