Bootloader详解
Bootloader基本认识
每一种不同的CPU系统结构都有不同的BootLoader,除了依赖于CPU的体系结构外,Bootloader还依赖于具体的嵌入式板级设备的配置,比如板卡的硬件地址分配,外设芯片的类型等。也就是说,对于两块不同的开发板而言,即使他们是基于同一种CPU而构建的,但如果他们的硬件资源或配置不一样的话,想要在一块开发板上运行的Bootloader程序也能在另一块开发板上运行的话,Bootloader仍然需要修改。
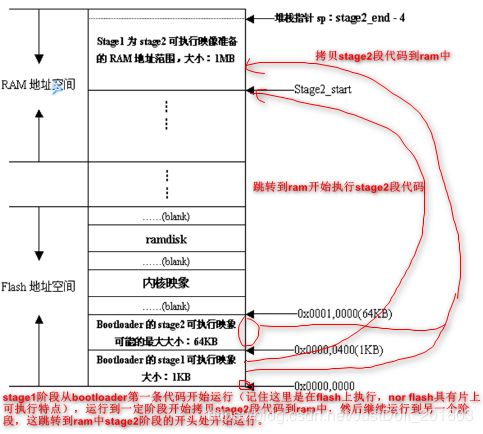
BootLoader的启动过程分为单阶段(Single-stage)和多阶段(Multi-Stage)两种,通常多阶段的BootLoader具有更复杂的功能,更好的可移植性。从固态存储设备上的Bootloader大多采用两阶段,即启动过程分为Stage1和Stage2:
stage1:完成初始化硬件,为stage2准备内存空间,并将stage2复制到内存中,设置stage2运行需要的堆栈,然后跳转到stage2运行。注意:在该阶段执行bootloader代码时,C语言的运行环境还没建立起来(主要是堆栈还没设置好,所以该阶段的代码都是采用汇编语言编写)
stage2:初始化本阶段要使用到的硬件设备,将内核映像(镜像)和根文件系统映像(镜像)从flash上读到RAM中,然后调用内核。注意:stage1阶段已经为该阶段建立好了C语言的运行环境,所以该阶段大多采用C语言编写,当然也可以用汇编!
知识扩展
一、堆栈空间分配区别:
1、栈(习惯上也称为堆栈):由操作系统自动分配释放,存放函数的参数值,局部变量的值等;
2、堆: 由程序员动态分配和释放,若程序员不释放,程序结束时可能由OS回收,分配方式倒是类似于链表。
二、堆栈缓存方式区别:
1、栈使用的是一级缓存,他们通常都是被调用时处于存储空间中,调用完毕立即释放;
2、堆是存放在二级缓存中,生命周期由虚拟机的垃圾回收算法来决定(并不是一旦成为孤儿对象就能被回收)。所以调用这些对象的速度要相对来得低一些。
三、堆栈数据结构区别:
堆(数据结构):堆可以被看成是一棵树,如:堆排序;
栈(数据结构):一种先进后出的数据结构。
“栈“的深入理解
1.什么是栈?
栈(也称为堆栈,注意和堆的区别)是一种特殊的线性表,是一种只允许在表的一端进行插入或删除操作的线性表。表中允许进行插入、删除操作的一端称为栈顶。表的另一端称为栈底。栈顶的当前位置是动态的,对栈顶当前位置的标记称为栈顶指针。当栈中没有数据元素时,称之为空栈。栈的插入操作通常称为进栈或入栈,栈的删除操作通常称为退栈或出栈。
简易理解:
客栈,即临时寄存的地方,计算机中的堆栈主要用来保存临时数据,局部变量和中断/调用子程序程序的返回地址。程序中栈主要是用来存储函数中的局部变量以及保存寄存器参数的,如果你用了操作系统,栈中还可能存储当前进线程的上下文。设置栈大小的一个原则是,保证栈不会下溢出到数据空间或程序空间.CPU在运行程序时,会自动的使用堆栈,所以堆栈指针SP就必须要在调用C程序前设定。
CPU的内存RAM空间存放规律一般是分段的,从地址向高地址,依次为:程序段(.text),BSS段,然后上面还可能会有堆空间,然后最上面才是堆栈段,这样安排堆栈,是因为堆栈的特点决定的,所以堆栈的指针SP初始化一般在堆栈段的高地址,也就是内存的高地址,然后让堆栈指针向下增长(其实就是递减)。这样做的好处就是堆栈空间远离了其他段,不会跟其他段重叠,造成修改其他段数据,而引起不可预料的后果,还有设置堆栈大小的原则,要保证栈不会下溢出到数据空间或者程序空间。所谓堆栈溢出,是指堆栈指针SP向下增长到其他段空间,如果栈指针向下增长到其他段空间,称为堆栈溢出。堆栈溢出会修改其他空间的值,严重情况下可造成死机.
