MySQL索引原理总结
文章目录
- 一、索引介绍
- (一)释义
- (二)数据结构演示
- 二叉树
- 红黑树
- (三)数据库索引为什么要用 B+ 树而不用红黑树呢?
- 二、B树
- (一)B-Tree
- (二)B+树
- (三)分析
- (四)B+树和B树区分
- (五)千万数据查询实例分析
- 三、MyISAM和InnoDB
- (一)MyISAM
- (二)InnoDB
- (三)为什么InnoDB表必须有主键,并且推荐使用整型的自增主键?
- (四)为什么非主键索引结构叶子节点存储的是主键值?(一致性和节省存储空间)
- 四、扩展和原理分析
- (一)联合索引和索引最左前缀原理
- (二)MySQL索引方式中Hash索引和B树的区别,为什么推荐B树
一、索引介绍
(一)释义
索引是帮助MySQL高效获取数据的排好序的数据结构
索引数据结构:
二叉树
红黑树
Hash表
B-Tree
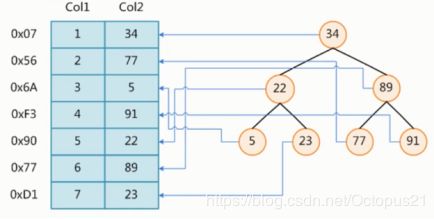
(二)数据结构演示
以图中的Col1列建立索引,分别使用索引各个数据结构进行构建,测试效果
使用工具;查询表中列值为6的数据
https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
二叉树
如果以二叉树构建索引结构的话,那么select * from table where col1=6需要查找6次.尤其对于这种原先数据有序的条件下,二叉树的右子树会不断扩大,查找的次数也是线性增长的
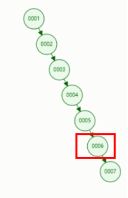
红黑树
1:根节点为黑色
2:每个叶子节点都是黑色的节点,叶子节点不存储数据
3:任何相邻的节点都不能同时为黑色,也就是说红色节点是被黑色结点隔开的
4:每个结点,从该结点到达其可到达叶子节点所有路径,都包含相同数量的黑色结点(较长的路径由于红黑相间,而由于是不大于二倍所以黑色的结点数量是相同的)
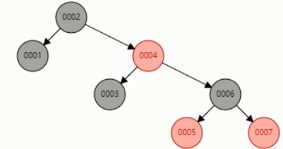
如果通过红黑树构建索引的话,查询数据6需要查询3次.
(三)数据库索引为什么要用 B+ 树而不用红黑树呢?
AVL 树和红黑树这些二叉树结构的数据结构可以达到最高的查询效率这是毋庸置疑的.
既然如此,那么数据库索引为什么不用 AVL 树或者红黑树呢?
这就牵扯到一个问题了,不考虑每种数据结构的前提条件而选择数据结构都是在耍流氓.
AVL 树和红黑树基本都是存储在内存中才会使用的数据结构,那磁盘中会有什么不同呢?
这就要牵扯到磁盘的存储原理了
操作系统读写磁盘的基本单位是扇区,而文件系统的基本单位是簇(Cluster).
也就是说,磁盘读写有一个最少内容的限制,即使我们只需要这个簇上的一个字节的内容,我们也要含着泪把一整个簇上的内容读完.
那么,现在问题就来了
一个父节点只有 2 个子节点,并不能填满一个簇上的所有内容啊?那多余的内容岂不是要浪费了?我们怎么才能把浪费的这部分内容利用起来呢?哈哈,答案就是 B+ 树.
由于 B+ 树分支比二叉树更多,所以相同数量的内容,B+ 树的深度更浅,深度代表什么?代表磁盘 io 次数啊!数据库设计的时候 B+ 树有多少个分支都是按照磁盘一个簇上最多能放多少节点设计的啊!
所以,涉及到磁盘上查询的数据结构,一般都用 B+ 树啦.
二、B树
(一)B-Tree
1:叶子节点具有相同的深度,叶子节点的指针为空
2:所有索引元素不重复
3:节点中的数据索引从左到右递增排列
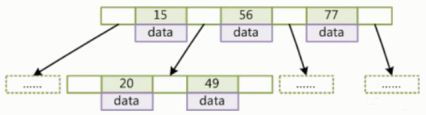
(二)B+树
1:非叶子节点不存储data,只存储索引(冗余),可以放更多的索引
2:叶子节点包含所有索引字段
3:叶子节点用指针连接,提高区间访问的性能

