微软UNILM 2.0:优雅的统一预训练模型
本文首发于微信公众号:NewBeeNLP,欢迎关注获取更多干货资源。
刷arxiv看到了之前比较喜欢的一个工作UNILM的续集,这不得提高优先级先来品品(虽然还有一大堆TODO)。关于UNILM 1.0 在之前的文章中已经有介绍了,见站在BERT肩膀上的NLP新秀们(PART II),这种做到NLU和NLG简洁统一的框架真的是非常赞!
目前NLP预训练模型主要采取两大类预训练目标来进行语言模型训练:Auto-encoding(如BERT等)和Auto-regressive(如GPT/XLNEet等)。如下图,简单来说Auto-encoding就是类似BERT那样的通过[MASK]标记来获取前向和后向的信息;而Auto-regressive呢就是自左向右或者自右向左地对文本进行语言建模,它的好处是对生成任务有天然的优势,缺点呢就是只能得到单向的信息不能同时利用上下文的信息。

而本文使用的Partially Auto-Regressive则可以认为是对Auto-regressive的扩展,将token级别扩展到了span级别,并且不限制方向性。
模型预训练
UNILM 2.0的模型框架没有什么好说的,骨架网络就是Transformer,跟主流的都差不多,论文的亮点在于预训练目标。在一个统一的BERT式的网络基础上,设计了两种预训练目标,自编码和部分自回归,分别对应双向语言模型和seq2seq语言模型, 然后进行联合训练:
L = L A E + L P A R \mathcal{L}=\mathcal{L}_{\mathrm{AE}}+\mathcal{L}_{\mathrm{PAR}} L=LAE+LPAR
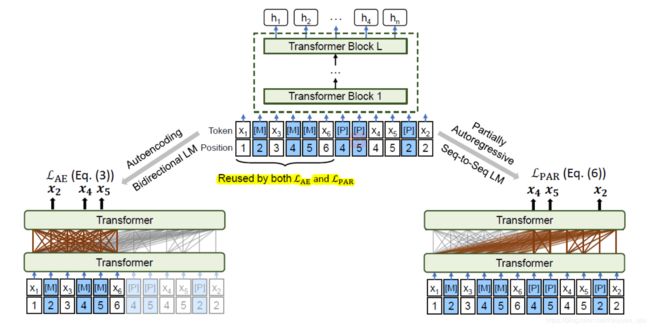
自编码
上图中左半部分,自编码(Auto Encoding,AE)就像BERT一样,利用已知的上下文信息来单独地计算被MASK掉的token的概率。
L A E = − ∑ x ∈ D log ∏ m ∈ M p ( x m ∣ x \ M ) \mathcal{L}_{\mathrm{AE}}=-\sum_{x \in \mathcal{D}} \log \prod_{m \in M} p\left(x_{m} | x_{\backslash M}\right) LAE=−x∈D∑logm∈M∏p(xm∣x\M)
其中, M = { m 1 , ⋯ , m ∣ M ∣ } M=\left\{m_{1}, \cdots, m_{|M|}\right\} M={m1,⋯,m∣M∣}为被mask词集合, x \ M x_{\backslash M} x\M表示出去mask词集的其他词, x m x_{m} xm则表示被mask词, D D D表示训练语料集合。
部分自回归
上图中右半部分,部分自回归(Partially AutoRegressive,PAR )在每一步因式分解的时候可以选择预测单个token或多个tokens(为连续的span),当所有步均选择预测一个token时,则会变为自回归模式。
p ( x M ∣ x \ M ) = ∏ i = 1 ∣ M ∣ p ( x M i ∣ x \ M ≥ i ) = ∏ i = 1 ∣ M ∣ ∏ m ∈ M i p ( x m ∣ x \ M ≥ i ) \begin{aligned} p\left(x_{M} | x_{\backslash M}\right) &=\prod_{i=1}^{|M|} p\left(x_{M_{i}} | x_{\backslash M_{\geq i}}\right) \\ &=\prod_{i=1}^{|M|} \prod_{m \in M_{i}} p\left(x_{m} | x_{\backslash M \geq i)}\right. \end{aligned} p(xM∣x\M)=i=1∏∣M∣p(xMi∣x\M≥i)=i=1∏∣M∣m∈Mi∏p(xm∣x\M≥i)
其中, x M i = { x m } m ∈ M i x_{M_{i}}=\left\{x_{m}\right\}_{m \in M_{i}} xMi={xm}m∈Mi表示第 i i i步需要预测的token, M ≥ i = ⋃ j ≥ i M j M_{\geq i}=\bigcup_{j \geq i} M_{j} M≥i=⋃j≥iMj表示还没有预测出的词(每一步都不一样)。所以部分自回归预训练损失可以表示为:
L P A R = − ∑ x ∈ D E M log p ( x M ∣ x \ M ) \mathcal{L}_{\mathrm{PAR}}=-\sum_{x \in \mathcal{D}} \mathbb{E}_{M} \log p\left(x_{M} | x_{\backslash M}\right) LPAR=−x∈D∑EMlogp(xM∣x\M)
其中, E M \mathbb{E}_{M} EM是分解的期望,但是在预训练中只随机采用一种分解。
关于Mask的策略
对于输入,随机采样15%作为mask集合,这其中40%的概率mask掉长度为2到6的n-gram连续span,60%的概率mask单独一个token。

