vsphere高可用
减少计划停止时间,放置计划外的停止时间,维护业务的连续性
**计划类停止时间:**设备的硬件的维护,旧的服务器淘汰,服务器的硬件升级,有些组件可以支持热插拔,但有些是不支持的,比如说主板损坏,得停机,进行维护更换,vsphere的高可用可以减少停机
非计划的停机:
对于esxi主机或者使用vcenter server 通过共享存储 使用多个网口绑定 冗余网络链路(一条上行链路出现故障,可以通过别的链路与以太网进行通信)
存储多路径 存储链路的冗余 一条链路故障 仍然可以访问到存储
这就实现了任何链路出现故障,不会出现非计划停机的状态
- 组件的角度来说
NIC teaming 多路径 使用多个网口绑定 冗余网络链路(一条上行链路出现故障,可以通过别的链路与以太网进行通信)
存储多路径 存储链路的冗余 一条链路故障 仍然可以访问到存储 这就实现了业务的连续性
服务器层面:vmotion为什么也能叫高可用:服务器要维护,用vmotion把服务器上的虚拟机迁移到别的主机上,虚拟机上的业务是没有中断的
- Storage层面
存储设备要替换:storage vmotion 虚拟机可以开机
- 数据层面
vSphere平台将虚拟机的磁盘文件复制到另一个位置,以便随时恢复,从而保护虚拟机,从删除的文件或磁盘以及损坏或受感染的客户操作系统或文件系统中恢复方面起着重要的作用。可以一定程度上减少业务中断
站点级别的容灾工具SRM:当有两个数据中心,A数据中心当掉 可以快速切换到B数据中心 B作为容灾数据中心可以保证A上面业务不中断
Vcenter server 可用性建议:
使vcenterserver及其依赖的组件具有高可用性
Vcenterserver依赖于这些主要组件:
Vcenterserver数据库:数据库为vCenter服务器存储库存项、安全角色、资源池、性能数据和其他关键信息。
为数据库创建一个集群
PCSA使内嵌的数据库 可以使外部的oracle数据库
设置本地备份和还原
身份验证标识源:
例如vcneter 单点登录和AD
使用多个冗余服务器进行设置
使用vSphere HA和vCenter服务器高可用性来保护vCenter服务器虚拟机
vSphere HA
通过一个集群的虚拟机,为运行在虚拟机中的应用程序提供快速的故障恢复和高可用性
- 防止ESXi主机故障 :虚拟机迁移到别的主机上
- 防止数据存储可访问性故障:使用VM组件保护(VMCP),受影响的虚拟机将在仍然可以访问数据存储的其他主机上重新启动
- 防止应用程序失败:它通过持续监视虚拟机并在检测到故障时重新设置虚拟机来防止应用程序故障。
- 保护vm不受网络隔离:当虚拟机的主机在管理或vSAN网络上被隔离时,它通过重新启动虚拟机来保护它们免受网络隔离。即使网络已分区,也会提供此保护。
与其他集群解决方案不同,vSphere HA使用基础结构本身保护所有工作负载:
•您不需要在应用程序或虚拟机中安装特殊软件。所有工作负载都受vSphere HA保护。在配置了vSphere HA之后,不需要采取任何操作来保护新的虚拟机。它们被自动保护。
•您可以将vSphere HA和vSphere DRS组合起来,以防止失败,并在集群内的主机之间提供负载平衡。
主机故障场景:
Vcenterserver 管理一个vsphere HA主机集群,在每个主机上有多台虚拟机,这些主机公用存储,如果一个主机故障了,vsphere HA会在其他主机上去重新启动该主机上的虚拟机,由于使共享存储,这些主机也能读取到虚拟机A和B的磁盘文件
