【算法应用】KMeans算法在视频聚类中的应用
摘要
本文结合作者在视频推荐上的使用经验,讨论KMeans算法在视频聚类中的应用。包括的内容有,聚类问题描述、KMeans算法原理、聚类结果举例、Spark KMeans算法性能瓶颈。聚类先要完成特征提取,作者用视频标签和Word2vec两种方式实现过特征提取,这部分将另起一篇文章分享。
聚类问题描述
聚类问题是将N个物品,划分为K个类别,并让这种划分整体上“误差”最小(下文均已视频聚类为例)。所以,这里的关键是“误差”如何定义?如何量化?
首先,应该以某种方式提取出视频的特征(基于内容属性或基于购买历史等),将每个视频表示为一个数值向量。然后,两个视频之间就可以跟数值向量一样,去定义距离、相似度等。
对聚类误差一种常见的度量方式是,1、对每个类别的所属视频进行平均,定义为这个类的中心,2、单个视频的聚类误差,是这个视频距它所在类别的中心的距离,3、所以视频的这种误差求和,即为聚类的整体误差。聚类问题的目标,是将整体误差最小化或者降低到可以接受的程度。
KMeans算法原理
(格式问题没解决,下面贴个图片)

KMeans算法步骤如下:
0、提取视频特征,将在另一篇文章中介绍
1、随机初始化,即从到中随机选出K个点,作为K个类别的中心点。
2、基于现有中心点更新分类,更新方式是一个点距离哪个类的中心点最近,就将该点分到这个类中。如式(1)
3、基于现有分类更新类的中心点,更新方式是求每个类中各个点的平均值。
4、依次重复第2和第3步,直至整体误差L在减小至设定范围内。
聚类结果举例
视频聚类的结果,得到了本公司编辑同学的极高评价(要知道,这里只用到了用户观影历史,没用到任何视频内容属性,Word2vec+KMeans还是挺强大的吧)。因为篇幅有限,只举几个例子。
1、古典武侠型
(冷面飞鹰, 夺命金剑, 六刺客, 江湖三女侠, 忠烈图, 名剑风流, 金毛狮王, 风雨双流星, 妖魔奇兵, 追击 港版, 追击, 丹心令, 冷血十三鹰, 四大门派, 卖命小子, 睡拳怪招, 双侠, 佛都有火, 叉手, 决杀令, 龙虎少爷, 夺魂铃, 江湖汉子, 凤飞飞, 游侠情, 边城三侠, 刀不留人, 红粉动江湖, 醉猴女, 大地飞鹰, 鬼怒川)
2、色情型
(梦情人 国语, 五个寂寞的心, 再见七日情, 雪儿, 猪标一族, 极度迷情, 一千零一夜(梦中人) 国语, 1/2次同床, 伟哥的故事, 偷情小丈夫, 最后胜利, 地下情, 花仔多情)
3、主旋律
(上饶集中营, 岸边激浪, 吕梁英雄, 鹿鸣翠谷, 英雄小八路, 曙光, 湖上的斗争, 无头箭, 南海的早晨, 箭杆河边, 磐石湾, 回民支队, 草原风暴, 黎明的河边, 金玉姬, 新儿女英雄传, 英雄司机, 友谊, 飞刀华, 渔岛之子, 带兵的人, 民兵的儿子, 金铃传, 伤疤的故事, 宋景诗, 燎原, 羌笛颂, 赵一曼, 小螺号, 人民的巨掌, 两个巡逻兵, 保卫胜利果实)
4、系列片
(陆小凤传奇之铁鞋传奇, 陆小凤传奇之大金鹏王, 陆小凤传奇之银钩赌坊, 陆小凤传奇之血衣之谜, 陆小凤传奇之绣花大盗, 陆小凤传奇之凤舞九天, 陆小凤传奇之决战前后)
5、僵尸片
(僵尸至尊, 清鬼清妖, 僵尸翻生 国语, 鬼咬鬼[粤语版], 僵尸先生5驱魔警察, 僵尸叔叔, 鬼打鬼, 甩皮鬼[粤语版], 驱魔警察, 音乐僵尸[粤语版], 鬼打鬼之黄金道士[粤语版], 驱魔道长[粤语版], 新僵尸先生[粤语版], 人吓鬼[粤语版], 人吓人[粤语版])
6、等等片
Spark KMeans算法性能瓶颈
从以上讲述的算法步骤可以看出,KMeans运行逻辑很简单,且可以支持分布式的并行计算。Spark对KMeans已经有很好的实现,参见Spark KMeans。
1、视频个数不是问题
因为Spark KMeans是分布式实现,会将视频数据切块分布到多个服务器的各个节点之上。
2、聚类的个数和视频特征的维度是瓶颈所在
因为更新任一个视频所属的类别的时候,都需要计算该视频跟所有聚类中心的距离,而服务器的单个节点上只有一部分视频的数据,因此最好的方式是将所有聚类中心广播到各个服务器节点上。Spark也确实是这么干的,见下图。
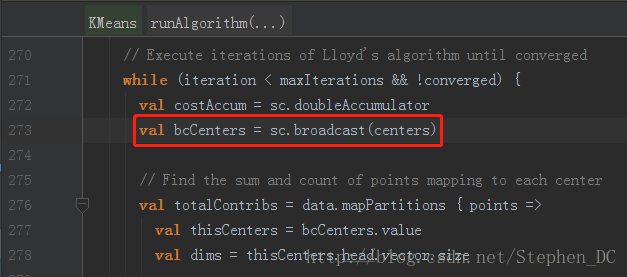
广播到每个节点上的数据量大小=聚类的个数 × 视频特征的维度。
每个服务器的节点内存是有限的,当这个数据量太大的时候,程序就会报错。这就是Spark KMeans的瓶颈所在。
通常情况下,聚类的个数不会是大问题,视频特征的维度不能太大。这里也体现出了降维的重要性。
作者将10000多个电影聚600-1000类,最开始的视频特征是取自视频标签,当特征在3000到4000维左右的时候都还OK,当维度太大的时候就会出错。后来作者改用Word2vec从用户观影历史中提取视频特征,将视频维度降为128,Spark KMeans再没出现过任何性能问题。
参考文献
[1] Spark KMeans官方API
[2] Spark KMeans源码