Hive---分组聚合函数,窗口函数
一、分组聚合函数(group by)
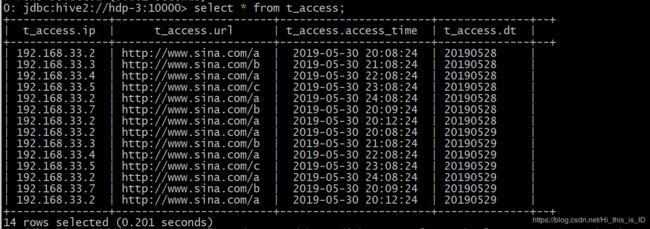
用到的表是t_access:
有group by 那个group by 会在select、update、alter等等之前运行
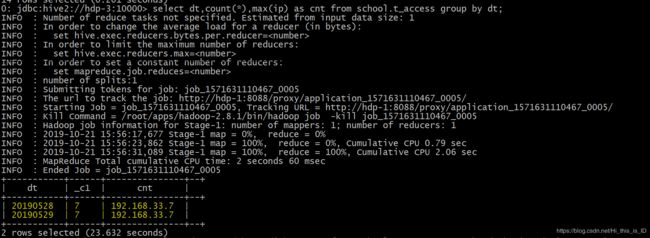
1、把数据中的日期整合并显示数目,寻找最大的ip
select dt,count(*),max(ip) as cnt from school.t_access group by dt;结果图:
2、查询在数据中日期dt>20190528的,并且整合日期,寻找最大的ip
select dt,count(*),max(ip) as cnt from school.t_access group by dt having dt>'20190528';结果图:

3、查询在数据中日期dt>20190528的,查询出网址为'http://www.sina.com/b'的并且整合日期,寻找最大的ip,
select dt,count(*),max(ip) as cnt
from school.t_access
where url='http://www.sina.com/b'
group by dt having dt>'20190528';结果图:

一旦有group by子句,那么,在select子句中就不能有 (分组字段,聚合函数) 以外的字段
## 为什么where必须写在group by的前面,为什么group by后面的条件只能用having
因为,where是用于在真正执行查询逻辑之前过滤数据用的
having是对group by聚合之后的结果进行再过滤;
上述语句的执行逻辑:
- where过滤不满足条件的数据
- 用聚合函数和group by进行数据运算聚合,得到聚合结果
- 用having条件过滤掉聚合结果中不满足条件的数据
二、窗口函数
(窗口函数与分组聚合函数类似,但是每一行数据都生成一个结果
使用方法:配合聚合窗口函数一起使用,例如SUM / AVG / COUNT / MAX / MIN等等
关键字:over partition by )
在hdp-3的hive下新建一张表sales:
create table sales(year int,country string,product string,profit string)
> row format delimited
> fields terminated by ',';在hdp-3下新建一个文件sales,并加入以下数据:
vi sales2000,Finland,Computer,1500
2001,USA,Computer,1200
2001,Finland,Phone,10
2000,India,Calculator,75
2001,USA,TV,150
2000,India,Computer,1200
2000,USA,Calculator,5
2000,USA,Computer,1500
2000,Finland,phone,100
2001,USA,Calculator,50
2001,USA,Computer,1500
2000,India,Calculator,75
2001,USA,TV,100hdp-3的hive中把sales中数据文件导入到hive表中:
load data local inpath '/root/sales' into table default.sales;数据导入后如图所示:

我现在想求每个国家profit的总和,常用的做法是使用聚合函数sum
select country,sum(profit) as countory_profit
from sales
group by country
order by country;结果如下:

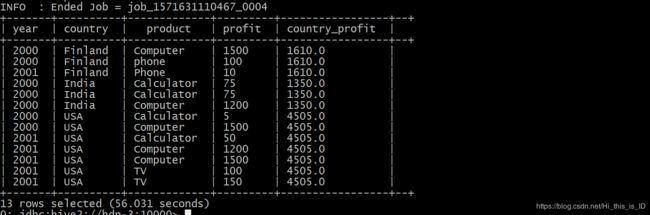
我现在想求sum的同时,展示出其他字段的信息比如year,product等,
select year,country,product,profit,
sum(profit) OVER (partition by country) as country_profit
from sales
order by country,year,product,profit;结果图如下: