Stata:回归结果中不报告行业虚拟变量的系数
作者:连玉君 (知乎 | 简书 | 码云)
- 连享会推文集锦
- Stata连享会 精品专题 || 精彩推文

连享会计量方法专题……
1. 问题
在实证分析中,我们经常需要在模型中加入行业虚拟变量、年度虚拟变量等,以便控制不可观测的行业个体效应或年度个体效应。然而,在正式报告结果时,我们无需报告这些虚拟变量的系数,否则结果表格会变得非常冗长。
简言之,在估计模型时,我们需要加入这些虚拟变量,而在最终呈现结果时,只在表格中进行标注,说明我们已经控制了这些虚拟变量,而受限于篇幅,没有呈现这些变量的估计系数。
2. 解决方法 1
事实上,Stata 里有多个命令可以帮我们处理这种情形。这里以 esttab 命令为例进行说明。
2.1 esttab 命令输出结果的原理
所有这些输出结果的命令,背后的基本原理都是相同的。在完成一个模型的估计后,Stata 会把相应的估计系数、标准误、R2 等统计量统一存储在内存中,称之为“返回值 (return values)”。而诸如 esttab、outreg2 等呈现估计结果的命令,无非是把内存中存储的这些统计量以一种比较标准的格式呈现在屏幕上,或输出到 word 或 excel 文档中。
例如,使用 regress 命令完成 OLS 估计后,进而输入 ereturn list 即可在屏幕上呈现出内存中存储的统计量:
. sysuse "nlsw88.dta", clear
(NLSW, 1988 extract)
. reg wage ttl_exp married
Source | SS df MS Number of obs = 2,246
-------------+---------------------------------- F(2, 2243) = 85.79
Model | 5284.82149 2 2642.41074 Prob > F = 0.0000
Residual | 69083.1459 2,243 30.7994409 R-squared = 0.0711
-------------+---------------------------------- Adj R-squared = 0.0702
Total | 74367.9674 2,245 33.1260434 Root MSE = 5.5497
------------------------------------------------------------------------------
wage | Coef. Std. Err. t P>|t| [95% Conf. Interval]
-------------+----------------------------------------------------------------
ttl_exp | 0.330 0.025 12.95 0.000 0.280 0.379
married | -0.291 0.245 -1.19 0.235 -0.771 0.189
_cons | 3.823 0.383 9.99 0.000 3.072 4.574
------------------------------------------------------------------------------
. ereturn list //内存中的返回值
scalars:
e(N) = 2246
e(df_m) = 2
e(df_r) = 2243
e(F) = 85.79411399585418
e(r2) = .0710631427762836
e(rmse) = 5.549724397561928
e(mss) = 5284.821485260705
e(rss) = 69083.14591378947
e(r2_a) = .0702348441965032
e(ll) = -7034.513553793961
e(ll_0) = -7117.294949670642
e(rank) = 3
macros: ... ...
matrices:
e(b) : 1 x 3
e(V) : 3 x 3
functions: ... ...
在上面的例子中,内存中的返回值包括四种类型,分别是:单值(scalars)、暂元(macros)、矩阵(matrices),以及函数(functions)。这些看似凌乱的返回值,都可以采用 esttab 等命令,以一种非常规整的方式重新呈现在屏幕上,或输出到 word 文档中。例如,当我们执行如下命令后,屏幕上会呈现如下结果:
. esttab, nogap scalar(N df_m F r2)
----------------------------
(1)
wage
----------------------------
ttl_exp 0.330***
(12.95)
married -0.291
(-1.19)
_cons 3.823***
(9.99)
----------------------------
N 2246
df_m 2
F 85.79
r2 0.0711
----------------------------
t statistics in parentheses
* p<0.05, ** p<0.01, *** p<0.001
下面这幅图形非常直观的呈现了内存中的返回值的统计量名称与 esttab
命令的 scalar() 选项中引用的统计量的名称之间的关系:

至此,大家应该可以非常明确的看出,在 esttab 命令的 scalar() 选项中只能填写当前内存中对应的返回值的名称。
2.2 在内存中新增统计量
因此,要想在输出结果中增加一些内存中不存在的统计量,我们只需要预先采用手动的方式把这些统计量加入内存,随后再调出它并呈现在屏幕上即可。
例如,我们可以采用 estadd 命令向内存中添加两个统计量:一个是文字类型的返回值——Industry,采用暂元 (local) 来存储;另外一个是数值类型的返回值 ——Mean_Wage,采用单值 (scalar) 来存储:
. sysuse "nlsw88.dta", clear
. reg wage ttl_exp married
*-在内存中加入第一个返回值
. estadd local Industry "Yes"
*-在内存中加入第二个返回值
. qui sum wage
. estadd scalar Mean_Wage = r(mean)
. ereturn list //呈现内存中的返回值
此时,我们可以看到,上述两个新加的统计量,都已经保存在了内存中(图中红框所示):

接下来我们就可以采用 esttab 命令,把上述两个新增的统计量呈现在屏幕上,或输出到word文档中:

