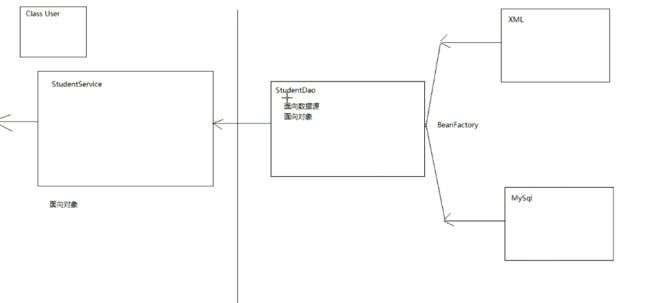
- 高级编程--XML+socket练习题
masa010
java开发语言
1.北京华北2114.8万人上海华东2,500万人广州华南1292.68万人成都华西1417万人(1)使用dom4j将信息存入xml中(2)读取信息,并打印控制台(3)添加一个city节点与子节点(4)使用socketTCP协议编写服务端与客户端,客户端输入城市ID,服务器响应相应城市信息(5)使用socketTCP协议编写服务端与客户端,客户端要求用户输入city对象,服务端接收并使用dom4j
- JavaScript 中 xml 的解析(dom4j 解析器),web前端开发规范手册
2401_84094868
程序员前端javascriptxml
创建元素:Elementschool=DocumentHelper.createElement(“school”);创建文本:school.addText(“光明小学”);指定位置添加:list.add(1,school);回写xml:和在末尾添加一样7、获取属性值attributeValue():获取属性值publicstaticvoidmain(String[]args)throwsDocum
- xml与java对象转换
iteye_10822
xmlxml
xml的解析技术包括了很多,其中dom4j,jdom,SAX等技术估计已经在大部分的人心中成为了耳熟能详的东西,但是如果是关于xml与对象直接的转换技术,那么下面几种技术是不错的选择。A.commons-digesterDigester本来仅仅是JakartaStruts中的一个工具,用于处理struts-config.xml配置文件。显然,将XML文件转换成相应的Java对象是一项很通用的功能,
- JAVA XML转JSON工具类
张志飞
xmljson
packagecom.cm.util.xmlutl;importcom.alibaba.fastjson.JSONArray;importcom.alibaba.fastjson.JSONObject;importorg.apache.log4j.Logger;importorg.dom4j.*;importjava.io.File;importjava.io.FileInputStream;im
- Java Xml 工具类
Jokes-T
javaxml
importorg.apache.commons.lang3.StringUtils;importorg.dom4j.Document;importorg.dom4j.DocumentException;importorg.dom4j.DocumentHelper;importorg.dom4j.Element;importjavax.xml.bind.JAXBContext;importjava
- 基于Spring的三方平台接口对接方法(OkHttp/RestTemplate/视图)
星月梦瑾
javajavaspringokhttprestful
本文介绍了三方平台接口对接方法,一是基于OkHttp请求工具及dom4j报文封装解析xml的方法,二是采用RestTemplate方法封装请求,三是采用建立视图和从库数据源的方式查询。一、OkHttp请求工具及dom4j报文封装解析1、依赖引入 com.squareup.okhttp3 okhttp 4.9.3 compile org.dom4j dom4j
- 将Xml转为Map集合工具类
Fairy要carry
工具xmljavapython
packagecom.wyh.wx.utils;importorg.dom4j.Document;importorg.dom4j.Element;importorg.dom4j.io.SAXReader;importjava.io.ByteArrayInputStream;importjava.io.InputStream;importjava.nio.charset.StandardCharse
- Javaweb基础-tomcat,servlet
tmy99
javaservlet开发语言
一.配置文件基础:properties配置文件:由键值对组成键和值之间的符号是等号每一行都必须顶格写,前面不能有空格之类的其他符号xml配置文件:(xml语法=HTML语法+HTML约束)xml约束-DTD/SchemaDOM4J进行XML解析:(jar包dom4j.jar)1.创建SAXReader对象SAXReadersaxReader=newSAXReader();2.解析XML获取Docu
- Dom4j的使用
A_一只小菜鸟
dom4j是一个Java的XMLAPI,是jdom的升级品,用来读写XML文件的。dom4j是一个十分优秀的javaXMLAPI,具有性能优异、功能强大和极其易使用的特点,它的性能超过sun公司官方的dom技术,同时它也是一个开放源代码的软件,可以在SourceForge上找到它。一、dom4j介绍使用方式:在pom.xml中导入dom4j对应的jardom4jdom4j1.6.1优点:dom4j
- XML 教程【一文彻底搞懂dom4j解析】
~ 小团子
JavaWebxml学习java
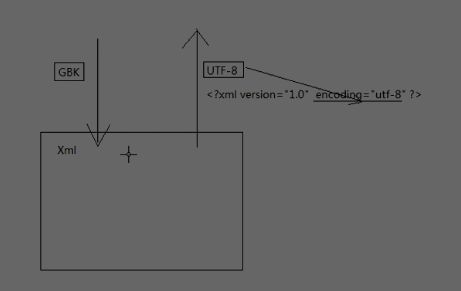
文章目录1.xml入门1.1xml新建1.1文档声明1.2元素1.3属性1.4CDATA节1.5转义字符1.6格式正确的XMLDOM4JDOM4J介绍Dom4j应用实例2.2遍历xml指定元素2.3读取指定xml元素2.4获取属性2.5dom4j增删改2.6作业1.xml入门1.1xml新建1.1文档声明XML声明放在XML文档的第一行XML声明由以下几个部分组成:version=“1.0”文档符
- xml简单操作
industry2018
xml
1.获得根目录标签下直接子标签内容:packagecom.xxx;importjava.io.FileInputStream;importjava.io.IOException;importjava.io.InputStream;importjava.util.Iterator;importorg.dom4j.Document;importorg.dom4j.DocumentException;i
- BUUCTF-Real-[PHP]XXE
真的学不了一点。。。
漏洞复现与研究网络安全
目录1、原理2、XXE漏洞产生的原因3、开始复现paylaod复现4、flag1、原理XML数据在传输过程中,攻击者强制XML解析器去访问攻击者指定的资源内容(本地/远程),外部实体声明关键字'SYSTEM'会令XML解析器读取数据,并允许它在XML文档中被替换,构造恶意的值,去执行!XML解析方式:DOM,SAX,JDOM,DOM4J,StAX……都可能会出现外部实体注入漏洞2、XXE漏洞产生的
- xml文件解析
Slow菜鸟
xmlpython前端
xml文件解析XML解析——Java中XML的四种解析方式一、DOM解析二、SAX解析三、JDOM解析四、DOM4J解析Final:比较总结转载:https://www.cnblogs.com/mountainstudy/p/17954434XML解析——Java中XML的四种解析方式XML是一种通用的数据交换格式,它的平台无关性、语言无关性、系统无关性、给数据集成与交互带来了极大的方便。XML在
- XMLdom入门案例
卓昂芭比
importjava.io.File;importjava.util.List;importorg.dom4j.Document;importorg.dom4j.DocumentException;importorg.dom4j.Element;importorg.dom4j.io.SAXReader;publicclassXml_Demo1{publicstaticvoidmain(String
- Java实现关注微信公众号和自动回复消息
weixin_43652507
公众号微信java
依赖:dom4jdom4j1.6.1com.thoughtworks.xstreamxstream1.4.11.1关注公众号和自动回复,共两个接口,一个get,一个post,两个接口的url一样。WeChatControllerimportcom.ruoyi.ruoyiincome.wx.wechat.service.IWeChatService;importlombok.extern.slf4j
- Java基础进阶02-xml
辉图
笔记java笔记
目录一、XML(可拓展标记语言)1.学习网站:2.作用3.XML标签4.XML语法5.解析XML(1)常见解析思想DOM6.常见的解析工具7.DOM4j的使用8.文档约束(1)概述(2)分类(3)DTD约束(4)引入DTD约束(5)DTD语法①定义元素②定义属性(6)schema约束①定义元素②定义属性(7)引入schema约束(8)schema和DTD约束的区别一、XML(可拓展标记语言)1.学
- Spring Boot使用dom4j处理xml数据
落华X
springbootjavaspringbootxmlpython
一、引入org.dom4jdom4j2.1.4二、使用Documentdocument=DocumentHelper.createDocument();Elementdatainfo=DocumentHelper.createElement("ela");document.setRootElement(datainfo);Elementelb=datainfo.addElement("elb");
- 基于java处理ofd格式文件
小苗爸爸
技术xmldomjavazipstream