2.堆栈指针的设置
开始将堆栈指针设置在内部RAM,是因为不是每个板上都有外部RAM,而且外部RAM的大小也不相同,而且如果是SDRAM,还需要初始化,在内部RAM开始运行的一般是一个小的引导程序,基本上不怎么使用堆栈,因此将堆栈设置在内部RAM,但这也就要去改引导程序不能随意使用大量局部变量。
片内4K的SRAM,SDRAM大小64M,从0x30000000到0x33FFFFFF,当程序在片内SRAM运行的时候,sp的值设置为4096,当程序在SDRAM内运行的时候sp设置为0x34000000,当然当程序在内部SRAM运行,若已经初始化SDRAM,此时也可以将堆栈指针设置为0x34000000,更加防止了堆栈溢出。
3. 栈的整体作用
1) 保存现场;
2) 传递参数:汇编代码调用 C 函数时,需传递参数;
3) 保存临时变量:包括函数的非静态局部变量以及编译器自动生成的其他临时变量;
1) 保存现场
现场,意思就相当于案发现场,总有一些现场的情况,要记录下来的,否则被别人破坏掉之后,你就无法恢复现场了。而此处说的现场,就是指 CPU 运行的时候,用到了一些寄存器,比如 r0,r1 等等,对于这些寄存器的值,如果你不保存而直接跳转到子函数中去执行,那么很可能就被其破坏了,因为其函数执行也要用到这些寄存器。因此,在函数调用之前,应该将这些寄存器等现场,暂时保持起来(入栈 push),等调用函数执行完毕返回后(出栈 pop),再恢复现场。这样CPU就可以正确的继续执行了。保存寄存器的值,一般用的是 push 指令,将对应的某些寄存器的值,一个个放到栈中,把对应的值压入到栈里面,即所谓的压栈。然后待被调用的子函数执行完毕的时候,再调用 pop,把栈中的一个个的值,赋值给对应的那些你刚开始压栈时用到的寄存器,把对应的值从栈中弹出去,即所谓的出栈。其中保存的寄存器中,也包括 lr 的值(因为用 bl 指令进行跳转的话,那么之前的 PC 的值是存在 lr 中的),然后在子程序执行完毕的时候,再把栈中的 lr 的值 pop 出来,赋值给 PC,这样就实现了子函数的正确的返回
2) 传递参数
C 语言进行函数调用的时候,常常会传递给被调用的函数一些参数,对于这些 C 语言级别的参数,被编译器翻译成汇编语言的时候,就要找个地方存放一下,并且让被调用的函数能够访问,否则就没发实现传递参数了。对于找个地方放一下,分两种情况。一种情况是,本身传递的参数不多于 4 个,就可以通过寄存器 r0~r3 传送参数。因为在前面的保存现场的动作中,已经保存好了对应的寄存器的值,那么此时,这些寄存器就是空闲的,可以供我们使用的了,那就可以放参数。另一种情况是,参数多于 4 个时,寄存器不够用,就得用栈了。
3) 临时变量保存在栈中
包括函数的非静态局部变量以及编译器自动生成的其他临时变量。