Pandas处理泰坦尼克号数据
写在前面:
本文中用到的数据集为titanic_train.csv,若有需要,在留言区留言即可获得。
船员数据
Survive:是否获救 Survive=1(获救) Survive=0(死亡)
Pclass:船舱等级 3等舱:便宜 1等舱:贵
SibSp:兄弟姐妹个数
Parch:parent and child 携带 老人和孩子个数
Fare:船票价格
Embarked:上船地点 S C Q

一、读取数据
#导包
import numpy as np
import pandas as pd
#读取文件(泰坦尼克号船员获救数据)
titanic_survival = pd.read_csv('titanic_train.csv')
#读取前5行数据(默认)
#head()无参数,默认返回数据的前5行
titanic_survival.head()运行结果:

二、对数据进行处理
2.1 .isnull()函数:处理数据的缺失值
下面将通过对“age”列的处理来看一下缺失值的情况的。
#缺省值的处理
#取出age列的数据
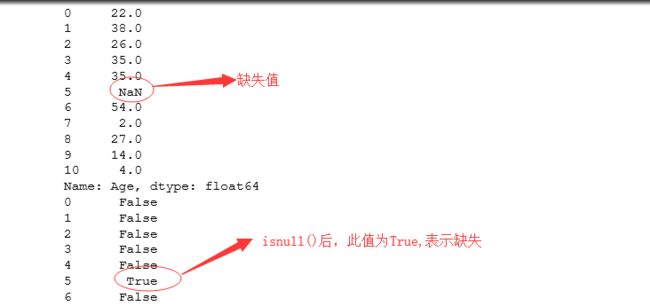
age = titanic_survival['Age']
#打印age前10行的值
print (age.loc[0:10])
print ('---------------------------')
#ismull()函数:判断当前列是否有缺失值
#返回结果是bool类型的值:若返回true,则说明该项缺失;若返回false,则该项有值
age_is_null = pd.isnull(age)
print (age_is_null)
#将age_is_null作为索引值
#true保留下来(即缺失值),false过滤
age_null_true = age[age_is_null]
print (age_null_true)
#缺失值个数
age_null_count = len(age_null_true)
print ("age列缺失值的个数:",age_null_count)运行结果:
![]()
2.2 缺失值处理的探讨
2.2.1 不处理缺失值的后果
为什么要对缺失值进行处理?
需求:求船员的平均年龄
#假设不对缺失值处理
#求船员年龄的平均数
#sum():求出船员的年龄总和
#len():求出船员的个数
mean_age = sum(titanic_survival['Age'])/len(titanic_survival['Age'])
print ("船员的平均年龄是:",mean_age)运行结果:
![]()
从结果看出,由于样本数据中的“Age”列存在缺失值,而缺失值会被标记为NaN,因此参与运算后平均年龄的返回结果为NaN
2.2.2 如何对缺失值未处理造成的后果进行调整呢?
由2.2.1可以看出,缺失值的存在对数据的处理带来的后果,那么接下来,我们将用不同的方法对其进行解决。
A. 直接过滤缺失值
#处理缺失值(法一:将缺失值过滤)
#age_is_null = True:缺失值
#age_is_null = False:不是缺失值
good_ages = titanic_survival['Age'][age_is_null == False]
correct_mean_age1 = sum(good_ages)/len(good_ages)
print ("correct_mean_age1:",correct_mean_ages)运行结果:
![]()
B. mean()函数
虽然上面的方法可以求出船员的平均年龄,但是过于麻烦,可以直接使用mean()函数来直接求出结果。
#处理缺失值(法一:mean()函数)
correct_mean_age2 = titanic_survival['Age'].mean()
print ("correct_mean_age2:",correct_mean_age2)运行结果:
![]()
注意:直接滤去缺失值并不是一个很好的方法,我们可以拿年龄的平均数、中位数、重数进行一个填充。
3. 每类船舱对应的平均票价
需求:船舱等级一共有[1,2,3]三种,分别对应不同的票价,分别求每级船舱的平均票价。
法一:for循环
思路:通过for循环对每一类船舱进去抽取,抽取出属于同一类船舱等级的船客的全部信息,再从每一个分类船客中抽出“Fare”(船票价格)这列数据,对其用,mean()函数求平均,再返回给每一类的类别。
#船舱等级一共有3种,求每一种船舱等级对应的平均票价
#法一:for循环
#列表:存放船舱等级
passenger_classes = [1,2,3]
#字典:存放船舱等级key以及对应的平均票价value
fares_by_class = {}
#对每一类船舱进行循环
for this_class in passenger_classes:
#当this_class = 1时,返回的是所有一等舱的船客的信息
#当this_class = 2、3时,同理
pclass_rows = titanic_survival[titanic_survival["Pclass"] == this_class]
#再从每次取得的信息中,返回“Fare”(票价)这列的数据
pclass_fares = pclass_rows["Fare"]
#.mean():求平均票价
fare_for_class = pclass_fares.mean()
#将平均票价value赋值给对应的船舱等级key
fares_by_class[this_class] = fare_for_class
print("每类船舱对应的平均票价 = ", fares_by_class)运行结果:
![]()
法二:.pivot_table()函数
虽然法一可以求出每类船舱对应的票价,但是过于麻烦,可以直接使用pivot_table()函数来直接求出结果。
.pivot_table()有三个参数
index:统计的信息是以谁为基准的,index就 等于谁
values:统计index与谁之间的关系,values就等于谁
aggfunc::index与values之间的什么关系,aggfunc等于什么关系(不写的话,默认求均值)
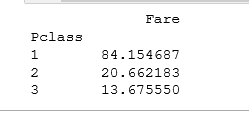
#法二:pivot_table()函数
fare_for_class2 = titanic_survival.pivot_table(index="Pclass", values="Fare", aggfunc=np.mean)
print(fare_for_class2)运行结果:
4. 求每类船舱对应的平均存活率
#求每类船舱对应的平均存活率
passenger_survical = titanic_survival.pivot_table(index="Pclass", values="Survived", aggfunc = np.mean)
print(passenger_survical)运行结果:

从结果可以看出,船舱等级与船员获救几率存在着一定的关系,等级越高,获救几率越大。
5. 求每类船舱对应的平均年龄
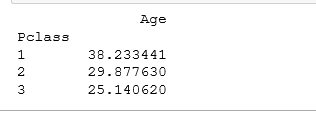
#求每类船舱对应的平均年龄
passenger_age = titanic_survival.pivot_table(index="Pclass", values="Age", aggfunc = np.mean)
print(passenger_age)运行结果:
6. 用.pivot_table()看一个量与其他两个量之间的关系
需求:不同的登船地点(C,Q,S)的总票价和总获救人数。
#不同的登船地点(C,Q,S)的总票价和总获救人数
port_stats = titanic_survival.pivot_table(index = "Embarked",values = ["Fare","Survived"],aggfunc = np.sum)
print(port_stats)运行结果:

7. dropna()函数:去掉带有缺失值的行或列
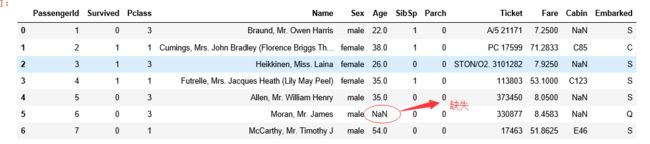
#dropna()函数:去掉具有缺失值的行或列
#调用dropna前的数据
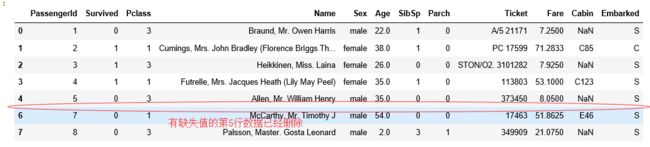
titanic_survival.head(7)
#看Age和Sex这两列是否存在缺失值
#如果存在,就把具有缺失值的这行数据去掉
new_titanic_survival = titanic_survival.dropna(axis = 0,subset = ["Age","Sex"])
#调用dropna后的数据
new_titanic_survival.head(7) 运行结果:
调用dropna前的结果
注意:此打印的结果是不带print的打印方式,因为带有print的打印一行显示不完,看起来不够清楚。
调用dropna后的结果
8. loc[a,b]函数:获取确定位置上的数据
总结loc函数
loc[a]:取第a+1行的数据(index是从0开始的)
loc[a:b]:取从第a行到第b行的数据
loc[[a,b,c]]:取第a,b,c三行的数据
loc[a,b]:取第a行第b列的数据(行号a和列名b)
数据中每一个具体的值都是由一个行号和列名唯一确定的,所以可以用行号和列名来返回这个位置上的值。
#获取确定位置上的数据
row_index_83_age = titanic_survival.loc[83,"Age"]
row_index_766_pclass = titanic_survival.loc[766,"Pclass"]
print("row_index_83_age:",row_index_83_age)
print("row_index_766_pclass:",row_index_766_pclass)运行结果:
![]()
9. sort_values()函数:进行数据的重新排序
reset_index()函数:重置排序后的index值(即行号)
用.sort_values()对数据进行排序后,虽然行的顺序因为排序条件发生了变化,但是其行号却还保持着之前的样子
为了让排序后的数据的行号变成从0开始,依次增大,所以运用.reset_index()进行重置。
#重置行号
#根据“Age”的大小逆序排列
new_titanic_survival = titanic_survival.sort_values("Age",ascending = False)
titanic_reindexed = new_titanic_survival.reset_index(drop = True)
#new_titanic_survival[0:10]
titanic_reindexed.loc[0:10]运行结果:
重置排序前数据的前10行
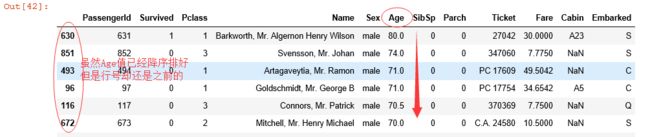
重置排序后数据的前10行
10. apply() 函数:自定义函数
我们知道pandas已经提供了很多个功能强大的函数,但是还是会有一些具体的操作没有办法直接用已经定义的函数来完成的,此时我们应该如何执行这些呢?