一、ofd格式介绍国家发布过一份关于ofd编码格式的资料,本来我想传上去的发现资源重复了,你们可以找找看,没有的话留个邮箱,我看到会发给你们的ofd本质上其实是一个压缩文件,咱们把他当做一个压缩包来处理就好了,思路是先解压,对解压后的文件进行解析处理,解压后是xml文件,java有很多处理xml的类,这里我推荐dom4j,原因是相对来说功能全、速度快,处理完后再进行压缩,保存为ofd格式即可ofd
- java中ofd文件转pdf_java ofd文件解析
weixin_39609650
java中ofd文件转pdf
packageofd;importjava.io.File;importjava.math.BigDecimal;importjava.util.List;importorg.dom4j.Attribute;importorg.dom4j.Document;importorg.dom4j.DocumentException;importorg.dom4j.Element;importorg.dom
- Java:特殊文件详细解释(包含Dom4j下载和使用)
DaveVV
javajavaeclipsespringmavenintellij-ideatomcatmybatis
特殊文件:属性文件、XML文件为什么要用这些特殊文件:方便存储多个用户的用户名密码等等。特殊文件主要学什么?1.了解特点作用2.学习使用程序读取它们里面的数据3.学习使用程序把数据存储到这些文件里特殊文件:1.属性文件(.properties):如果一个txt文件里存放的都是键值对数据,每个键值对占一行,也算是属性文件。Properties:1.是一个Map集合(键值对集合),但是我们一般不会当集
- Java工具类:将xml转为Json
天黑请闭眼
Java工具类JSONjavaxmljson
目录一、场景二、工具类三、测试类四、测试结果一、场景在对接第三方接口时,由于接口返回的并不是常见的Json,而是XML,所以需要将XML转为Json,方便后续处理二、工具类packagecom.xxx.util;importorg.apache.commons.lang.StringUtils;importorg.dom4j.Document;importorg.dom4j.Element;imp
- Java调用WebService接口,SOAP协议HTTP请求返回XML对象
cxzm_1024
WebServiceWebService
Java调用Webservice接口SOAP协议HTTP请求,解析返回的XML字符串:1.使用Java的HTTP库发送SOAP请求,并接收返回的响应。可以使用Java的HttpURLConnection、ApacheHttpClient等库。2.将返回的响应转换为字符串。3.解析XML字符串,可以使用Java的DOM解析器或者其他第三方库,如JDOM、DOM4J等。4.解析XML数据,提取需要的信
- Dom4j 根据指定的节点属性获取节点内容
莫扎特不唱摇篮曲
yoursqlhere1yoursqlhere2java代码片段如下:publicstaticStringget(Stringattr){Documentdoc=getXmlDocument();Elementroot=doc.getRootElement();Nodenode=root.selectSingleNode("sql[@name='"+attr+"']");//[@name='Rep
- XML格式目录解析——DOM,SAX,Dom4j方式
程序猿老王
开发工具androidxmljavadom
一、概况项目中要解析一个XML格式的目录,经过搜索了解到,解析方式主要有DOM,Pull,SAX三种方式,各自特点如下:SAXsax是一个用于处理xml事件驱动的“推”模型;优点:解析速度快,占用内存少,它需要哪些数据再加载和解析哪些内容。缺点:它不会记录标签的关系,而是需要应用程序自己处理,这样就会增加程序的负担。DOMdom是一种文档对象模型;优点:dom可以以一种独立于平台和语言的方式访问和
- XML数据如何进行解析呢,方式有哪些?
一纸油伞
问题:XML数据如何进行解析呢,方式有哪些?上回我们说到JSON解析的四种方式,那么这次我们来看看XML的四种解析方式。解析的四种方式DOM解析SAX解析JDOM解析DOM4J解析案例实操DOM解析DOM(DocumentObjectModel,文档对象模型),在应用程序中,基于DOM的XML分析器将一个XML文档转换成一个对象模型的集合(通常称为DOM树),应用程序正是通过对这个对象模型的操作,
- java解析json复杂数据的第三种思路
爱码少年
雕虫小技Javajavajson
文章目录一、概述二、数据预览1.接口json数据2.json转xml数据三、代码实现1.pom.xml2.核心代码3.运行结果四、源码传送一、概述接上篇java解析json复杂数据的两种思路我们已经通过解析返回json字符串得到数据,现在改变思路,按照如下流程获取数据:接口API获取JSONJSON转XMLdom4j使用XPath解析xml二、数据预览1.接口json数据https://blog.
