python NLP——处理原始文本
一 从网络和硬盘访问文本
电子书
from urllib import request
url = "http://www.gutenberg.org/cache/epub/5517/pg5517.txt"
reponse=request.urlopen(url)
raw=reponse.read().decode('utf8')
print(raw[:75])


如果你使用的Internet代理Python不能正确检测出来,你可能需要在使用urlopen之前用下面的方法手动指定代理:
>>> proxies = {'http': 'http://www.someproxy.com:3128'}
>>> request.ProxyHandler(proxies)
变量raw包含一个有1,176,893个字符的字符串。(我们使用type(raw)可以看到它是一个字符串。)这是这本书原始的内容,包括很多我们不感兴趣的细节,如空格、换行符和空行。请注意,文件中行尾的\r和\n,这是Python 用来显示特殊的回车和换行字符的方式(这个文件一定是在Windows 机器上创建的)。对于语言处理,我们要将字符串分解为词和标点符号,正如我们在1.中所看到的。这一步被称为分词,它产生我们所熟悉的结构,一个词汇和标点符号的列表。
分词将原来的字符串转换为列表
from nltk import word_tokenize
from urllib import request
url = "http://www.gutenberg.org/cache/epub/5517/pg5517.txt"
reponse=request.urlopen(url)
raw=reponse.read().decode('utf-8')
tokens=word_tokenize(raw) //分词
print(type(tokens))
print(tokens[:10])
![]()
在首位出现了\ufeff 字节顺位标记
首行出现的”\ufeff“叫BOM(“ByteOrder Mark”)用来声明该文件的编码信息.
”utf-8“ 是以字节为编码单元,它的字节顺序在所有系统中都是一样的,没有字节序问题,因此它不需要BOM,所以当用"utf-8"编码方式读取带有BOM的文件时,它会把BOM当做是文件内容来处理, 也就会发生类似上边的错误.
“uft-8-sig"中sig全拼为 signature 也就是"带有签名的utf-8”, 因此"utf-8-sig"读取带有BOM的"utf-8文件时"会把BOM单独处理,与文本内容隔离开,也是我们期望的结果.
原文链接:https://blog.csdn.net/wozaizhe56/article/details/82048645
于是将utf-8 改成utf-8-sig
raw=reponse.read().decode('utf-8-sig')
![]()
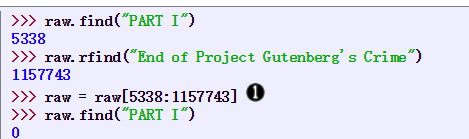
find() rfind() 得到对应索引值
rfind返回字符串最后一次出现的位置(从右向左查询)
处理HTML
使用BeautifulSoup得到HTML文本(去除标签)
from nltk import word_tokenize
from urllib import request
from bs4 import BeautifulSoup
url = "https://yiyibooks.cn/yiyi/nltk_python/ch03.html"
reponse=request.urlopen(url)
html=reponse.read().decode('utf-8')
raw=BeautifulSoup(html,features='html.parser').get_text() #得到去除标签后的文本
tokens=word_tokenize(raw)
print(tokens)
features=‘html.parser’ 使用html解析器来解析文档
各种解析器 https://www.cnblogs.com/wzzkaifa/p/7111431.html
Beautiful Soup 中文文档 https://www.crummy.com/software/BeautifulSoup/bs3/documentation.zh.html
处理搜索引擎的结果
处理RSS
import feedparser
llog = feedparser.parse("http://languagelog.ldc.upenn.edu/nll/?feed=atom")
print('Title:',llog['feed']['title']) #信息源标题
print('帖子数量:',len(llog.entries))
post=llog.entries[2] #获得帖子
print(post.title)
content=post.content[0].value
读取本地文件
f = open('document.doc','rU')
raw = f.read()
for line in f:
print(line.strip())
'r’意味着以只读方式打开文件(默认),'U’表示“通用”,它让我们忽略不同的换行约定。
strip()方法删除输入行结尾的换行符
Python strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列。
注意:该方法只能删除开头或是结尾的字符,不能删除中间部分的字符。
从PDF、MS Word 及其他二进制格式中提取文本
捕获用户输入
s = input("Enter some text:")
NLP的流程

