准备
1.准备3台物理机 我这里通过本地机和2台虚拟模拟我是mac通过(Parallel Desktop 实现)
2.按照签名的liux安装步骤在3台机器都安装rabiitMq
3.将任意一节点的cookie复制到其他2台保证一致 cookie路径为$HOME/.erlang.cookie 可以通过echo $HOME 查看环境变量值

注:如果提示只读 1.ctrl+c退出 执行sudo!! 2.执行 vim 修改文件 3.保存加上!强制执行 :wq!
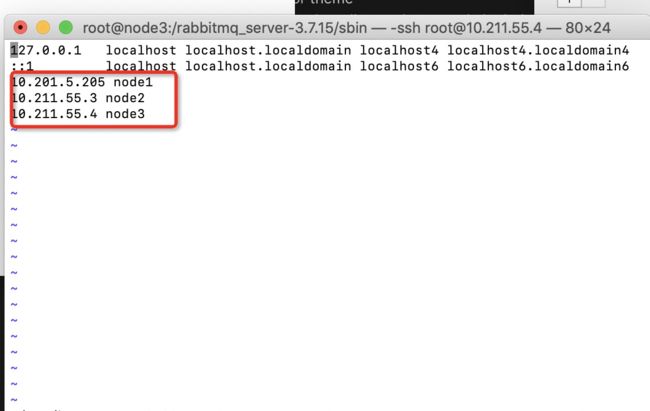
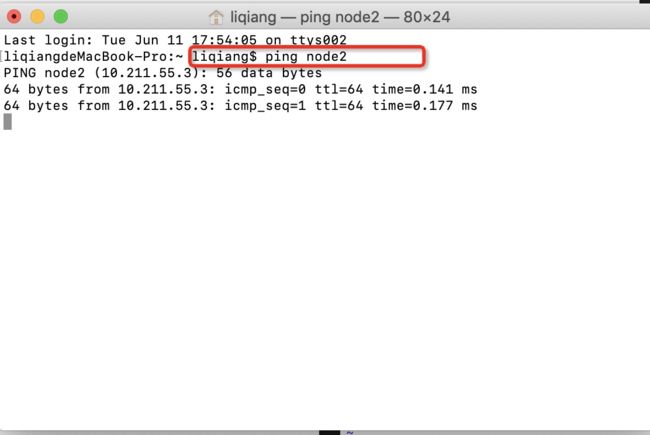
4.修改每台机器的host映射保证根据映射能相互ping通
5.守护进程启动三台mq
./rabbitmq-server -detached
6.检查启动状态
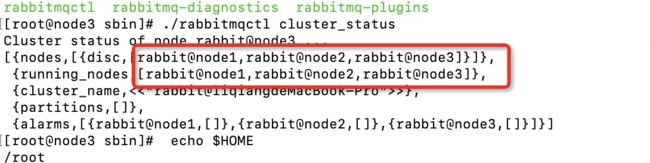
./rabbitmqctl cluster_status
7.如果启动成功如下图 我这里是已经加入集群了 所以看到三个节点 未加入集群就只能看到当前节点
8.分别在node2和node3自行加入集群节点(因为是同级的所以顺序没关系 可以是在node1 node3 执行加入node2)
rabbitmqctl stop_app
rabbitmqctl join_cluster rabbit
rabbitmqctl start_app
9.然后通过任意节点执行./rabbitmqctl cluster_status就可以看到7那个图
10.需要注意 如果通过stop_app节点全部关闭 第一个启动节点需要是最后关闭的那个节点 其他节点启动都会等待它启动成功 超时会报错
如:我一次关闭节点1 节点2 节点3
然后我启动节点2

会处于等待状态 会一致等待node2
如果node2 由于某种情况无法启动 可以通过以下方式
方式1:
./rabbitmqctl forget_cluster_node rabbit@node3 -offline (测试过不行)
方式2(推荐):
在node2执行
./rabbitmqctl reset (测试过 也不行 会等待)
将重置集群 所有节点都成为一个独立节点
集群节点类型
1.通过./rabbitmqctl cluster_status
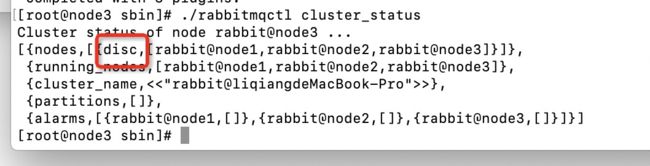
disc表示磁盘类型 保证队列、交换器、绑定关系、用户、权限、和vhost都会保存到磁盘 重启不会丢失
2.加入集群时可以通过指定为内存类型(部分节点使用内存类型保证最佳性能)
rabbitmqctl stop_app
rabbitmqctl join_cluster rabbit
rabbitmqctl start_app
3.如果集群已经搭建好了可以通过以下命令进行切换
./rabbitmqctl stop_app
./rabbitmqctl change_cluster_node_type ram
./rabbitmqctl start_app

注意点
rabbitMQ中 在集群中创建队列、交换器、或者绑定关系 需要所有集群中的节点都提交成功才会返回 这意味着都是磁盘节点写入磁盘操作是昂贵的
在内存节点提供高昂的性能磁盘节点提供可靠性 如何做抉择
rabbitMQ保证集群中至少一个集群节点 如果节点变更都会至少通知一个磁盘节点,如果磁盘节点挂了那么将不能添加元数据信息,所以我们再集群汇总至少保证2~3个磁盘节点其他都是内存节点
剔除节点
节点运行中
比如要剔除node3
1.在node3执行
./rabbitmqctl stop_app
2.集群中任意节点执行
./rabbitmqctl forget_cluster_node rabbit@node3
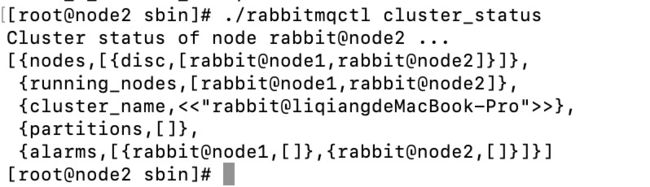
可以看到node3不存在了成功剔除
集群节点升级
思路描述 具体看书162页 大概是将新版本mq的数据路径指向老版本
一台机器部署多个节点
方便测试和验证集群特性 书163页
mq日志查看
书165页 不过跟当前版本不一致 日志文件路径再 rabbithome的var目录下
在打开rabbitMQ之前 可以他开一个新的窗口 tail -f 日志文件-n 200 查看实时每个操作日志是什么 久而久之就熟悉了
如果日志文件太大可以进行手动切分 如:./rabbitmqctl rotate_logs 01
后续日志则会记录在.01的文件里面(或者通过Liunx cronta 定时任务 每天切分)
可以通过创建mq相应交换器 日志信息会投递到对应的交换器绑定的对应队列 我们通过程序消费解析 通过程序查看 书:170页