搭建Hadoop分布式文件系统HDFS、海量列式存储数据库HBase
文章内容输出来源:Java工程师高薪训练营
目录
hadoop集群搭建
一、java环境准备
二、hadoop安装
hadoop下载
将hadoop添加到环境变量
测试是否安装成功
三、集群部署规划及配置文件说明
四、hadoop的配置
配置host,很重要!!!
进入安装目录,修改配置文件
五、 ssh 互通环境
六、关闭防火墙和开机自启
七、启停说明
格式化NameNode(格式化只进行一次!!!)
集群单点启动
集群分模块启动(需要配置SSH互通)
八、安装成功展示页面
hbase集群搭建(含zookeeper安装)
一、zookeeper安装
(1)zookeeper下载
(2)进入安装目录,修改配置文件
(3)配置zoo.cfg
(4)集群模式需要配置
(5)启动命令说明
二、hbase安装
(1)hbase下载
(2)修改配置文件
(3)配置hbase-env.sh
(4)配置hbase-site.xml
(5)配置regionservers
(6)配置backup-masters
(7)其他节点配置同上
(8)配置hbase的环境变量
(9)启停命令说明
(10)安装成功展示页面
hadoop集群搭建
Hadoop 是一个能够对 大量数据进行分布式处 理的 基础框架 。具有可靠、高效、可伸缩的特点。作为大数据, 首先你要能存的下大数据,其次存的下数据之后,你就开始考虑怎么处理数据。hadoop就是用来解决这两个问题的。
Hadoop特点
1)高可靠性:因为Hadoop假设计算元素和存储会出现故障,因为它维护多个工作数据副本,在出现故障时可以 对失败的节点重新分布处理。
2)高扩展性:在集群间分配任务数据,可方便的扩展数以千计的节点。
3)高效性:在MapReduce的思想下,Hadoop是并行工作的,以加快任务处理速度。
4)高容错性:自动保存多份副本数据,并且能够自动将失败的任务重新分配。
Hadoop组成
1)Hadoop HDFS:(hadoop distribute file system )一个高可靠、高吞吐量的分布式文件系统。
2)Hadoop MapReduce:一个分布式的离线并行计算框架。
3)Hadoop YARN:作业调度与集群资源管理的框架。
4)Hadoop Common:支持其他模块的工具模块(Configuration、RPC、序列化机制、日志操作)。
HDFS架构概述
架构主要由四个部分组成,分别为HDFS Client、NameNode、DataNode和Secondary NameNode。下面我们分 别介绍这四个组成部分。
1)Client:就是客户端。
2)NameNode:就是Master,它是一个主管、管理者。
3) DataNode:就是Slave。NameNode下达命令,DataNode执行实际的操作
4) SecondaryNameNode:并非NameNode的热备。当NameNode挂掉的时候,它并不能马上替换NameNode 并提供服务。
YARN架构概述
核心思想:将MP1中JobTracker的资源管理和作业调度两个功能分开,分别由ResourceManager(RM)和 ApplicationMaster(AM)进程来实现。
1) ResourceManager(rm):处理客户端请求、启动/监控ApplicationMaster、监控NodeManager、资源分配与调度;
1、处理客户端请求;
2、启动或监控ApplicationMaster;
3、监控NodeManager;
4、资源的分配与调度。
2)NodeManager(nm):单个节点上的资源管理、处理来自ResourceManager的命令、处理来自 ApplicationMaster的命令;
1、单个节点上的资源管理;
2、处理来自ResourceManager上的命令;
3、处理来自ApplicationMaster上的命令。
3)ApplicationMaster:数据切分、为应用程序申请资源,并分配给内部任务、任务监控与容错。 管理一个在YARN内运行的应用程序的每个实例。ApplicationMaster 负责协调来自 ResourceManager 的资源,并 通过 NodeManager 监视容器的执行和资源使用(CPU、内存等的资源分配)
1、负责数据的切分;
2、为应用程序申请资源并分配给内部的任务;
3、任务的监控与容错。
