Java异步编程简析
Java异步编程引言
Java的异步编程其实是一个充分利用计算机CPU资源,不想让主程序阻塞在某个长时间运行的任务上,这类耗时的任务可以是IO操作、远程调用以及高密度计算任务。如果不使用多线程异步编程,我们的系统就会阻塞在耗时的子任务上,会导致极大延长完成主函数任务的时间。Java以及提供了丰富的API,来完成多线程异步编程。从NIO、Future,CompletableFuture、Fork/Join以及parrallelStream。另外google的guava框架提供了ListenableFuture和Spring的@Async来简化异步编程。
项目实战
先从自己做的一个项目来实际具体说明多线程的使用吧,观察该系统中资源池显示,需要展示4个节点类型的数据。大概分为两种节点,一种是计算节点,需要计算vcpu、内存和存储等,包含图中前三个节点。另外一种是网络资源,计算用户路由以及占用带宽等,及图中最后一个节点。
- 展示图如下
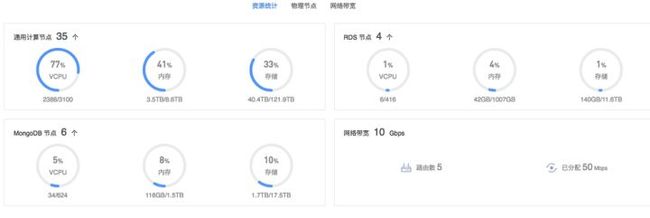
核心任务分析
资源统计任务中包含三类耗时操作,在调用底层接口时,需要用多线程异步去获取结果。
- 1、调用底层云网络接口
- 2、调用底层云主机接口获取所有宿主机的后端存储
- 3、调用底层云主机接口获取所有可用域下宿主机列表
实现过程
项目主要采用两个线程池来实现异步化编程。自定义一个线程池,用于指定Spring框架的@Async注解使用的线程池以及CompletableFuture使用的线程池。初始化线程池时需要设置任务拒绝策略,我们一般选取CallerRunsPolicy,即当线程池的任务缓存队列已满并且线程池中的线程数目达到最大线程池大小时,任务交给调用线程处理。
@Component
public class OperationAsyncExecutor {
private int corePoolSize = 3;
private int maxPoolSize = 6;
private int queueCapacity = 50;
public static String ThreadNamePrefix = "op-async-exec-";
public static final String OPERATION_ASYNC_EXECUTOR = "OperationSyncExecutor";
@Bean(value = OPERATION_ASYNC_EXECUTOR)
public Executor opAsyncExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(corePoolSize);
executor.setMaxPoolSize(maxPoolSize);
executor.setQueueCapacity(queueCapacity);
executor.setThreadNamePrefix(ThreadNamePrefix);
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
executor.initialize();
return executor;
}
}
使用Spring框架提供的@Async注解来实现获取所有路由信息的异步化处理。
@Async("OperationSyncExecutor")
public Future> getAllNetworkRouter(String partnerTenantid) {
List routers = Lists.newArrayList();
List allTenantids = nceRequestHelper.getTenants(partnerTenantid);
if (allTenantids.isEmpty()) {
return new AsyncResult<>(routers);
}
routers = middleTierRequestHelper.getRouters(allTenantids);
return new AsyncResult<>(routers);
}
指定线程池来执行异步任务,及获取所有宿主机对应的存储。
CompletableFuture> hostStorageFuture = CompletableFuture.supplyAsync(()->{
return middleTierRequestHelper.getHostStorage();
}, opSyncExecutor);
本统计任务最耗时的是获取可用域下的宿主机列表,由于底层接口存在优化空间,调用该接口需要2.5s左右。而每个节点下又有3个可用域,如果采用顺序执行,那么资源统计的接口将达到10s以上,这是不可以忍受的。所有这里我们采用Executors.newCachedThreadPool()来获取线程池。来充分利用多线程异步化,来提高接口性能。
List>>> futures = Lists.newArrayList();
getAzByService(ServiceName.COMMON).forEach(az -> {
futures.add(executorService.submit(new QueryHostTask(ServiceName.COMMON, az)));
});
getAzByService(ServiceName.RDS).forEach(az -> {
futures.add(executorService.submit(new QueryHostTask(ServiceName.RDS, az)));
});
getAzByService(ServiceName.MONGO).forEach(az -> {
futures.add(executorService.submit(new QueryHostTask(ServiceName.MONGO, az)));
});
项目实战结果
- 整个调用过程如下

目前资源统计的接口是2.6s以内,耗时在还是在底层接口上,统计任务控制在50ms以内。 关于异步编程,个人体会有以下几点:
- 一定将并行的任务粒度控制到最细。保证多线程里运行的子任务是最细的,不可以再拆分。
- 能够并行处理的,千万不要串行。
- 可以使用多个线程池,来区分不能类型的任务,充分利用线程池来提高性能。
Java异步编程拓展
关于异步编程,项目中在异步是都会调用future的get()方法,来阻塞主线程,获取最后的异步结果。在另外一种多线程编程下,可以采用监听模式,来实现在得到异步结果的处理。比如guava的ListenableFuture的callback机制以及JDK8中CompletableFuture的thenAccept、thenApply等方法都可以实现监听的效果。
parrallelStream和CompletableFuture的比较
- parrallelStream适合使用计算密集型并且没有I/O的任务,比较简单就能实现多线程处理,而且充分利用了计算机的CPU资源。因为parrallelStream底层使用的是默认的ForkJoinPool,该线程池的线程数和CPU的核心数目一致,如果线程中需要长时间的I/O,就使得其他需要使用并行流的任务阻塞。parrallelStream如果计算量比较大的话,可以采用自定义ForkJoinPool的方式,来增大线程池的线程数。
- CompletableFuture适合在并行的工作单元涉及等待I/O的操作,如比较耗时的网络请求调用。而且CompletableFuture比较灵活,有多个静态方法来完成异步结果返回之后的操作。指的注意的是,CompletableFuture的join方法相当于Future的get方法,都会阻塞住调用线程。
- 关于两者的性能比较,大家可以参考CompletableFuture 的并发性能研究。可以看出自定义ForkJoinPool的性能是有很大提升的。
总结
在我们的实际项目中,需要多用Java异步编程,来提高性能。需要注意并行的工作单元的切分,以及注意有没有共享变量的使用。如果有不合理的地方,大家多指正。