二 字符串
字符串的基本操作
如果一个字符串中包含一个单引号,我们必须在单引号前加反斜杠让Python 知道这是字符串中的单引号
circus = 'Monty Python\'s Flying Circus'
字符串跨好几行 用\或者()
couplet = "Shall I compare thee to a Summer's day?"\
"Thou are more lovely and more temperate:"
couplet = ("Rough winds do shake the darling buds of May,"
"And Summer's lease hath all too short a date:")
两行之间换行 三重引号

输出字符串

+拼接中间不会有空格
print( , )时中间会产生空格
print( ,end="") 添加end= 使输出时不会换行
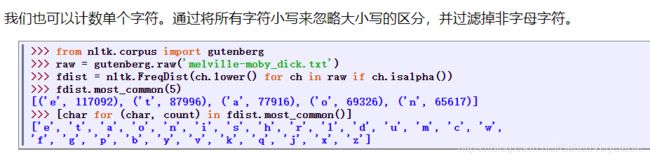

列表和字符串的差异
字符串无法修改
列表可以更改值

三 使用Unicode进行文字处理
文件中的文本都是有特定编码的,所以我们需要一些机制来将文本翻译成Unicode——翻译成Unicode叫做解码。相对的,要将Unicode 写入一个文件或终端,我们首先需要将Unicode 转化为合适的编码——这种将Unicode 转化为其它编码的过程叫做编码
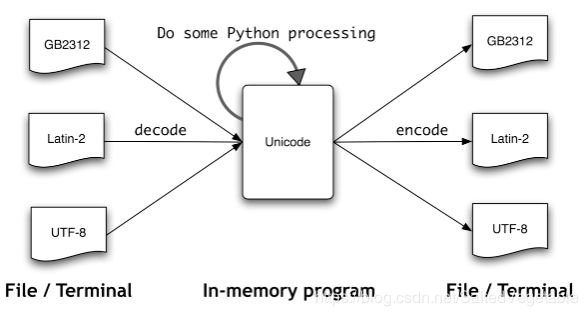
在python中使用本地编码
为了做到这一点,你需要在你的文件的第一行或第二行中包含字符串:’# -- coding: --’。请注意必须是像’latin-1’, 'big5’或’utf-8’这样的字符串
待看: https://blog.csdn.net/qq_33692803/article/details/81321340
https://blog.csdn.net/can0227/article/details/83240705
四 使用正则表达式检测词组搭配
import re
使用基本的元字符
import re
import nltk
wordlist = [w for w in nltk.corpus.words.words('en') if w.islower()] #词汇列表
print([w for w in wordlist if re.search('ed$',w)]) #查找以ed结尾的词汇
print([w for w in wordlist if re.search('^..j..t..$',w)]) #8个字母组成,第三个字母j,第六个字母t
使用函数re.search(p, s)检查字符串s中是否有模式p
$用来匹配单词末尾 ^匹配单词开始
.通配符匹配任何单个字符

![]()
去除^ j不一定为第三个字母
![]()
?表示前面的字符可选
sum(1 for w in text if re.search('^e-?mail$', w)) #计数一个文本中这个词(任一拼写形式)出现的总次数
«^e-?mail$» 将匹配email和e-mail
范围和闭包
^ [ghi][mno][jlk][def]$ #9键中输入4653时获取的单词
[ghi] g,h,i 中任取一

+/* Kleene闭包
+号代表前面的字符必须至少出现一次(1次或多次)
*号代表字符可以不出现,也可以出现一次或者多次(0次、或1次、或多次)。
会出现一些字母不出现的词汇,例如,me, min和mmmmm
^出现在方括号内第一个字符位置时,表示匹配除括号中的内容
例如,«[^aeiouAEIOU]»匹配除元音字母之外的所有字母,包括非字母字符。
(ed|ing)$ ed/ing结尾的单词