4、Container:对任务运行环境的抽象,封装了CPU、内存等多维资源以及环境变量、启动命令等任务运行相关的信息。
MapReduce架构概述
Mapreduce是一个分布式运算程序的编程框架,是用户开发“基于hadoop的数据分析应用”的核心框架; Mapreduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行 在一个hadoop集群上。
MapReduce将计算过程分为两个阶段:Map(映射)和Reduce(归约)
1)Map阶段并行处理输入数据
2)Reduce阶段对Map结果进行汇总
一、java环境准备
#检查java环境
[root@localhost ~]# rpm -qa | grep jdk
#如果有进行卸载
[root@localhost ~]# yum -y remove 上一步查看到的拷贝到这里
#下载并安装
[root@localhost ~]# yum install java-1.8.0-openjdk
#通过yum安装的默认路径为:/usr/lib/jvm
#配置环境变量
[root@localhost jvm]# vim /etc/profile
#添加如下内容
#set java environment
export JAVA_HOME=/usr/lib/jvm/jre-1.8.0-openjdk-1.8.0.252.b09-2.el7_8.x86_64
export PATH=$PATH:$JAVA_HOME/bin
#使环境变量生效
[root@localhost ~]# source /etc/profile
#显示 java 版本信息
[root@localhost ~]# java -version二、hadoop安装
hadoop下载
[root@localhost ~]# cd /usr/local/src/
[root@localhost src]# wget https://archive.apache.org/dist/hadoop/common/hadoop-2.7.2/hadoop-2.7.2.tar.gz
[root@localhost src]# tar -zxvf hadoop-2.7.2.tar.gz -C /home/hadoop将hadoop添加到环境变量
[root@localhost src]# vim /etc/profile
#添加如下内容
#set hadoop environment
export HADOOP_HOME=/home/hadoop/hadoop-2.7.2
export PATH=$PATH:$HADOOP_HOME/bin
#使环境变量生效
[root@localhost src]# source /etc/profile测试是否安装成功
[root@localhost src]# hadoop version三、集群部署规划及配置文件说明
集群部署规划
| 192.168.127.128 | 192.168.127.129 | 192.168.127.130 | |
|---|---|---|---|
| HDFS | NameNode,DataNode | DataNode | DataNode,SecondaryNameNode |
| YARN | NodeManager | ResourceManager,NodeManager | NodeManager |
集群配置文件说明
| 配置文件名称 | 配置对象 | 主要内容 |
|---|---|---|
| hadoop-env.sh | hadoop运行环境 |
用来定义hadoop运行环境相关的配置信息 |
| core-site.xml | 集群全局参数 | 用于定义系统级别的参数,如HDFS URL、Hadoop的临时目录等 |
| hdfs-site.xml | HDFS | 如名称节点和数据节点的存储位置、文件副本的个数、文件的读取权限等 |
| mapred-site.xml | Mapreduce参数 | 包括JobHistory Server和应用程序参数两部分, 如reduce任务的默认个数,任务所能够使用内存的默认上下限等 |
| yarn-site.xml | 集群资源管理系统参数 | 配置ResourceManger,NodeManager的通信端口,web监控端口等 |
四、hadoop的配置
配置host,很重要!!!