客户操作系统故障 :vcenterserver 管理一个vsphere HA主机集群,每个主机上运行了多台虚拟机,共享存储,虚拟机通过vmwaretaools 给主机发送心跳,集群通过监听心跳来判断虚拟机是否处于存货状态,当虚拟机停止发送心跳或者虚拟机进程崩溃的时候,vsphere HA会自动重置虚拟机操作系统,虚拟机还是位于统一个主机上
应用程序故障:venterserver 管理一个vsphere HA主机集群,主机上运行多个虚拟机,虚拟机上面运行了应用程序 共享存储,当一个应用程序失败了,vsphere HA会自动在同一个主机上重新启动虚拟机
如果要实现这样的功能
要在虚拟机上安装vmware tools
监视应用程序状况,要专门用于处理虚拟机应用程序监视的第三方应用程序监视代理
启用了VMCP:vSphere HA可以检测到数据存储可访问性故障,并为受影响的虚拟机提供自动恢复。
数据存储可访问性故障:
如果启用了VMCP,vsphere HA可以检测数据存储可访问性故障(受影响的主机将无法再访问特定数据存储的存储路径),并为受影响的虚拟机提供自动的恢复
故障分为两种类型:
PDL:
永久设备丢失是一种不可恢复的可访问性丢失,当存储设备报告主机不在可以访问数据存储时发生,如果不关闭虚拟机电源,则无法还原此操作
响应可以是问题事件或关机并重新启动vm。
APD:
可恢复的
所有路径断开 表示暂时或未知的可访问性故障或I/O处理中的任何其他未确定的延迟,这种类型的可访问性问题时可以恢复的
在配置VMCP的时候可以选择带有PDL的数据存储或者带有APD的数据存储
响应可以是问题事件,关闭并重新启动VM-保守重启策略''或关闭并重新启动VM-积极的重启策略’’
保守: 受影响的Vms会被关闭电源,然后在连接正常的ESXi主机上重启。如果故障主机无法与Master主机通讯则将无法激活
积极:受影响的Vms会被关闭电源,无论是否有主机可以通过重启承载这些Vms。不论Master主机是否存在,是否能和其它主机通讯以及是否有足够的资源
防止VM网络隔离(整个环境里面的所有主机或者部分主机和谁都通不了信,vcenter ,ha其他主机,隔离网关也通不了信)
如果它们的主机在管理或vSAN网络上被隔离,vSphere HA将重新启动VMs。
所有的esxi 主机检测不到互相的心跳,
主机网络隔离发生在主机仍在运行时,但它不再能在管理网络上观察来自vSphere HA代理的流量:
vSphere HA尝试ping集群隔离地址。网络隔离地址是一个IP地址,用来判断主机是否与网络隔离。只有当主机已停止从群集内的任何其他主机
接收检测信号时才 ping 此地址。如果主机可以 ping 其网络隔离地址,则说明该主机并未与网络隔离,并且群集内的其他主机已发生故障。但是,如果主机无法 ping 其隔离地址,则可能该主机已与网络隔离,并且不会执行故障切换操作。
默认情况下,网络隔离地址是主机的默认网关
即使网络已分区,也会提供此保护。(网络被逻辑成两个部分,两个部分都可以正常的访问到网关,可以正常访问到vcenter ,就是彼此之间不能访问,一个父亲有两个孩子,两个孩子老死不相往来了,还要跟父亲往来)
在 vSphere HA 群集发生管理网络故障时,该群集中的部分主机可能无法通过管理网络与其他主机进行通信。一个群集中可能会出现多个分区。
如果您确保网络基础设施足够冗余,并且在任何时候至少有一个网络路径可用,那么主机网络隔离就不太可能发生。
冗余心跳网络的重要性
在vSphere HA簇中,心跳具有以下特征:
它们被发送到主主机和从主机之间。
它们用于确定主主机或从主机是否失败。
它们通过一个心跳网络发送。
冗余的心跳网络确保可靠的故障检测并最小化主机隔离场景的机会。
心跳网络实现:
通过使用管理的VMkernel端口实现。
通过使用在使用vSAN时为vSAN流量标记的VMkernel端口实现。