3. Stata实例
基于上面对关键概念的介绍,大家很容易读懂下面这个例子。这也是在实证分析中,我们最常用的出结果的方法。
sysuse "nlsw88.dta", clear
*-分组回归
global xx "ttl_exp married south hours tenure age i.industry"
reg wage $xx if race==1
estadd local Industry "Yes" //向内存中添加新的统计量, help estadd
estadd local Occupation "No"
est store m1
reg wage $xx if race==2
estadd local Industry "Yes"
estadd local Occupation "No"
est store m2
reg wage $xx i.occupation if race==1
estadd local Industry "Yes"
estadd local Occupation "Yes"
est store m3
reg wage $xx i.occupation if race==2
estadd local Industry "Yes"
estadd local Occupation "Yes"
est store m4
*-结果呈现
local s "using Table03.rtf" // 输出到word文档
local m "m1 m2 m3 m4" // 模型名称
local mt "White Black White Black" //模型标题
esttab `m', mtitle(`mt') b(%6.3f) nogap compress ///
star(* 0.1 ** 0.05 *** 0.01) ///
drop(*.industry *.occupation) ///
ar2 scalar(N Industry Occupation)
输出效果:
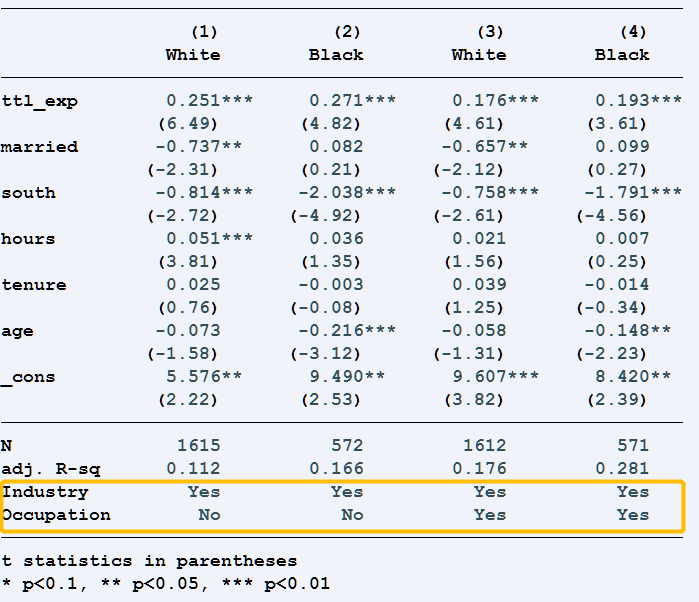
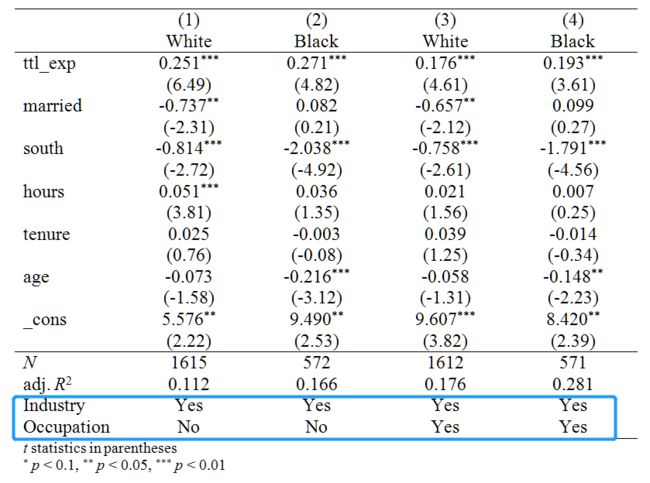
连享会计量方法专题……
4. (更为简洁的)解决方法2: 使用 esttab 命令的 indicate() 选项
上面介绍的方法具有通用性,在任何情况下,我们需要再结果呈现中加入一些新的统计量,都可以采用上述方法。然而,对于上面的例子而言,我们可以采用更为简洁的处理方法,这使得我们可以少写很多行命令。
esttab 命令中有一个隐藏的选项 indicate(),在其帮助文件中是查不到的,但却能很好的解决我们这个例子中的需求。esttab命令中增加了如下选项:
indicate("行业效应 =*.industry" "职业效应 =*.occupation" )
其中,“"行业效应 =*.industry"’”的含义是,等号左侧是我们在屏幕上需要呈现的文字信息,而等号右侧则是虚拟变量的名称。下面的截图非常明确的标示了这些语法的关系。
clear all
sysuse "nlsw88.dta", clear
*-分组回归
global xx "ttl_exp married south hours tenure age i.industry"
reg wage $xx if race==1
est store m1
reg wage $xx if race==2
est store m2
reg wage $xx i.occupation if race==1
est store m3
reg wage $xx i.occupation if race==2
est store m4
*-输出结果
local s "using Table03.rtf" // 输出到word文档
local m "m1 m2 m3 m4" // 模型名称
local mt "White Black White Black" //模型标题
esttab `m' `s', mtitle(`mt') b(%6.3f) nogap compress ///
star(* 0.1 ** 0.05 *** 0.01) ///
ar2 scalar(N) replace ///
indicate("行业效应 =*.industry" "职业效应 =*.occupation" )

关于我们
- 「Stata 连享会」 由中山大学连玉君老师团队创办,定期分享实证分析经验, 公众号:StataChina。
- 公众号推文同步发布于 CSDN 、简书 和 知乎Stata专栏。可在百度中搜索关键词 「Stata连享会」查看往期推文。
- 点击推文底部【阅读原文】可以查看推文中的链接并下载相关资料。
- 欢迎赐稿: 欢迎赐稿。录用稿件达 三篇 以上,即可 免费 获得一期 Stata 现场培训资格。
- E-mail: [email protected]
- 往期推文:计量专题 || 精品课程 || 简书推文 || 公众号合集

连享会计量方法专题……