配置slaves的时候,不能写ip,只能写hostname,所以要先配置host
[root@localhost hadoop-2.7.2]# vim /etc/hosts
#添加如下内容
192.168.127.128 ki1
192.168.127.129 ki2
192.168.127.130 ki3进入安装目录,修改配置文件
[root@localhost src]# cd /home/hadoop/hadoop-2.7.2配置hadoop-env.sh
[root@localhost hadoop-2.7.2]# vim etc/hadoop/hadoop-env.sh
#配置如下内容
export JAVA_HOME=/usr/lib/jvm/jre-1.8.0-openjdk-1.8.0.252.b09-2.el7_8.x86_64配置core-site.xml
[root@localhost hadoop-2.7.2]# vim etc/hadoop/core-site.xml
#配置如下内容
fs.defaultFS
hdfs://ki1:9000
hadoop.tmp.dir
/home/hadoop/hadoop-2.7.2/data/tmp
配置hdfs-site.xml
[root@localhost hadoop-2.7.2]# vim etc/hadoop/hdfs-site.xml
#配置如下内容(注意目录的创建)
dfs.replication
3
dfs.namenode.secondary.http-address
ki3:50090
dfs.namenode.name.dir
/home/hadoop/hadoop-2.7.2/dfs/name
dfs.datanode.data.dir
/home/hadoop/hadoop-2.7.2/dfs/name/node1
配置yarn-site.xml
[root@localhost hadoop-2.7.2]# vim etc/hadoop/yarn-site.xml
#配置如下内容
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
ki2
yarn.nodemanager.resource.memory-mb
3072
配置mapred-site.xml
[root@localhost hadoop-2.7.2]# cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml
[root@localhost hadoop-2.7.2]# vim etc/hadoop/mapred-site.xml
#配置如下内容
mapreduce.framework.name
yarn
配置slaves
[root@localhost hadoop-2.7.2]# vim etc/hadoop/slaves
#配置如下内容
ki1
ki2
ki3其他机器节点配置同上
将配置文件拷贝到其他两台机器上,不用再分别下载安装了(注意差异配置)。但需要机器间进行ssh互通
[root@localhost src]# cd /home/hadoop
#需要分别在192.168.127.129和192.168.127.130两台机器上建立文件夹 mkdir /home/hadoop -p
[root@localhost hadoop]# scp -r /home/hadoop/hadoop-2.7.2 192.168.127.129:/home/hadoop/hadoop-2.7.2
[root@localhost hadoop]# scp -r /home/hadoop/hadoop-2.7.2 192.168.127.130:/home/hadoop/hadoop-2.7.2五、 ssh 互通环境
三台机器均需要操作以下步骤
(1)生成密钥,每台机器都要执行,输入项直接回车即可,id_rsa(私钥) id_rsa.pub(公钥)
[root@localhost ~]# ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Created directory '/root/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
06:d8:ad:5a:a5:3d:0e:0c:f5:00:f0:76:e1:b9:c9:f8 [email protected]
The key's randomart image is:
+--[ RSA 2048]----+
| ....+ |
| . = * |
| = * + |
| . * O |
| . X S |
| + + . |
| . E . |
| |
| |
+-----------------+(2)将本地的公钥文~/.ssh/id_rsa.pub,追加到文件authorized_keys的末尾,并赋予权限
[root@localhost ~]# cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
#赋予文件权限
[root@localhost ~]# chmod 700 ~/.ssh/
[root@localhost ~]# chmod 600 ~/.ssh/authorized_keys(3)复制公钥到所有其他节点,输入项输入yes和机器的密码
[root@localhost ~]# ssh-copy-id -i /root/.ssh/id_rsa.pub 192.168.127.129
shell-init: error retrieving current directory: getcwd: cannot access parent directories: No such file or directory
The authenticity of host '192.168.127.129 (192.168.127.129)' can't be established.
ECDSA key fingerprint is 63:dd:13:03:34:1f:40:05:17:e1:81:86:95:3f:34:71.
Are you sure you want to continue connecting (yes/no)? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
[email protected]'s password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh '192.168.127.129'"
and check to make sure that only the key(s) you wanted were added.
#然后下面的命令可以查看复制过来得公钥,每台机器上都有其他机器的公钥证明操作成功
[root@localhost ~]# vim ~/.ssh/authorized_keys(4)分别连接本台机器和其他机器进行验证
[root@localhost ~]# ssh 192.168.127.128六、关闭防火墙和开机自启
[root@localhost ~]# systemctl stop iptables;
[root@localhost ~]# systemctl stop firewalld;
[root@localhost ~]# systemctl disable firewalld.service;七、启停说明
格式化NameNode(格式化只进行一次!!!)
