Redis 集群、哨兵、主从同步
目录
- redis集群简介
- 搭建redis集群
- redis集群原理
- 哨兵(Sentinel)机制
- 设置值、取值流程
- 故障迁移 failover
- 晋升机制
- 集群不可用
- 主从同步
- 主从同步的作用
- redis的同步机制
redis集群简介
单机版redis server,redis server容量受单机内存限制,往往需要redis server集群来扩容,提升redis数据库的容量。
redis 5.0之前通过执行redis-trib.rb创建redis集群,redis-trib.rb是ruby语言写的脚本,需要配置ruby环境,还需要安装redis.gem来管理集群。redis 5.0开始用redis-cli代替redis-trib.rb,虽然redis-trib.rb现在还能用(向下兼容),但后续会被取消掉,建议使用redis-cli来创建集群。
此处以redis 5.x为例创建redis集群。
# 查看redis server版本
./redis-server -v
./redis-server --version
搭建redis集群
1、redis集群至少要3个master,且每个master至少要有一个slave,所以最少要6个节点
如果节点数量不满足要求,后续会报错

2、编辑所有集群节点的redis.conf,允许集群
![]()
参加集群的所有节点都不能是slave,如果配置了replicaof,将其注释掉。
哪些节点作为master、哪些节点作为slave,由集群自动分配,不能手动设置。
3、参与集群的节点,数据库必须是空的,如果有.rdb、.aof等数据库文件,需先删除
如果集群搭建失败,重试时需要先删除之前生成的数据库文件(.rdb、.aof)。如果数据库不为空,后续会报错
![]()
4、先启动参与集群的每个redis server,再使用某个redis-cli创建集群
./redis-cli --cluster create 192.168.1.1:6379 192.168.1.2:6379 192.168.1.3:6379 192.168.1.4:6379 192.168.1.5:6379 192.168.1.6:6379 --cluster-replicas 1
指定参加集群的节点(ip、port),参数cluster-replicas指定每个master分配几个slave。自动分配时,一般是前面的节点都作为master,后面的都作为slave。
会给出集群配置方案。(图是以前我在本地模拟时截的,所以ip都是127.0.0.1,只修改了端口。)
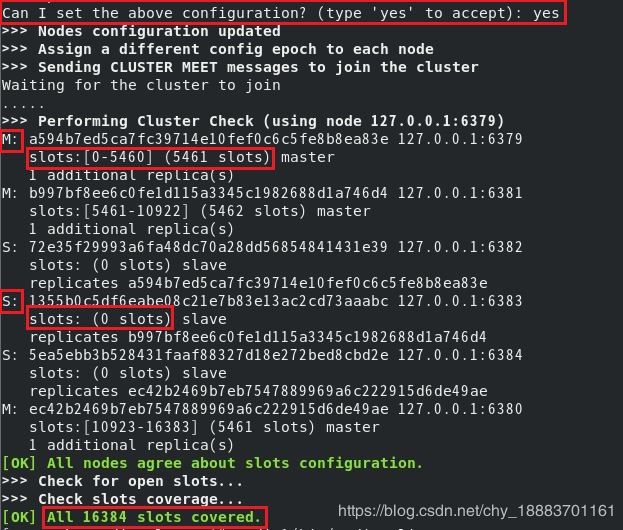
M是master,S是slave,slot(槽点)是用来执行写指令的,只分配给master,各个master的槽点数差不多。slave只是作为备份,不执行写指令,不分配槽点。
输入yes按方案执行
5、连接到集群中的某个节点即可连接到整个redis集群,查看集群信息
# 连接到集群时,不管是连接到master还是slave,都要加-c,c即cluster
redis1/bin/redis-cli -h 192.168.1.1 -p 6379 -c
# 查看集群信息
cluster info
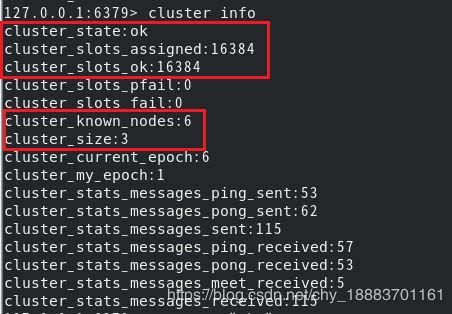
集群状态、槽点数、节点数都可以看到,其中集群大小cluster_size只算master。
# 查看当前连接到的节点的主从信息
info replication