伪掩码语言模型
正如前面提到的,如果要用部分自回归的话,每一步预测时可用的tokens是不一样的,因此如果直接使原始BERT中的MLM,必须为每个分解步骤构建一个新的Cloze实例,这将导致部分自回归的预训练不可行。
为此提出了一种Pseudo-Masked LM(PMLM) 的训练方式,简单来说就是对masked token额外添加一个带对应位置编码信息的标记[P],用于在部分自回归预训练时预测的placeholder。
举个栗子,对于第一幅图中的最后一个例子,即4,5——>2,下图为PMLM进行部分自回归预测的流程。
- Step 1:通过计算 p ( x 4 , x 5 ∣ x \ { 2 , 4 , 5 } ) p\left(x_{4}, x_{5} | x_{\backslash\{2,4,5\}}\right) p(x4,x5∣x\{2,4,5})来同时 预测 x 4 x_{4} x4和 x 5 x_{5} x5,为了避免信息泄露,这一步attend的元素为 x 1 , x 3 , x 6 x_{1}, x_{3}, x_{6} x1,x3,x6以及 [ P ] 4 [P]_{4} [P]4和 [ P ] 5 [P]_{5} [P]5。
- Step 2:通过计算 p ( x 2 ∣ x \ { 2 } ) p\left(x_{2} | x_{\backslash\{2\}}\right) p(x2∣x\{2})来预测 x 2 x_{2} x2,这一步可以获取上一步得出的结果,即这一步attend的元素为 x 1 , x 3 , x 4 , x 5 , x 6 x_{1}, x_{3}, x_{4}, x_{5}, x_{6} x1,x3,x4,x5,x6以及 [ P ] 2 [P]_{2} [P]2
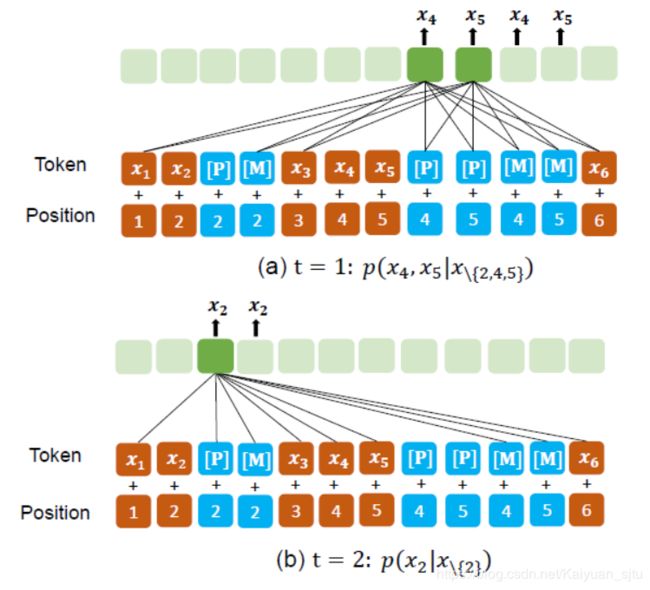
具体实现的话,基本思想还是跟UNILM 1.0一样的,即Self-Attention Masks,来控制计算某一个token时其他元素可以attend的权限。以上图为例,其Self-Attention Masks矩阵为,

可以看到,[M]和已知的 ( x 1 , x 3 , x 6 ) \left(x_{1}, x_{3}, x_{6}\right) (x1,x3,x6)可以被全局attend。[M] 对AE 部分来说,因为是bidirectional,所以互相都允许attend;对PAR部分,可以提供”完整“的context(比如对P4/P5来说,就可以看到M2),这样避免了之前autoregressive不能看future context,导致一些位置被完全masked。
模型输入
- 在预训练阶段,模型输入形式为:
[SOS] S1 [EOS] S2 [EOS],其中S1和S2是连续的文本,[SOS] 和[EOS] 是表示文本起始以及结束的特殊标记,输入token的表示是word embedding, absolute position embedding以及 segment embedding的加和。 - 在微调阶段,不同任务的输入形式不同:
- 对于NLU任务,输入为
“[SOS] TEXT [EOS],然后用[SOS]作为text的表示用于下游任务; - 对于NLG任务,输入为
[SOS] SRC [EOS] TGT [EOS],一旦解码出[EOS],则停止解码,解码阶段使用beam search;
- 对于NLU任务,输入为
实验部分
论文中也展示了很多具体实验,QA、GLUE、Abstractive Summarization、Question Generation,就不展开,粗瞄一眼效果都很不错的样子,感兴趣的自行阅读~
还是消融性实验比较有趣,作者在多个任务上对UNILN2.0的组件进行拆解,各模型表现如下表。

随便唠唠
UNILM1.0刚出来的时候同期还有一个MASS,也是微软的,MASS的做法是显式地设计一个Encoder和一个Decoder来做seq2seq生成。而UNILM1.0是使用了一个更为优雅的设计,即通过attention mask矩阵来达到在一个单独的BERT中实现seq2seq任务,不显式区分encoder和decoder。
- UNILM2.0是对1.0中的seq2seq预训练任务进行了优化,引入了部分自回归训练目标,可能是受了XLNet的启发,PMLM中的特殊标记[P]的作用有点类似于XLNet中的双流自注意力机制。
来自论文作者董神:有点儿 三流注意力(真实、mask、pseudo mask)的意思,motivation就是最大限度重用计算的hidden states,来实现 unified language model pretraining 里的 bidirectional AE (bert) 和 seq2seq PAR (bart)
- 另外在预训练过程中,输入文本的上下文表示会被AE和PAR重复利用,避免了无关计算。