(三)分析
之所以选择B树而非红黑树是因为通过B树可以控制树的高度,减少磁盘IO次数,MySQL的数据和索引都是存储在磁盘上的.此外每个节点可以增加存储的索引元素个数,充分利用每个簇(Cluster)能够得到有效使用
(四)B+树和B树区分
1:B+树叶子节点增加了相邻指针
2:B+树非叶子节点只存储了key,没有存储data数据
3:B+树非叶子节点存储的是冗余元素,这样做能够让非叶子节点存储更多的key索引
(五)千万数据查询实例分析
索引是存储在磁盘的,当进行索引查询的时候才会加载到内存中
每个节点MySQL默认为16KB
SHOW GLOBAL STATUS LIKE 'Innodb_page_size'
例如:采用一个bigint为索引键 ,占用8B
一个索引需要一个key和一个指向下一节点的指针(大约6B),那么单位索引大约14B
那么一个节点大约存储索引:
16KB/14B=1170索引元素
叶子节点存储了key和data,这里估计共占用1KB,那么叶子节点每个可以存储16个索引元素
如果一个B+树共有三层,高度为3,那么一个满的B+树可以存储大约
1170X1170X16=21902400个元素
(俩层非叶子节点,一层叶子节点)
只需要高度为3的B+树就可以保存2千万的索引数据
所以说如果对一张千万级别的表构建了索引,查询时使用到该列索引,那么查询在毫秒级别就可以完成,如果没有构建索引可能需要几十甚至几百秒
三、MyISAM和InnoDB
(一)MyISAM
MyIsam引擎和Innodb引擎都是针对表级别的
CREATE TABLE `user` (
`id` int(11) NOT NULL DEFAULT '0',
`name` varchar(50) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8;
数据库中存储的表都是存储在磁盘中,如果安装在本地Windows下,则存储的数据在mysql/data目录下
在Myisam下,数据库的每个数据表都有*.frm、.YMI和.YMD三个文件,其中*.frm存储数据表的表结构,.MYI存储数据表的索引,.MYD存数数据表的记录数据
(二)InnoDB
CREATE TABLE `category_` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(30) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `keyId` (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8;
在Innodb下,每个数据库下的每个数据表有俩个文件*.frm和*.ibd:其中*.frm存储数据表的表结构,而所有数据库的所有表数据索引、数据记录都全部存储在*.ibd文件中
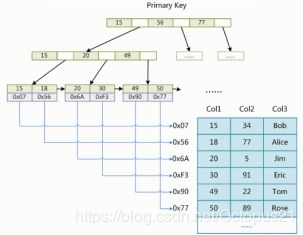
InnoDB索引实现(聚集)
1:表数据文件本身就是按照B+Tree组织的一个索引结构文件,与Myisam不同的是它的叶子节点存储的不是数据文件地址,而是具体的数据,将索引和数据放合并了
聚集索引
2:聚集索引-叶子节点包含了完整的数据记录
聚集索引:索引和数据聚合在一起存储
非聚集索引:索引和数据聚合不在一起存储

(三)为什么InnoDB表必须有主键,并且推荐使用整型的自增主键?
MySQL构建的时候就是按照B+树构建的,它要求必须有一个主键,如果你设置了主键则使用你所设置的主键索引,如果你创建的表没有主键MySQL会去从列中选择一个合适的列作为主键,如果没有合适唯一主键列的则系统会新增一个隐藏的列作为主键rowid ,由系统来维护这个主键列.
推荐使用整型的自增主键是因为
1:使用整型的主键列占用的存储空间更小
2:使用整型的主键在进行查询比较时更高效,如果使用字符串那么在比较的时候还需要转换ASCII来进行逐个比较,效率相对较低
3:推荐自增是因为在B树在新增元素时需要保证平衡的机制,如果新增的元素是递增的,那么只需要右侧简单的扩展,只有到达某个临界点时才需要大幅度的调整自旋保证平衡,但是如果所选择的主键是非自增的,那么每次新增索引元素的时候都可能去进行大幅度的调整以此去保证B树的平衡,那么经常的调整自旋对性能是有很大的消耗的,所以建议使用自增的主键
(四)为什么非主键索引结构叶子节点存储的是主键值?(一致性和节省存储空间)
如果非主键索引的叶子节点也存完整的数据时,比如你更新一条数据之前需要将主键索引和非主键索引的那个数据更改完才能进行更新操作(相当于是一个分布式事物了,性能大大降低). 我们只需要通过存储的主键进行定位即可.
主键索引
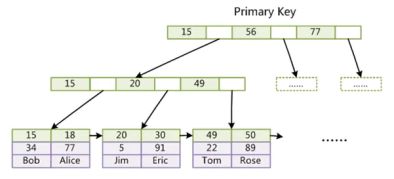
非主键索引

四、扩展和原理分析
(一)联合索引和索引最左前缀原理
对于联合索引,mysql从左往右的使用索引中的字段,一个查询可以使用索引中的一部分。
例如key(a,b,c),可以支持a、(a,b)、(a,b,c)这些组合的进行查询。
创建联合索引时,应该仔细考虑列的顺序。对索引中的所有列执行搜索或仅对前几列执行搜索时,联合索引非常有用。索引使用范围:当单一列索引可以出现在where条件中的任何位置,而联合索引需要按照一定顺序来写

(二)MySQL索引方式中Hash索引和B树的区别,为什么推荐B树
hash index是基于哈希表实现的,只有精确匹配索引所有列的查询才会生效.对于每一行数据,存储引擎都会对所有的索引列计算一个hash code,并将所有的hash code存储在索引中,同时在哈希表中保存指向每个数据行的指针.
在MySQL中,只有Memory引擎显示支持哈希索引,也是默认索引类型.
Hash在范围查找的时候应用很差,只适合精确查找
B-树由于叶子节点只存储了数据地址,如果需范围查找需要多次的从头结点查找对范围查询不友好
B+树由于在叶子节点上设置了相邻节点指针,那么只要确定了范围,从一个起点开始,通过相邻指针就能够很快的查询到所有元素,而且不像B-树需要多次磁盘IO又回到前面的索引位置重新定位,效率非常好