可以看到当前节点的角色,如果是master会显示其从节点的信息,如果是slave会显示如果其master的信息。此外还能看到数据同步的偏移量。
设置值、取值

先根据key的哈希值确定槽点位置,自动转到该槽点所在的节点,然后在该槽点处设置值、取值。
redis集群原理
redis集群是把数据分散存储在多个master上,这些master共同组成一个完整的redis数据库,每个master上只存储部分key,也叫作分片。每个master都可以处理请求,slave只用于所属master的数据备份,不处理请求。
哨兵(Sentinel)机制
哨兵是redis server附带的程序,每个redis server(master、slave)都自带得有,默认未配置哨兵。redis server默认使用6379,哨兵默认使用26379。
创建redis集群时,会自动给每个节点配置哨兵,用于监控集群中各个节点(master+slave)的状态。每个节点(master+slave)上都有一个节点信息文件记录集群各节点的信息
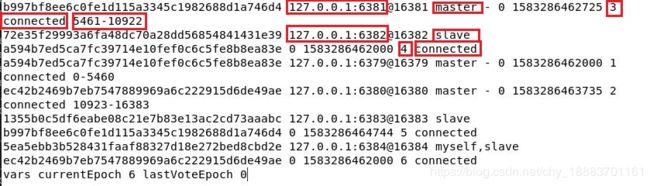
包括各个节点的ip、port,角色(master、slave),是集群中的第几个节点,和当前节点之间是否能ping通(是否connected)。如果是master,还包括槽点区间。
设置值、取值流程
设置值、取值的时候,先根据key的hash值确定槽点位置,再根据节点信息文件确定该槽点所在节点(ip、port),转交给该节点操作。
redis.conf
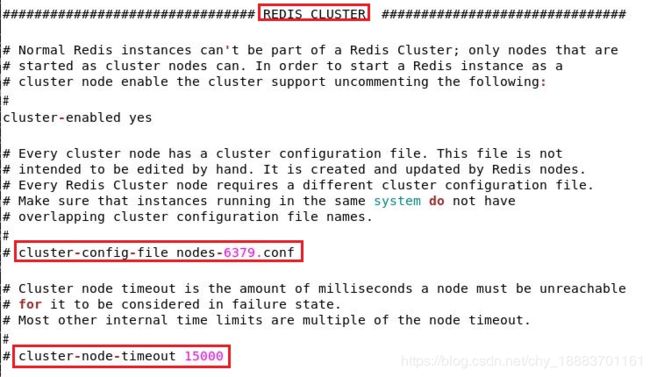
第一个配置是节点信息文件的保存路径,默认保存路径是数据存储目录(.aof、.rdb所在目录)下的nodes.conf文件。
创建集群时会往每个节点的nodes.conf中写入集群初始配置,集群创建后,每个节点的哨兵每秒都会ping一下其它节点,确定其它节点的状态,来维护|更新节点信息文件。
第二个配置指定超时时间,默认15000ms,即15s。如果哨兵在15s内都没有ping通某个节点,就主观认为该节点down掉了,将该节点的状态标识为sdown,s即subjectively 主观。
如果超过一半的master都将某个master的状态标识为sdown,就认为客观上该master节点确实down掉了,将该master节点的状态标识为odown,o即objectively ,客观。哨兵会自动将从该master的所有slave中选一个新的master。注意是哨兵确定新的master,不是由其它master确定。
故障迁移 failover
故障迁移是指:master故障,从附属slave中选出新master,其它附属slave从新master同步数据的过程。具体过程如下
- try-failover master的状态被标识odown,集群尝试进行故障转移
- elected-leader 从该master的附属slave中选出新master
- selected-slave 已选出新的master
- send-slaveof-noone 向新master发送slaveof no one命令,摆脱slave地位
- wait-promotion 等待新master完成配置更新,晋升为master。配置更新有2个方面:一是去掉replicaof配置摆脱slave角色,二是继承原master的槽点、得到写权限(slave默认只读)
- promoted 晋升完成
- 其它附属slave从新master同步全量数据
故障迁移期间,整个redis集群不对外提供服务。redis集群和zk集群很相似,数据一致性强,但可用性得不到保证。
晋升机制
redis.conf

优先级有3个值:10,25,100,默认100。
选举新master时自动选择优先级大的,如果优先级相同,则看偏移量,偏移量小的数据新,自动选择偏移量小的。
集群不可用
以下2种情况都会使redis集群不可用(集群状态为fail)
- 某个master节点及其所有slave节点都down掉
- master节点短时间内down掉一半以上,不管有没有代替的slave,整个集群直接不可用
主从同步
创建redis集群时会自动设置哨兵、主从关系
主从同步的作用
- 数据冗余(备份)
- 提高可用性:master故障,可将某个slave作为新的master
至于读写分离,用master处理写请求(、读请求),slave处理读请求,这对redis来说没必要。
读写分离主要有2个作用:①减轻master压力,提高整体负载,②提高性能。
关系数据库读写数据要进行文件IO,耗时、性能差,需要读写分离提高性能,redis本身是内存数据库,性能极高,不需要读写分离来提高性能;关系数据库集群通常是一主多从,需要从库分担读请求的压力,redis集群本身就有多个master,通过多个master来分担读写压力、存储压力,不需要slave来分担。
所以redis集群一般不做读写分离,没必要,slave只作数据备份,读写请求都由master处理。
redis的同步机制
全量同步

增量同步
