LR模型常见问题小议
// 毕竟不是什么大牛,只是总结一下自己的一些认识和想法,如果有不正确的,还请大牛们斧正。
经常说的2/8原则,LR肯定就是能解决80%问题中那20%的工具。所以LR还是值得好好研究的。发现以前对LR重视不够,总想着赶紧把其他算法也学了,才能拉小跟同事之间机器学习的gap。其实LR用得还是挺多的,而且效果还是不错的。一些高大上的算法,在公司这种大数据面前不一定跑得动,即使跑得动,效果也不一定好,而且还有可解释性和工程维护方面复杂度的问题。这倒是挺残酷的现实。
发现学完coursera的机器学习课程后,离具体实践还是有不少距离,也没找到什么好的资料可以学习(如果谁发现有的话,麻烦告诉我一声吧),耳濡目染了一些奇技淫巧,总结一下,有一些其实之前的笔记也零散提到了。
数据归一化
仔细区分的话,有两种:
- 归一化: (x-最小值)/(最大值-最小值)
- 标准化: (x-平均数)/标准差
反正就是把数据缩放到大小差不多,在1左右。这样起到的作用是加速迭代。根本原因其实是因为你偷懒,没有为每一个特征单独设置一个a。既然用了同一个a,那你也要保证数据scale也差不多。
特征离散化&组合
刚开始觉得,机器学习公司里有现成的包可以调用,然后把数据灌进去就好了,机器学习到底有啥搞头呢? 后来才搞明白,现实中,机器学习里面重要的一环其实就是搞“特征工程”,如果你对数据有足够的敏锐,能抽取出一些有效的特征,往往比算法本身的优化来得有效得多。怎么抽取特征这里就不多说,这里所说常见的特征处理方法:离散化和特征组合。
离散化
离散化就是把数值型特征离散化到几个固定的区间段。比如说成绩0-100,离散化成A、B、C、D四档,然后用4个01特征来one-hot编码,比如
A为1,0,0,0
B为0,1,0,0
C为0,0,1,0
D为0,0,0,1
那第一位就表示是否为A,第二位表示是否为B……
这里起到的作用就是减少过拟合,毕竟95和96分的两个学生能力不见得就一定有差别,但是A的学生跟D的比起来还是有明显差别的。其实就是把线性函数转换成分段阶跃函数了。
另外一种,比如把汽车时速按10公里/小时之类的分一些档,就像这样:
0-10
10-20
20-30
……
如果现在我们想学习的目标是油耗
这里以某款国内比较热销的车型做了下面的几项测试:
120km/h匀速行驶时,油耗为7.81升/100km
90km/h匀速行驶时, 油耗为5.86升/100km
60km/h匀速行驶时, 油耗为4.12升/100km
30km/h匀速行驶时 ,油耗为4.10升/100km
显然油耗不是线性的,不离散化肯定不行。仔细想想,这样离散化之后,其实可以近似拟合任意函数了。
特征组合
特征组合就比较简单,比如现在有两个特征A和B,再新增一个A and B的特征。
小结
LR的劣势就是线性模型的线性假设过强,但我们发现通过上面这些trick,其实也可以学习”非线性“的特征,大大增强了LR的能力,所以LR才能这么流行。
高纬度01特征
就是one-hot编码,上面就用了。
还有一个优点没提到,就是没有数据归一化(标准化)的问题。
高纬度的特征我们一般不会存一个<特征名,下标值>这样一个hashmap,而是直接用
哈希(特征名)%特征数
以前还以为这样做是因为在算法预测能力上会有神奇的提升,结果不是,只是出于工程方便的考虑。
好处只是少维护了一个索引,方便多了。当然,哈希冲突是有的,而且这个对算法是有害的,只不过冲突一般比较少,还hold得住。这里有个资料(http://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.HashingVectorizer.html#sklearn.feature_extraction.text.HashingVectorizer)不错,说的是处理文本,其实对LR也一样。
正负样本不均衡问题
(注意这里只讨论LR,不要乱推广到其他算法)感觉怎么这问题有点像”玄学”了,坊间通用的说法是样本太不均衡是会有问题的,正负样本比例多大合适? 一些经验主义的说法是顶多负样本是正样本的几(5以内吧)倍。
这问题的分析,显然要从loss function入手。
假设现在负样本复制多一份,从loss function的角度看来,就是负样本的cost前面乘以2,这个2其实可以当做负样本的权重。所以,谁样本多,谁占的权重其实就大一些。要看看loss function的优化目标是不是跟你的目标一致,如果正负样本对你来说一样重要,那可以不用管,但通常都不是,所以是个问题。通常情况都是比较少的样本反而比较重要的,这真是一个大问题。假设正负样本是1:1w,你关心的是正样本,直接学出来的模型可能就直接把样本全判别为负样本。但这显然不是你想要的结果。
像我这样的懒人,直觉是觉得保持1:1最好,或者说至少没坏处。那通常采用的方法就是up-sampling或者down-sampling,具体操作方法很简单,少的样本复制多份,或者多的样本只抽样一些。但我感觉前者容易过拟合,后者数据利用得又不够充分。难道咸鱼与熊掌就不可得兼?后来某大牛指点了一下,告诉我一个简单的trick:
用down-sampling,然后采样多次,训练多个模型,跟随机森林一样,求个平均即可
这里还有另外一个问题,我们知道LR学出来是一个概率值,样本不均衡,我们调一下阈值不就行了么?比如从原来的0.5调整到0.3,这样就会多判断一些正样本,唯一的问题就是样本不均衡时候的分类边界跟均衡时的边界平行么?