反斜杠\表示其后面的字母不再有特殊的含义而是按照字面的表示匹配词中特定的字符。因此,虽然.很特别,但是.只匹配一个句号。
大括号表达式,如{3,5}, 表示前面的项目重复指定次数。
管道字符|表示从其左边的内容和右边的内容中选择一个。
圆括号表示一个操作符的范围,它们可以与管道(或叫析取)符号一起使用,如«w(i|e|ai|oo)t»,匹配wit, wet, wait和woot。
ed|ing$ 与 (ed|ing)$ 区别

![]()
ed或ing结尾的单词

单词中包含ed或者以ing结尾的单词
因为序列与$ 的优先级>|的优先级
相当于(ed)|(ing$)

字符串加一个前缀r,来表明它是一个原始字符串
r/R:非转义的原始字符串
字母前加r表示raw string,也叫原始字符串常量。
主要使用在:
(1)正则表达式
用于处理正则表达式时,规避反斜杠的转义;
(2)系统路径
如路径path = r’e:\text’,使用r就防止了\t的转义;
https://blog.csdn.net/winfred_hua/article/details/86079353
五 正则表达式的有益作用
提取单词片段
re.findall() 找出指定匹配

一些文本中的两个或两个以上的元音序列,并确定它们的相对频率
import re
import nltk
wsj=sorted(set(nltk.corpus.treebank.words()))
fd=nltk.FreqDist(vs for word in wsj
for vs in re.findall(r'[aeiou]{2,}',word))
print(fd.most_common(10))
![]()
在W3C 日期时间格式中,日期像这样表示:2009-12-31。Replace the ? in the following Python code with a regular expression, in order to convert the string ‘2009-12-31’ to a list of integers [2009, 12, 31]:
[int(n) for n in re.findall(?, ‘2009-12-31’)]
提取中间数字
date=[int(n) for n in re.findall(r'[0-9]+','2009-12-31')]
![]()
在单词片段上做更多事情
import re
import nltk
regexp=r'^[AEIOUaeiou]+|[AEIOUaeiou]+$|[^AEIOUaeiou]'
def compress(word):
pieces=re.findall(regexp,word)
return ''.join(pieces)
english_udhr=nltk.corpus.udhr.words('English-Latin1')
print(nltk.tokenwrap(w for w in english_udhr[:75]))
print(nltk.tokenwrap(compress(w) for w in english_udhr[:75]))

匹配词首元音序列,词尾元音序列和所有的辅音;其它的被忽略
nltk.tokenwarp() 与word_tokenize()有什么区别?


这段代码依次处理每个词w,对每一个词找出匹配正则表达式«[ptksvr][aeiou]»的所有子字符串。对于词kasuari,它找到ka, su和ri。因此,cv_word_pairs将包含(‘ka’, ‘kasuari’), (‘su’, ‘kasuari’)和(‘ri’, ‘kasuari’)。更进一步使用nltk.Index()转换成有用的索引。
nltk.Index() ???
查找词干
如果我们要使用括号来指定析取的范围,但不想选择要输出的字符串,必须添加?:
![]()

搜索已分词文本
import nltk
from nltk.corpus import gutenberg,nps_chat
moby=nltk.Text(gutenberg.words('melville-moby_dick.txt'))
print(moby.findall(r'(<.*>)' ))


例如," < a> < man>"找出文本中所有a man的实例。尖括号用于标记词符的边界,尖括号之间的所有空白都被忽略(这只对NLTK中的findall()方法处理文本有效)。在下面的例子中,我们使用<.*>,它将匹配所有单个词符,将它括在括号里,于是只匹配词(例如monied)而不匹配短语(例如,a monied man)会生成。
第二个例子找出以词bro结尾的三个词组成的短语。
最后一个例子找出以字母l开始的三个或更多词组成的序列。
nltk.re_show(p, s) 标注字符串s中所有匹配模式p的地方
nltk.app.nemo() 提供一个探索正则表达式的图形界面
建立搜索模式
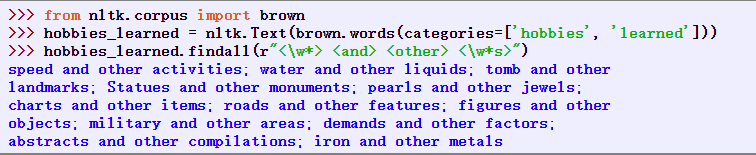
在大型文本语料库中搜索x and other ys形式的表达式能让我们发现上位词
六 规范化文本
词干提取器
import nltk
raw = """DENNIS: Listen, strange women lying in ponds distributing swords is no basis for a system of government. Supreme executive power derives from a mandate from the masses, not from some farcical aquatic ceremony."""
tokens=nltk.word_tokenize(raw)
porter=nltk.PorterStemmer()
lancaster=nltk.LancasterStemmer()
print([porter.stem(t) for t in tokens]) #Porter词干提取器
print([lancaster.stem(t) for t in tokens]) #Lancaster词干提取器

