序列比对(十)——viterbi算法求解最可能路径
原创: hxj7
本文介绍了如何使用viterbi算法得到概率最大的路径。
前文《序列比对(九)从掷骰子说起HMM》已经通过投骰子的例子介绍了HMM的基本概念,引用如下:

那么如何通过已知的符号序列来预测未知的状态序列呢?我们将一串状态序列称为一条路径,那么如果要选择其中的一条路径作为预测结果, 也许我们该选择概率最大的,具体如下:

图片引自《生物序列分析》
其实,正如《序列比对(八)第一部分的小结》所说,后一状态依赖于前一个状态的问题很适合用动态规划算法解决。viterbi算法就是一种基于动态规划的求解最可能路径的算法。
更具体地,还以前文提到的掷骰子为例,当根据初始向量、转移矩阵、发射矩阵等参数生成一个随机的符号序列后,我们可以利用viterbi算法来求解最可能的路径。简单来讲,就是用viterbi算法来猜每次投掷用的是公平骰子还是作弊骰子。(如果对投骰子的例子不熟悉,请参考前文《序列比对(九)从掷骰子说起HMM》)
效果如下: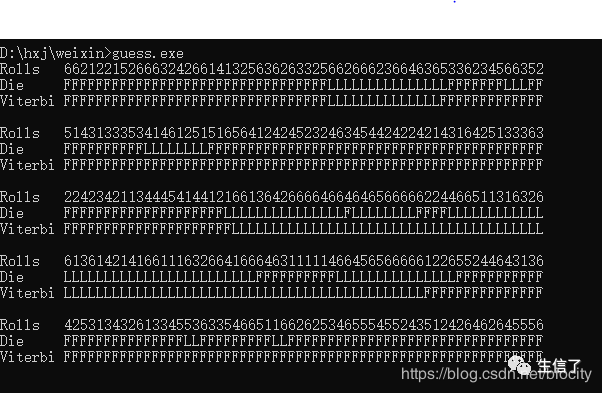
上图中Rolls代表300次投掷所产生的符号序列,Die表示投掷时实际所使用的骰子状态(F表示公平骰子,L表示作弊骰子),Viterbi表示利用viterbi算法求解的最可能路径。
具体代码如下:
(需要说明的是,实现viterbi算法要特别注意多个概率相乘会得到一个特别小的数,容易造成下溢,从而出错。所以我们将概率取log值,将公式中的概率相乘变成了log值的相加。)
#include (公众号:生信了)