数据处理:pandas中统计、索引、分组
目录
- 第一部分:pandas操作
- 一.成员唯一性及个数统计
- 二.索引
- 三.分组计算
第一部分:pandas操作
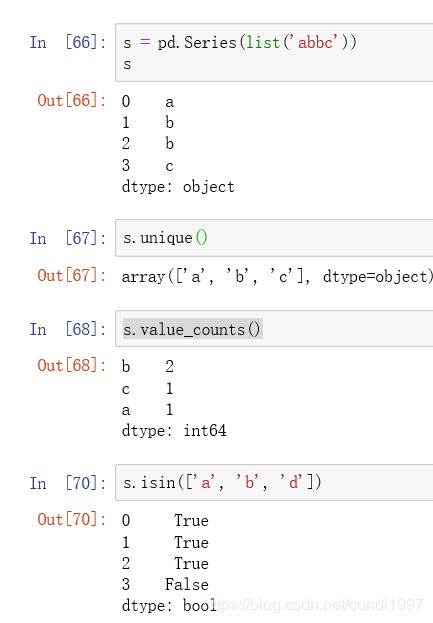
一.成员唯一性及个数统计
s.unique()----返回表示s中数值的array
s.value_counts()----返回表示s中各数值个数的Series
s.isin([‘a’, ‘b’, ‘c’])----返回s中每个元素是否在(a,b,c)之中的Series,值为布尔型
二.索引
1.对于重复索引的处理:.groupby()
s.groupby(s.index).sum()----可对s中索引进行分组,并将相同索引进行求和。
2.层次化索引:使用pd.MultiIndex类表示更高的维度
a = [['a', 'a', 'a', 'b', 'b', 'c', 'c'], [1, 2, 3, 1, 2, 2, 3]]
tuples = list(zip(*a))
index = pd.MultiIndex.from_tuples(tuples,names=['column1','column2'])
s = pd.Series(np.random.randn(7), index=index)
s
out[]:
first second
a 1 -1.192113
2 0.226627
3 0.390052
b 1 0.045297
2 1.552926
c 2 0.014007
3 -0.257103
dtype: float64s.index.level[0]----查看层次化索引
1)Serise中层次化索引:

2)DataFrame中多层索引: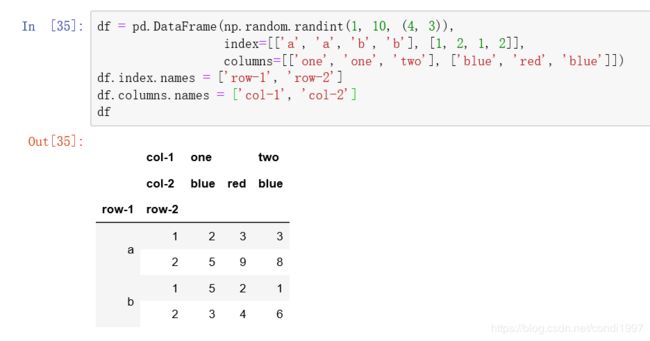
索引操作:
df2 = df.swaplevel(‘row-1’, ‘row-2’)----交换row1和row2两个索引位置
df.set_index(‘c’)----把c列变成行索引c
df.reset_index()----把df的行索引全部重置为列索引
三.分组计算
1.对DataFrame进行分组:使用.groupby()函数
df[‘data1’].groupby([df[‘key1’], df[‘key2’]]).mean()----将df中的data1列数据按照key1和key2进行分组,统计求平均值。
df.groupby([‘key1’, ‘key2’]).mean()[‘data1’]----将df关于key1和key2进行分组,并求平均值,取data1数据。
2.对分组进行迭代:

3.利用字典分组:
df = pd.DataFrame(np.random.randint(1, 10, (5, 5)),
columns=['a', 'b', 'c', 'd', 'e'],
index=['Alice', 'Bob', 'Candy', 'Dark', 'Emily'])
df.iloc[1, 1:3] = np.NaN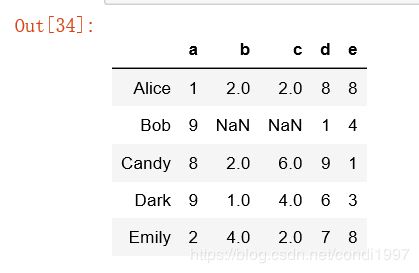
mapping = {'a': 'red', 'b': 'red', 'c': 'blue', 'd': 'orange', 'e': 'blue'}
grouped = df.groupby(mapping, axis=1)
grouped.count()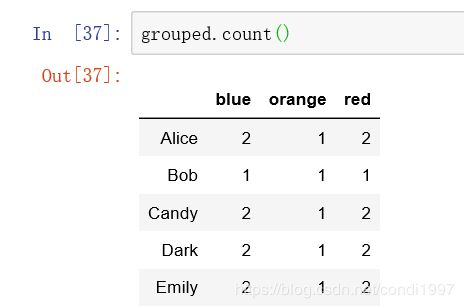
4.利用函数分组:
df.groupby(函数名,axis=0)----默认axis=0,即将行索引按照函数返回值分组,axis=1时将列索引按照函数返回值分组
5.通过索引级别进行分组:当有多级分组MultiIndex时
df.groupby(level=‘country’, axis=1).sum()----将df的列索引中的country级索引进行分作,并对数据求和