好吧,作为一个懒惰的“工程学派”,懒得去推到公式从理论上去证明,还是来做个直观的实验吧。
用R语言来做。我知道用R比较简单,但是R本身我不熟,还要google一番+?<函数名> 命令,勉强还是把代码撸出来了。代码逻辑很简单,自己定好一个斜率K=5,然后在边界上下生成一些随机数,高斯分布,均匀分布都可以。
LABEL_1_NUM <- 100
LABEL_0_NUM <- 100
K <- 5
x1 <-runif(LABEL_1_NUM, 0, 10)
x2 <-runif(LABEL_0_NUM , 0, 10)
D <-1
x2 <- rep(x2,D)
Y <- c( x1* K + rnorm(LABEL_1_NUM, mean=15, sd=19), x2 * K + rnorm(LABEL_0_NUM, mean=-15, sd=19) )
#Y <- c( x1* K + runif(LABEL_1_NUM, min=-15, max=50), x2 * K + runif(LABEL_0_NUM, min=-50, max=15) )
X <- c( x1, x2 )
label <- as.factor( c(rep(1,LABEL_1_NUM), rep(0,LABEL_0_NUM*D) ) )
data <- data.frame(X,Y, label)
model <- glm(label~Y+X, data=data, family='binomial', control = list(maxit = 600))
plot( data$X , data$Y , type="p", pch=19, col="red")
points( data$X[ data$label==1], data$Y[ data$label==1], type="p", pch=19, col="blue")
points( data$X[ data$label==0], data$Y[ data$label==0], type="p", pch=19, col="red")
co = coef(model)
lines(c(0,100),c(-co[1]/co[2], -(co[1]+co[3]*100)/co[2]), type="l", col='green', lwd=3)
print(co)
#截距
print(-co[1]/co[2])
#斜率
print(-co[3]/co[2])
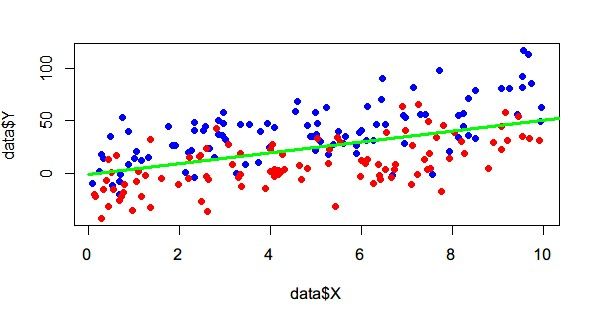
正负 100:100
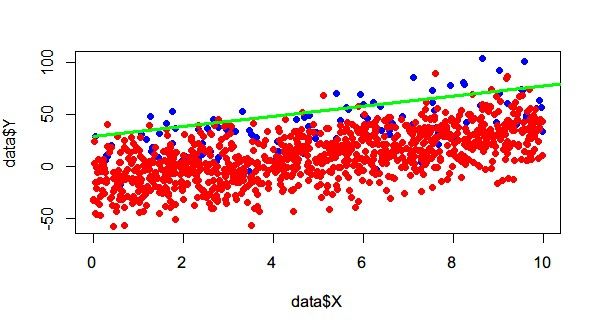
正负 100:1000
有点遗憾,采样多次取平均,斜率居然都是5左右。后来想想,负样本多的时候,其实正样本都不用怎么看了,而负样本形成的带状物,边缘斜率肯定也是接近5。
改变方法,负样本生成的时候斜率改成-K,然后标准差调大一些。这样分类边界应该是Y=0。
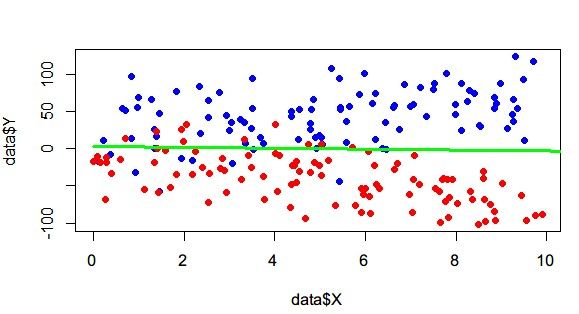
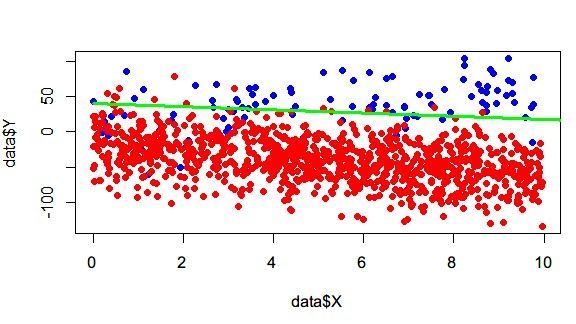
注意,一定要多抽样几次。能发现,负样本多的话,边界还是会向下偏一些的(至少比1:1的时候。 斜率 (-∞, -1] vs [-1,1] )。这个问题能举一个反例证明就够了。注意这里为了方便展示,取的只有2维,高维的就更不好说了。不过这里还发现,边界向下其实偏离得不会特别大,LR还是有一些容错能力的,但比赛的话,能提升0.5%都已经很不错了。