- 第四章 XML
幸运小新
JavaWebxmljava前端
第四章XML1.什么是XML以及它的作用2.第一个XML示例文件3.XML语法介绍4.xml解析技术介绍5.使用dom4j读取xml文件得到document对象6.使用dom4j解析xml1.什么是XML以及它的作用2.第一个XML示例文件3.XML语法介绍第三条,是可以的下面有两个根元素,就会报错4.xml解析技术介绍5.使用dom4j读取xml文件得到document对象使用dom4j解析以下
- javaweb
wang_yun_xi
Day01.61.myeclipse的介绍...62.xml入门...73.xml乱码【★★★】...94.xml约束...95.xml约束--dtd【☆】...96.名字解释...127.xml约束--schema.128.解析技术...149.JAXP.14Day02.161.dom4j(domforjava)(day02)172.myeclipse介绍(day02)173.debug【★★★
- XML解析神器:Apache Commons Digester
宋小黑
ApacheCommons工具实战手册xmlapachejava
第1章:引言大家好,我是小黑。今天咱们聊聊一个在现代编程中经常遇到的话题:XML解析。你可能知道,XML(可扩展标记语言)因其灵活性和可读性,在配置文件、数据交换等方面广泛使用。但是,XML解析有时候会让人头疼,尤其是当文件结构复杂或者数据量巨大时。这时候,一个好用的工具就显得尤为重要了。在Java世界里,有很多工具可以用来解析XML,比如JAXP,JAXB,DOM4J等。但今天咱们要讨论的是Ap
- Java解析xml文档,判断对象是一个json是jsonArray还是jsonObject
家家小迷弟
workspringbootjavaxmljson
有一篇xml文档,如下:现在需要解析出其中的内容,首先需要明确的是,文档是由一个个的标签嵌套形成的,例如整个xml文件是由许多DescriptorRecord标签构成,xxxxxxxxxx现在需要解析出每个DescriptorRecord里面嵌套的xxxx各层级标签里面的内容,导入的依赖有:org.dom4jdom4j2.1.1com.alibabafastjson1.2.73解析代码如下:Fil
- 继之前的线程循环加到窗口中运行
3213213333332132
javathreadJFrameJPanel
之前写了有关java线程的循环执行和结束,因为想制作成exe文件,想把执行的效果加到窗口上,所以就结合了JFrame和JPanel写了这个程序,这里直接贴出代码,在窗口上运行的效果下面有附图。
package thread;
import java.awt.Graphics;
import java.text.SimpleDateFormat;
import java.util
- linux 常用命令
BlueSkator
linux命令
1.grep
相信这个命令可以说是大家最常用的命令之一了。尤其是查询生产环境的日志,这个命令绝对是必不可少的。
但之前总是习惯于使用 (grep -n 关键字 文件名 )查出关键字以及该关键字所在的行数,然后再用 (sed -n '100,200p' 文件名),去查出该关键字之后的日志内容。
但其实还有更简便的办法,就是用(grep -B n、-A n、-C n 关键
- php heredoc原文档和nowdoc语法
dcj3sjt126com
PHPheredocnowdoc
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Current To-Do List</title>
</head>
<body>
<?
- overflow的属性
周华华
JavaScript
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml&q
- 《我所了解的Java》——总体目录
g21121
java
准备用一年左右时间写一个系列的文章《我所了解的Java》,目录及内容会不断完善及调整。
在编写相关内容时难免出现笔误、代码无法执行、名词理解错误等,请大家及时指出,我会第一时间更正。
&n
- [简单]docx4j常用方法小结
53873039oycg
docx
本代码基于docx4j-3.2.0,在office word 2007上测试通过。代码如下:
import java.io.File;
import java.io.FileInputStream;
import ja
- Spring配置学习
云端月影
spring配置
首先来看一个标准的Spring配置文件 applicationContext.xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi=&q
- Java新手入门的30个基本概念三
aijuans
java新手java 入门
17.Java中的每一个类都是从Object类扩展而来的。 18.object类中的equal和toString方法。 equal用于测试一个对象是否同另一个对象相等。 toString返回一个代表该对象的字符串,几乎每一个类都会重载该方法,以便返回当前状态的正确表示.(toString 方法是一个很重要的方法) 19.通用编程:任何类类型的所有值都可以同object类性的变量来代替。
- 《2008 IBM Rational 软件开发高峰论坛会议》小记
antonyup_2006
软件测试敏捷开发项目管理IBM活动
我一直想写些总结,用于交流和备忘,然都没提笔,今以一篇参加活动的感受小记开个头,呵呵!