一方面,可以通过写代码慢慢的拼接出来。
另一方面,可以通过写apply()函数,而这个apply()函数就相当于我们可以进行一个自定义函数的操作。
在apply()中传进来的是一个函数名,而传进来的函数可以是自己定义的函数,即将自己的操作定义成一个函数的形式,然后apply一下,这时就会在这个DataFrame中执行这个操作了。
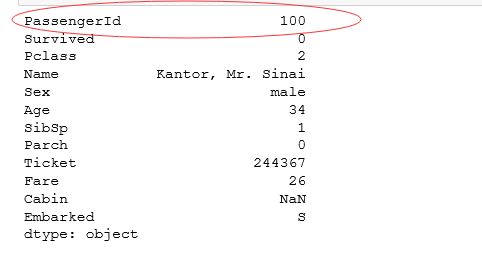
10.1 例一
需求:返回数据集合的第100行数据。
#自定义函数hundredth_row:返回第100行数据
def hundredth_row(column):
hundredth_item = column.loc[99]
return hundredth_item
#apply(自定义函数名):调用自定义函数
hundredth_row = titanic_survival.apply(hundredth_row)
print(hundredth_row)运行结果:
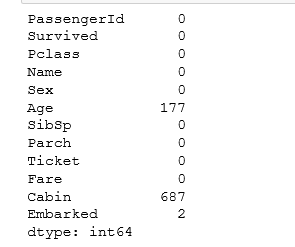
10.2 例二
需求:返回每一个属性缺失值的个数。
#返回所有属性缺失值的个数
def isnull_count(column):
#返回值是true或flase
column_null = pd.isnull(column)
#缺失值列表
null = column[column_null]
return len(null)
column_null_count = titanic_survival.apply(isnull_count)
print(column_null_count)运行结果:
10.3 例三
需求:对船舱等级【1,2,3】改写成First Class,Second Class ,Third Class
#将船舱等级进行一个转化
#1——First Class....
def which_class(row):
pclass = row["Pclass"]
if pd.isnull(pclass):
return "UnKnown"
elif pclass == 1:
return "First Class"
elif pclass == 2:
return "Second Class"
elif pclass == 3:
return "Third Class"
classes = titanic_survival.apply(which_class,axis = 1)
print(classes)运行结果:

10.4 例四
需求:将年龄离散化,在本实例数据集上的“Age”是一个连续的值,这里以18为界限,将其离散化。
def generate_age_label(row):
age = row["Age"]
if pd.isnull(age):
return "Unknow"
elif age < 18:
return "minor"
else:
return "adult"
age_labels = titanic_survival.apply(generate_age_label, axis = 1)
print(age_labels)运行结果:

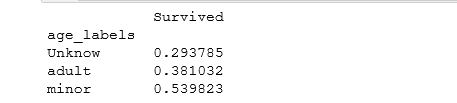
利用上边的自定义函数,使用.pivot_table()函数得到年龄阶段与获救率之间的关系。
#将上一个里边返回的关于age_labels的数据组合成数据的一列
titanic_survival["age_labels"] = age_labels
#得到年龄阶段与存活率之间的关系
age_group_survival = titanic_survival.pivot_table(index = "age_labels",values = "Survived")
print(age_group_survival)运行结果:
更多AI资源请关注公众号:大胡子的AI

欢迎各位AI爱好者加入群聊交流学习:882345565(内有大量免费资源哦!)
版权声明:本文为博主原创文章,未经博主允许不得转载。如要转载请与本人联系。