VMware建议为vSphere HA集群建立冗余心跳网络。如果不提供冗余,则故障转移设置只有单点故障。当主主机的连接失败时,仍然可以使用第二个连接将心跳发送到其他主机。
通过网卡绑定实现心跳网络的冗余
您可以使用网卡绑定在ESXi主机上创建冗余的心跳网络。
使用附加的网络
您可以通过配置更多的心跳网络来创建冗余。
在每个ESXi主机上,使用自己的物理适配器在单独的虚拟交换机上创建第二个VMkernel端口。
冗余管理网络能够可靠地检测故障并防止隔离或分区条件的发生,因为心跳可以通过多个网络发送。
**Vsphere HA架构:**代理通信
为了配置高可用性,ESXi主机被分组到一个称为集群的对象中。
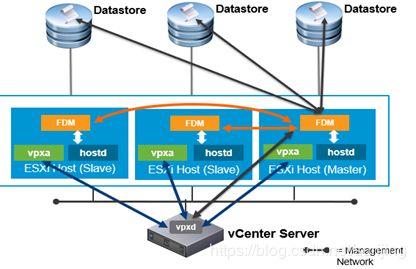
当启用vsphere HA时,故障域管理器(FDM)服务将在成员主机上启动,FDM代理启动之后,集群主机被认为处于一个故障域当中,如果主机处于维护模式,备用模式或与vcenter服务器断开连接,则他们不能参与故障域,一个主机一次只能在一个故障域
这个域由master 主机管理,所有其他主机都成为从属主机,从主机上的FDM代理都和master主机上的FDM通信
怎么选举主从:能够访问最多数量数据存储的系统被选为主系统 如果多个集群主机访问相同数量的数据存储,则选择过程通过使用由venterserver分配的主机托管对象ID(MOID)随机给主机生成一个ID 来确定主机 按首字母的大小
新的master会在15秒内完成
•启用vSphere HA。
•master遇到系统故障,
原因如下:
主机处于维护模式。
主主机处于待机模式。
重新配置vSphere HA。
•由于网络问题,从主机无法与主主机进行通信(网络分区)
选举过程中通过管理网络或者vsan网络进行通信
FDM master 负责监控:
ESXI 和虚拟机的可用性,salve主机故障后,其上的虚拟机将自动在其他主机上启动,所有被保护的虚拟机的电源状态,当故障的时候 master 会尝试重启他们
FDMmaster 负责管理:
Cluster 里的其他ESXI 负责更新和删除主机信息
被保护的虚拟机的列表,负责在开机或关机之间去维护这个列表
FDM slave 主机负责
Slave 主机会监控它本机的vm 运行状态并且将任何状态变更通知master
监控master主机的健康状态,当master死掉之后,它们会选举生成一个新的额master 主机
网络心跳:
Master 向从主机发送周期性心跳,心跳通过管理网络从master发送到每个主机,以便从主机知道master是否是活动的,如果用于主服务器通信的管理网路发生故障,则从服务器切换到另一个管理网络与主服务器通信
如果从主机在预定义的超时期间内没有响应,则主主机将从主机声明为代理不可到达。当从主机不响应时,主主机尝试确定从主机无法响应的原因。主主机必须确定从主机是否崩溃,是否因为网络故障而没有响应,或者vSphere HA代理是否处于不可达状态。
数据存储心跳:
数据存储用作检测虚拟机和主机心跳的备份通道
vSphere HA可以识别和响应各种类型的故障:
从服务器失败
主服务器失败
网络故障(主机隔离)
VMCP使vSphere HA能够检测和响应与存储相关的故障:
数据存储访问失败
APD
PDL
vSphere HA还可以确定一个ESXi主机是隔离的还是崩溃的。隔离是指ESXi主机无法看到来自集群中其他主机的流量,也无法ping默认网关。如果ESXi主机崩溃,vSphere HA必须重新启动在集群中其余主机上的失败主机上运行的虚拟机。如果ESXi主机是隔离的,因为它无法ping默认网关(或隔离地址),并且没有看到管理网络流量,则该主机执行主机隔离响应。
当从主机不响应主主机发出的网络心跳时,主vSphere HA代理将尝试确定原因。