其实参加《2008 IBM Rational 软件开发高峰论坛会议》是9月4号,那天刚好调休.但接着项目颇为忙,所以今天在中秋佳节的假期里整理了下.
参加这次活动是一个朋友给的一个邀请书,才知道有这样的一个活动,虽然现在项目暂时没用到IBM的解决方案,但觉的参与这样一个活动可以拓宽下视野和相关知识.
- PL/SQL的过程编程,异常,声明变量,PL/SQL块
百合不是茶
PL/SQL的过程编程异常PL/SQL块声明变量
PL/SQL;
过程;
符号;
变量;
PL/SQL块;
输出;
异常;
PL/SQL 是过程语言(Procedural Language)与结构化查询语言(SQL)结合而成的编程语言PL/SQL 是对 SQL 的扩展,sql的执行时每次都要写操作
- Mockito(三)--完整功能介绍
bijian1013
持续集成mockito单元测试
mockito官网:http://code.google.com/p/mockito/,打开documentation可以看到官方最新的文档资料。
一.使用mockito验证行为
//首先要import Mockito
import static org.mockito.Mockito.*;
//mo
- 精通Oracle10编程SQL(8)使用复合数据类型
bijian1013
oracle数据库plsql
/*
*使用复合数据类型
*/
--PL/SQL记录
--定义PL/SQL记录
--自定义PL/SQL记录
DECLARE
TYPE emp_record_type IS RECORD(
name emp.ename%TYPE,
salary emp.sal%TYPE,
dno emp.deptno%TYPE
);
emp_
- 【Linux常用命令一】grep命令
bit1129
Linux常用命令
grep命令格式
grep [option] pattern [file-list]
grep命令用于在指定的文件(一个或者多个,file-list)中查找包含模式串(pattern)的行,[option]用于控制grep命令的查找方式。
pattern可以是普通字符串,也可以是正则表达式,当查找的字符串包含正则表达式字符或者特
- mybatis3入门学习笔记
白糖_
sqlibatisqqjdbc配置管理
MyBatis 的前身就是iBatis,是一个数据持久层(ORM)框架。 MyBatis 是支持普通 SQL 查询,存储过程和高级映射的优秀持久层框架。MyBatis对JDBC进行了一次很浅的封装。
以前也学过iBatis,因为MyBatis是iBatis的升级版本,最初以为改动应该不大,实际结果是MyBatis对配置文件进行了一些大的改动,使整个框架更加方便人性化。
- Linux 命令神器:lsof 入门
ronin47
lsof
lsof是系统管理/安全的尤伯工具。我大多数时候用它来从系统获得与网络连接相关的信息,但那只是这个强大而又鲜为人知的应用的第一步。将这个工具称之为lsof真实名副其实,因为它是指“列出打开文件(lists openfiles)”。而有一点要切记,在Unix中一切(包括网络套接口)都是文件。
有趣的是,lsof也是有着最多
- java实现两个大数相加,可能存在溢出。
bylijinnan
java实现
import java.math.BigInteger;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class BigIntegerAddition {
/**
* 题目:java实现两个大数相加,可能存在溢出。
* 如123456789 + 987654321
- Kettle学习资料分享,附大神用Kettle的一套流程完成对整个数据库迁移方法
Kai_Ge
Kettle
Kettle学习资料分享
Kettle 3.2 使用说明书
目录
概述..........................................................................................................................................7
1.Kettle 资源库管
- [货币与金融]钢之炼金术士
comsci
金融
自古以来,都有一些人在从事炼金术的工作.........但是很少有成功的
那么随着人类在理论物理和工程物理上面取得的一些突破性进展......
