ACM MM 2018论文概述:基于多粒度监督的图像语义物体协同标注

作者丨张立石、付程晗、李甲
学校丨北京航空航天大学
研究方向丨计算机视觉
介绍
本文概述了被 2018 年 10 月 ACM Multimedia 会议录用为 Oral 的论文:Collaborative Annotation of Semantic Objects in Images with Multi-granularity Supervisions。在此论文中,北京航空航天大学硕士研究生张立石、付程晗及其导师李甲,提出了一种基于多粒度监督的图像语义物体协同标注的方法,实现了在几乎不影响标注精确度的前提下,减少了人工标注的时间。
■ 论文 | Collaborative Annotation of Semantic Objects in Images with Multi-granularity Supervisions
■ 链接 | https://www.paperweekly.site/papers/2218
■ 源码 | http://dwz.cn/kltHyMz0
■ 主页 | http://cvteam.net/
背景
在过去 10 年,大规模图像数据集大大推动了计算机视觉技术的发展。这些数据集中的图片被一个或多个标签标注,用于描绘图片中主要对象的语义类别。在最新的应用,比如自动驾驶,机器人导航,视觉问题回答等,仅有图像级标签是不够的,这些应用需要像素级的语义对象:图像中的对象是什么、在哪里。
计算机视觉领域对像素级标注语义对象的需求越来越强烈,但是像素级的标注是冗余乏味的,需要耗费大量的人力资源。因此,为了将现有图像级标签的数据集转化为像素级标注的数据集,在标注精确度不受影响的前提下,减少人工标注时间是很有必要的。
机器和人协同标注的方法已经被研究多年,基于协同策略,现有的方法被分为两类:Agent-decision 和 Human-decision。
Agent-decision 就是首先标注者进行粗略的标注,然后机器进行自动修正。这些标注结果很少作为 ground-truth。
Human-decision 就是首先让机器自动生成粗略的标注结果,然后标注者进行手工精细修正,这些标注结果是可以作为 ground-truth。显然,机器标注结果越好,人工修正的时间越短。但是 Human-decision 方法中缺点就是,机器初始化是静态的,需要预定义或预先训练参数,这就意味着会反复的犯同样的错误即使分割同一个语义对象。
因此,很多协同标注方式都是通过利用机器的参与减少人工标注时间,但是仍然存在一些问题,鉴于此本文提出了一种智能协同标注工具 Colt:在人机交互标注的过程中不断学习,使得机器的标注越来越好,人工参与越来越少。
思路
本论文的总体思路是首先利用机器自动生成初始标注结果,人工修正,随着人工修正的结果越多,机器进行学习可以进行机器自动修正,进一步减少人工修正。整体框架图如图 1 所示。
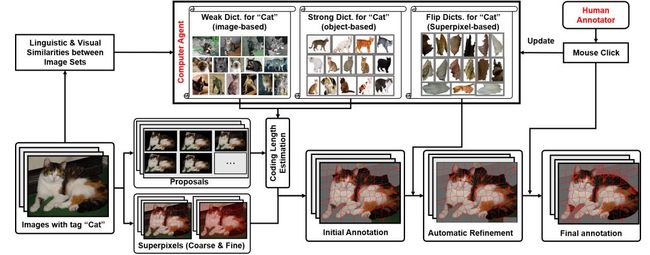
▲ 图1. 论文整体框架
机器自动化
机器自动化标注主要利用稀疏编码的思想,对待标注图像进行编码,编码长度的大小就意味属于前景物体的可能性大小,选择一个阈值分离前背景就能得到自动化标注结果。对于机器初始化标注,作者首先构建了两个字典:强字典、弱字典,将这两个字典作为稀疏编码图像的码表。
字典构建
首先根据每一类图像的语义标签计算语义相似性,然后根据图像特征计算每类图像之间的视觉相似性,联合得到每类图像之间的总相似性。选择相似性大于 0.95 的类别作为当前类别的稀疏编码字典。有像素级标注图像类别的特征的作为强字典,没有像素级标注图像类别特征的作为弱字典。
稀疏编码
编码对象是用 MCG 算法对图像提取出来的排在前 200 的图像 proposal。由于图像的分辨率和像素密度很高,作者为减少人工点击次数,借助超像素块进行操作。作者把 proposal 编码长度映射到超像素块并归一化得到每个超像素块的属于前景的可能性值,选择大于 0.4 的作为前景,剩下的作为背景,得到机器初始化结果。
人工修正
根据机器初始化结果,标注者进行修正:如果前后背景错误直接点击左键,如果边缘分割错误,首先点击右键进行分裂成更小的超像素块,然后点击左键。在人工修正的过程,机器会自动保存点击超像素块的 3 邻域特征用于后续的机器自动修正。
机器自动修正
选择在阈值 0.4 上下 0.15 范围内的超像素块,用人工修正保存的超像素块 3 邻域特征进行稀疏编码,得到这些超像素块的编码长度,归一化选择大于 0.95 的超像素块进行前景背景在初始化基础上进行反转。得到机器自动修正结果。随着人工标注的结果越多,机器能学的越精确,自动化修正结果会更好。
实验
本文选取了 40 个图像类别。在 ImageNet 数据集 1000 类中并且和 MSCOCO 有相同标签的 10 个类别、在 ImageNet 数据集 1000 类中并且和MSCOCO有不同标签的 10 个类别、不在 ImageNet 数据集 1000 类中并且和 MSCOCO 有相同标签的 10 个类别,不在 ImageNet 数据集 1000 类中并且和 MSCOCO 有不同标签的 10个 类别。
作者选择 10 个年龄在 20-28 周岁之间的标注者进行标注,每个标注者用 LabelMe 进行标注 4 个图像类别。得到 LabelMe 的标注结果,作为本文的 ground-truth。
为了比较作者方法的自动分割结果,作者和当前自动分割处于领先水平的两个方法:DeepMask 和 SharpMask 进行比较。发现这两个方法的结果都明显低于 Colt 的初始化结果。具体结果见图 2。

▲ 图2. 自动化对比结果
为了比较最终标注结果,作者选择另外 10 个年龄在 20-28 之间的标注者用 Colt 进行标注,和 LabelMe 的标注结果计算 F-measure,最终平均结果是 91.21。并比较了 Top5 和 Bottom5,具体结果见图 3。标注对比结果见图 4。

▲ 图3. 最终标注结果

▲ 图4. 标注对比结果
作者还做了机器自动修正结果对比实验,发现机器自动修正是有效的,结果见图 5。

▲ 图5. 自动修正结果
但是 Colt 还是有一些缺陷,尤其是边界超像素分割得不够好,失败的标注结果见图 6 。

▲ 图6. 失败结果
总结
与当前能作为 Ground-Truth 的人工标注方法 LabelMe 的标注结果相比,作者标注工具 collaborative tool (Colt) 的标注结果 f-measure 值能够达到 91.21%,同时作者的标注工具能节约 50% 的人工标注时间。实验结果表明在兼顾精确度的情况下还能大大的减少标注时间。

点击以下标题查看更多论文解读:
网络表示学习综述:一文理解Network Embedding
细水长flow之NICE:流模型的基本概念与实现
如何让GAN生成更高质量图像?斯坦福给你答案
哈佛NLP组论文解读:基于隐变量的注意力模型
ACL2018高分论文:混合高斯隐向量文法
COLING 2018最佳论文:序列标注经典模型复现
一文解析OpenAI最新流生成模型「Glow」
 #投 稿 通 道#
#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢? 答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。