主主机必须确定从主机是否由于网络问题(例如,配置错误的防火墙规则或组件故障)而崩溃或没有响应。故障类型决定了vSphere HA如何响应。
对于VMFS,读取数据存储上的心跳区域,以确定主机是否仍在对它进行心跳。对于NFS数据存储,vSphere HA读取主机–hb文件,该文件由访问数据存储的ESXi主机锁定。该文件保证VMkernel对数据存储进行心跳,并定期更新锁文件。主主机使用锁文件时间戳来确定从主机是遭受网络故障还是主机故障
当主主机处于维护模式或崩溃时,从主机检测到主主机不再发出心跳。
在这种情况下,必须进行选举以确定新的主主机。访问最多数据存储的主机被选为主服务器。如果所有从主机都具有相同的数据存储访问权限,则在将主机添加到vCenter服务器目录时,选择过程将使用vCenter服务器分配的按词法排序的最高MOID来选择新的主主机。
选择新主服务器后,它将从存储在数据存储中的主机列表中读取主机和虚拟机的MAC和IP地址。主机列表用于确定主服务器是否应该接受来自从服务器的连接。
新主进程在每个数据存储中读取一个文件,该文件包含所有虚拟机的状态,并确定哪些虚拟机受vSphere HA保护,可能需要重新启动。新主进程首先确定哪些虚拟机在从主机上运行。通过消除过程,它确定哪些虚拟机需要重新启动。在集群完全失败后,使用相同的进程重新启动虚拟机。
如果主机在管理上没有收到任何心跳或观察到任何选举流量,并且无法ping其默认网关,则主机被隔离。
该幻灯片演示了几种可能导致主机隔离的场景之一。如果主机失去与主心跳网络和备用心跳网络的连接,则该主机将不再从vSphere HA集群中的其他主机接收网络心跳。此外,这张幻灯片还描述了同一台主机不能再ping它的隔离地址。如果主机被隔离,主vSphere HA代理必须通过检查数据存储心跳来确定该主机是否仍然是活动的,并且仅仅是被隔离的。只有当主机被隔离或分区时,vSphere HA才会使用数据存储心跳。
通过良好的设计可以最小化主机隔离事件:
•实现冗余心跳网络。
实现冗余隔离地址。
如果确实发生了主机隔离事件,良好的设计可以使vSphere HA确定隔离的主机是否仍然是活动的。
VM网络应该在物理上独立于心跳网络。
实现数据存储,通过使用以下一种或两种方法将它们与管理网络分离:
•光纤上的光纤通道。
•物理地将您的IP存储网络与管理网络分离。
如果数据存储基于Fibre Channel,则数据存储访问不会因网络故障而中断。当使用基于IP存储(例如,NFS、iSCSI或以太网上的光纤通道)的数据存储时,必须在物理上隔离(如果无法实现物理隔离,则必须在逻辑上隔离)IP存储网络和管理网络(心跳网络)。
随着每台主机上的虚拟机和数据存储的数量不断增加,存储连接问题的成本很高,但并不常见。
连接问题是由于:
•网络或交换机故障
•阵列错误
•断电存储连接问题影响虚拟机的可用性:
•虚拟机在受影响的主机上很难管理。
•带有附加磁盘的应用程序崩溃。
VMCP不支持vSAN。
VMCP可以防止虚拟机上的存储故障。
只有包含ESXi 6的vSphere HA集群。可以使用x主机来启用VMCP。
VMCP运行在为vSphere HA启用的集群上。
VMCP检测和响应故障。
VMCP提供应用程序可用性和补救
如果启用了VMCP, vSphere HA可以检测数据存储可访问性故障,并为受影响的虚拟机提供自动恢复。VMCP提供了针对数据存储可访问性故障的保护,这些故障可能会影响在vSphere HA集群中主机上运行的虚拟机。当发生数据存储可访问性故障时,受影响的主机不能再访问特定数据存储的存储路径。您可以确定vSphere HA将为这样的故障提供的响应,范围从创建事件警报到在其他主机上重新启动虚拟机。