词形归并
wnl=nltk.WordNetLemmatizer()
print([wnl.lemmatize(t) for t in tokens])
![]()
七 用正则表达式为文本分词
分词的简单方法
在空格符处切割文本
re.split() 匹配一个或多个空格 制表符 换行符
import re
import nltk
raw = """'When I'M a Duchess,' she said to herself, (not in a very hopeful tone
though), 'I won't have any pepper in my kitchen AT ALL. Soup does very
well without--Maybe it's always pepper that makes people hot-tempered,'"""
tokens=nltk.word_tokenize(raw)
print(re.split(r'[ \t\n]+',raw))
![]()
使用一个re库内置的缩写\s,它表示匹配所有空白字符。前面的例子中第二条语句可以改写为re.split(r’\s+’, raw)
记住在正则表达式前加字母r(表示"原始的"),它告诉Python解释器按照字面表示对待字符串,而不去处理正则表达式中包含的反斜杠字符
\w 匹配字母数字及下划线
\W 匹配非字母数字及下划线
用\W来分割所有单词字符以外的输入


NLTK的正则表达式分词器
nltk.regexp_tokenize()
>>> text = 'That U.S.A. poster-print costs $12.40...'
>>> pattern = r'''(?x) # set flag to allow verbose regexps
... ([A-Z]\.)+ # abbreviations, e.g. U.S.A.
... | \w+(-\w+)* # words with optional internal hyphens
... | \$?\d+(\.\d+)?%? # currency and percentages, e.g. $12.40, 82%
... | \.\.\. # ellipsis
... | [][.,;"'?():-_`] # these are separate tokens; includes ], [
... '''
>>> nltk.regexp_tokenize(text, pattern)
['That', 'U.S.A.', 'poster-print', 'costs', '$12.40', '...']
(?x) "verbose 标志”告诉Python去掉嵌入的空白字符和注释
使用verbose 标志时,不可以再使用’ '来匹配一个空格字符;使用\s代替。regexp_tokenize()函数有一个可选的gaps参数。设置为True时,正则表达式指定标识符间的距离,就像使用re.split()一样。
set(tokens).difference(wordlist)通过比较分词结果与一个词表,然后报告任何没有在词表出现的标识符,来评估一个分词器。你可能想先将所有标记变成小写。
八 分割
断句
nltk.sent_tokenize()
分词
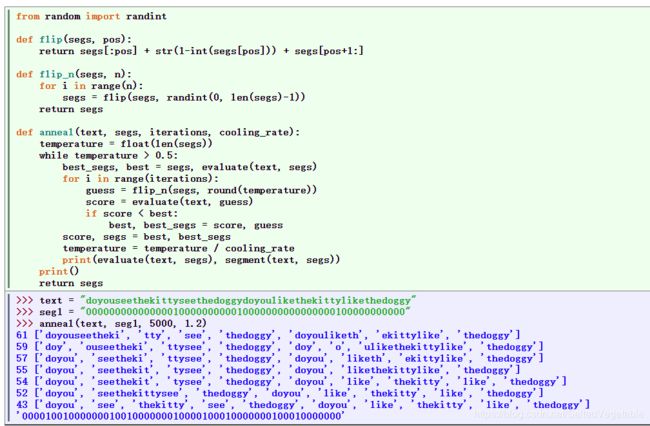
def segment(text, segs):
words = []
last = 0
for i in range(len(segs)):
if segs[i] == '1':
words.append(text[last:i+1])
last = i+1
words.append(text[last:])
return words
text = "doyouseethekittyseethedoggydoyoulikethekittylikethedoggy"
seg1 = "0000000000000001000000000010000000000000000100000000000"
seg2 = "0100100100100001001001000010100100010010000100010010000"
print(segment(text,seg1))
print(segment(text,seg2))
每个字符标注一个布尔值来指示这个字符后面是否有一个分词标志
?模拟退火算法的非确定性搜索:一开始仅搜索短语分词;随机扰动0和1,它们与“温度”成比例;每次迭代温度都会降低,扰动边界会减少。
九 格式化:从列表到字符串
从列表到字符串
’ ’ .join()