会在namenode数据文件夹(hdfs-site.xml中dfs.namenode.name.dir的路径)中保存一个current/VERSION文件,记录clusterID
hadoop namenode -format集群单点启动
如果是新增节点或者是宕机重启,需要使用单点启动
#启动|停止hdfs组件
sbin/hadoop-daemon.sh start|stop namenode|datanode|secondarynamenode
#启动|停止yarn组件
sbin/yarn-daemon.sh start|stop resourcemanager|nodemanagerHDFS集群启动
(2)在192.168.127.128机器上启动NameNode(参见集群部署规划)
sbin/hadoop-daemon.sh start namenode(3)在192.168.127.130机器上启动SecondaryNameNode(参见集群部署规划)
sbin/hadoop-daemon.sh start secondarynamenode(4)在三台机器上分别启动DataNode
sbin/hadoop-daemon.sh start datanodeYARN集群启动
(1)在192.168.127.129机器上启动ResourceManager(参见集群部署规划)
sbin/yarn-daemon.sh start resourcemanager(2)在三台机器上分别启动DataNode
sbin/yarn-daemon.sh start nodemanager集群分模块启动(需要配置SSH互通)
#在 NameNode 节点所在机器启动停止
[root@localhost ~]# /home/hadoop/hadoop-2.7.2/sbin/start-dfs.sh
[root@localhost ~]# /home/hadoop/hadoop-2.7.2/sbin/stop-dfs.sh
#在 ResourceManager 节点所在机器启动停止
[root@localhost ~]# /home/hadoop/hadoop-2.7.2/sbin/start-yarn.sh
[root@localhost ~]# /home/hadoop/hadoop-2.7.2/sbin/stop-yarn.sh启动后可以看到如下日志,可以分别到各节点所在机器的目录下查看启动日志,以便排查问题
[root@192 ~]# /home/hadoop/hadoop-2.7.2/sbin/start-dfs.sh
Starting namenodes on [192.168.127.128]
192.168.127.128: starting namenode, logging to /home/hadoop/hadoop-2.7.2/logs/hadoop-root-namenode-192.168.127.128.out
192.168.127.129: starting datanode, logging to /home/hadoop/hadoop-2.7.2/logs/hadoop-root-datanode-192.168.127.129.out
192.168.127.130: starting datanode, logging to /home/hadoop/hadoop-2.7.2/logs/hadoop-root-datanode-192.168.127.130.out
192.168.127.128: starting datanode, logging to /home/hadoop/hadoop-2.7.2/logs/hadoop-root-datanode-192.168.127.128.out
Starting secondary namenodes [192.168.127.130]
192.168.127.130: starting secondarynamenode, logging to /home/hadoop/hadoop-2.7.2/logs/hadoop-root-secondarynamenode-192.168.127.130.out八、安装成功展示页面
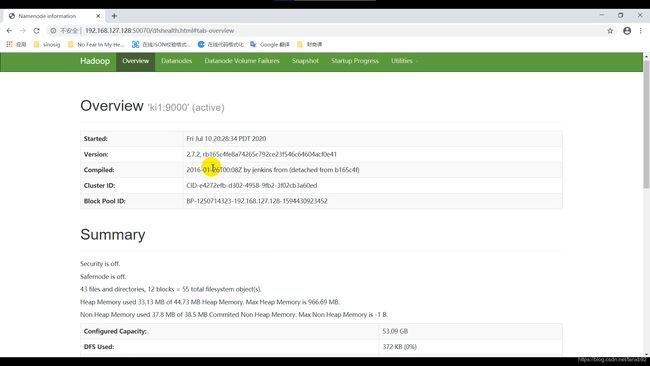
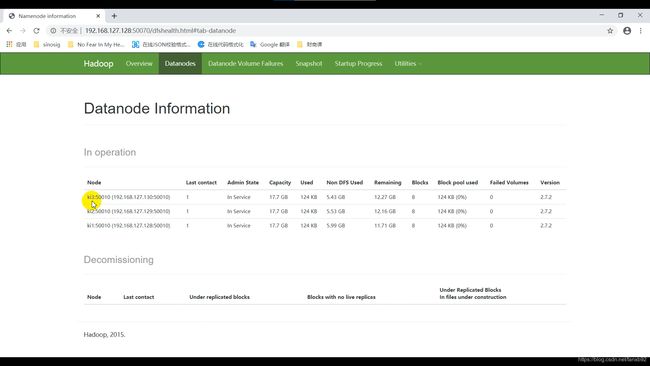