炼金术这个古老
- Toast原来也可以多样化
dai_lm
androidtoast
Style 1: 默认
Toast def = Toast.makeText(this, "default", Toast.LENGTH_SHORT);
def.show();
Style 2: 顶部显示
Toast top = Toast.makeText(this, "top", Toast.LENGTH_SHORT);
t
- java数据计算的几种解决方法3
datamachine
javahadoopibatisr-languer
4、iBatis
简单敏捷因此强大的数据计算层。和Hibernate不同,它鼓励写SQL,所以学习成本最低。同时它用最小的代价实现了计算脚本和JAVA代码的解耦,只用20%的代价就实现了hibernate 80%的功能,没实现的20%是计算脚本和数据库的解耦。
复杂计算环境是它的弱项,比如:分布式计算、复杂计算、非数据
- 向网页中插入透明Flash的方法和技巧
dcj3sjt126com
htmlWebFlash
将
Flash 作品插入网页的时候,我们有时候会需要将它设为透明,有时候我们需要在Flash的背面插入一些漂亮的图片,搭配出漂亮的效果……下面我们介绍一些将Flash插入网页中的一些透明的设置技巧。
一、Swf透明、无坐标控制 首先教大家最简单的插入Flash的代码,透明,无坐标控制: 注意wmode="transparent"是控制Flash是否透明
- ios UICollectionView的使用
dcj3sjt126com
UICollectionView的使用有两种方法,一种是继承UICollectionViewController,这个Controller会自带一个UICollectionView;另外一种是作为一个视图放在普通的UIViewController里面。
个人更喜欢第二种。下面采用第二种方式简单介绍一下UICollectionView的使用。
1.UIViewController实现委托,代码如
- Eos平台java公共逻辑
蕃薯耀
Eos平台java公共逻辑Eos平台java公共逻辑
Eos平台java公共逻辑
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
蕃薯耀 2015年6月1日 17:20:4
- SpringMVC4零配置--Web上下文配置【MvcConfig】
hanqunfeng
springmvc4
与SpringSecurity的配置类似,spring同样为我们提供了一个实现类WebMvcConfigurationSupport和一个注解@EnableWebMvc以帮助我们减少bean的声明。
applicationContext-MvcConfig.xml
<!-- 启用注解,并定义组件查找规则 ,mvc层只负责扫描@Controller -->
<
- 解决ie和其他浏览器poi下载excel文件名乱码
jackyrong
Excel
使用poi,做传统的excel导出,然后想在浏览器中,让用户选择另存为,保存用户下载的xls文件,这个时候,可能的是在ie下出现乱码(ie,9,10,11),但在firefox,chrome下没乱码,
因此必须综合判断,编写一个工具类:
/**
*
* @Title: pro
- 挥洒泪水的青春
lampcy
编程生活程序员
2015年2月28日,我辞职了,离开了相处一年的触控,转过身--挥洒掉泪水,毅然来到了兄弟连,背负着许多的不解、质疑——”你一个零基础、脑子又不聪明的人,还敢跨行业,选择Unity3D?“,”真是不自量力••••••“,”真是初生牛犊不怕虎•••••“,••••••我只是淡淡一笑,拎着行李----坐上了通向挥洒泪水的青春之地——兄弟连!
这就是我青春的分割线,不后悔,只会去用泪水浇灌——已经来到
- 稳增长之中国股市两点意见-----严控做空,建立涨跌停版停牌重组机制
nannan408
对于股市,我们国家的监管还是有点拼的,但始终拼不过飞流直下的恐慌,为什么呢?
笔者首先支持股市的监管。对于股市越管越荡的现象,笔者认为首先是做空力量超过了股市自身的升力,并且对于跌停停牌重组的快速反应还没建立好,上市公司对于股价下跌没有很好的利好支撑。
我们来看美国和香港是怎么应对股灾的。美国是靠禁止重要股票做空,在
- 动态设置iframe高度(iframe高度自适应)
Rainbow702
JavaScriptiframecontentDocument高度自适应局部刷新
如果需要对画面中的部分区域作局部刷新,大家可能都会想到使用ajax。
但有些情况下,须使用在页面中嵌入一个iframe来作局部刷新。
对于使用iframe的情况,发现有一个问题,就是iframe中的页面的高度可能会很高,但是外面页面并不会被iframe内部页面给撑开,如下面的结构:
<div id="content">
<div id=&quo
- 用Rapael做图表
tntxia
rap
function drawReport(paper,attr,data){
var width = attr.width;
var height = attr.height;
var max = 0;
&nbs
- HTML5 bootstrap2网页兼容(支持IE10以下)
xiaoluode
html5bootstrap
<!DOCTYPE html>
<html>
<head lang="zh-CN">
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">