’ ‘.join(silly)的意思是:取出silly中的所有项目,将它们连接成一个大的字符串,使用’ '作为项目之间的间隔符。即join()是一个你想要用来作为胶水的字符串的一个方法。
字符串与格式
字符串格式化表达式
import nltk
fdist = nltk.FreqDist(['dog', 'cat', 'dog', 'cat', 'dog', 'snake', 'dog', 'cat'])
for word in sorted(fdist):
print('{}->{};'.format(word,fdist[word]),end='')
花括号’{}‘标记一个替换字段的出现:它作为传递给str.format()方法的对象的字符串值的占位符。我们可以将’{}'嵌入到一个字符串的内部,然后以适当的参数调用format()来让字符串替换它们。
使用数字来得到非默认的顺序:
‘from {1} to {0}’.format(‘A’, ‘B’)
对齐
冒号’:‘跟随一个整数来添加空白以获得指定宽带的输出。所以{:6}表示我们想让字符串对齐到宽度6。数字默认表示右对齐,单我们可以在宽度指示符前面加上’<‘对齐选项来让数字左对齐

字符串默认左对齐,可以通过’>‘对齐选项右对齐

{:.4f}表示浮点数的小数点后面应该显示4个数字

包含一个’%'在你的格式化字符串中,那么你想表示这个值为百分数;不需要乘以100

将结果写入文件
import nltk
output_file=open('output.txt','w')
words=set(nltk.corpus.genesis.words('english-kjv.txt'))
for word in sorted(words):
print(word,file=output_file)
文本换行
textwrap
练习
1.指定步长
s[6:11:2] 间隔为2(间隔1个字符)
2.nltk.re_show()

会用括号括出匹配正则式的符号
left (str) – The left delimiter (printed before the matched substring)
指定左括号 括出指定符号的左括号
3.写正则表达式匹配下面字符串类:
- 一个单独的限定符(假设只有a, an和the为限定符)。
- 整数加法和乘法的算术表达式,如2*3+8。
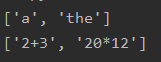
wordlist = ['a','the','213','a+b','2+3','adsfasdfasf','2=3','2+3+','20*12']
p1=r'^(a|an|the)$'
p2=r'^[0-9]+([+|*][0-9]+)+$'
print([w for w in wordlist if re.search(p1,w)])
print([w for w in wordlist if re.search(p2,w)])
注意开始符结束符和括号的使用,注意匹配顺序
[0-9]也可以写成\d
4.写一个工具函数以URL为参数,返回删除所有的HTML标记的URL 的内容。使用from urllib import request和request.urlopen(‘http://nltk.org/’).read().decode(‘utf8’)来访问URL的内容。
import re
import nltk
from urllib import request
def func (url):
raw=request.urlopen(url).read().decode('utf8')
print(re.findall(r'<.*>(.*)<.*>{1,}',raw))
func('http://nltk.org/')
5…将一些文字保存到文件corpus.txt。定义一个函数load(f)以要读取的文件名为唯一参数,返回包含文件中文本的字符串。
a.使用nltk.regexp_tokenize()创建一个分词器分割这个文本中的各种标点符号。使用一个多行的正则表达式,行内要有注释,使用verbose标志(?x)。
import nltk
def load(file):
f=open(file)
return f.read()
content=load('corpur.txt')
p=r'''(?x)
\w*(\.|\,|\?|\:|\;)
'''
nltk.regexp_tokenize(content,p)