hdfs的页面展示,比如我的 NameNode安装在192.168.127.128节点,访问下面的链接:
http://192.168.127.128:50070/dfshealth.html#tab-datanode
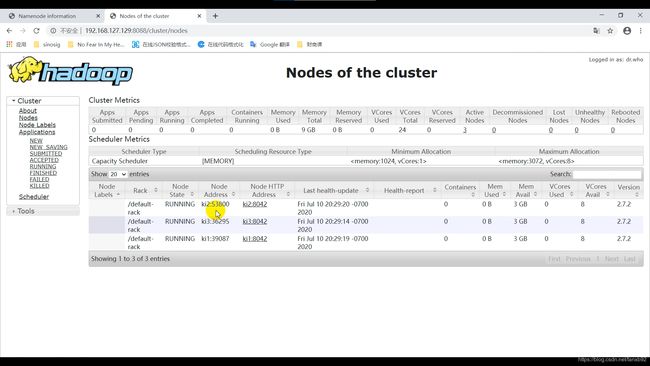
yarn的页面展示,比如我的ResourceManager安装在192.168.127.129节点,访问下面的链接:
http://192.168.127.129:8088
一些操作命令
#查看hadoop有哪些目录
hadoop fs -ls /
#创建目录
hadoop fs -mkdir /test
#上传文件
hadoop fs -put aa.txt /test/
#查看文件
hadoop fs -cat /test/aa.txt
#下载文件(test是本地目录)
hadoop fs -get /test/aa.txt test
hbase集群搭建(含zookeeper安装)
hbase基于Google的BigTable论文,是建立的hdfs之上,提供高可靠性、高性能、列存储、可伸缩、实时读 写的分布式数据库系统。在需要实时读写随机访问超大规模数据集时,可以使用hbase。
hbase的特点
1)海量存储 可以存储大批量的数据 hdfs。
2)列式存储 hbase表的数据是基于列族进行存储的,列族是在列的方向上的划分。
3)极易扩展 底层依赖HDFS,当磁盘空间不足的时候,只需要动态增加datanode节点服务(机器)就可以了可以通过增加服务器来提高集群的存储能力 。
4)高并发 支持高并发的读写请求。
5)稀疏 稀疏主要是针对Hbase列的灵活性,在列族中,你可以指定任意多的列,在列数据为空的情况下,是不 会占用存储空间的。
6)数据的多版本 hbase表中的数据可以有多个版本值,默认情况下是根据版本号去区分,版本号就是插入数据的时间戳 。
7)数据类型单一 所有的数据在hbase中是以字节数组进行存储 。
hbase整体架构
1、Client 客户端 Client包含了访问Hbase的接口 另外Client还维护了对应的cache来加速Hbase的访问,比如cache的.META.元数据的信息。
2、Zookeeper zookeeper集群 作用 实现了HMaster的高可用 保存了hbase的元数据信息,是所有hbase表的寻址入口 对HMaster和HRegionServer实现了监控 。
3、HMaster 作用 为HRegionServer分配Region 维护整个集群的负载均衡 维护集群的元数据信息,发现失效的Region,并将失效的Region分配到正常的HRegionServer上。
4、HRegionServer 负责管理Region 接受客户端的读写数据请求 切分在运行过程中变大的region 。
5、Region 每个HRegion由多个Store构成,每个Store保存一个列族(Columns Family),表有几个列族,则有几个 Store,每个Store由一个MemStore和多个StoreFile组成,MemStore是Store在内存中的内容,写到文件后 就是StoreFile。StoreFile底层是以HFile的格式保存。
一、zookeeper安装
(1)zookeeper下载
[root@localhost ~]# cd /usr/local/src/
[root@localhost src]# wget http://archive.apache.org/dist/zookeeper/zookeeper-3.4.14/zookeeper-3.4.14.tar.gz
[root@localhost src]# tar -zxvf zookeeper-3.4.14.tar.gz -C /home/zookeeper(2)进入安装目录,修改配置文件
[root@localhost src]# cd /home/zookeeper/zookeeper-3.4.14/(3)配置zoo.cfg
[root@localhost zookeeper-3.4.14]# cp conf/zoo_sample.cfg conf/zoo.cfg
[root@localhost zookeeper-3.4.14]# vim conf/zoo.cfg
#添加如下配置
tickTime=2000
dataDir=/home/zookeeper/zookeeper-3.4.14/data
dataLogDir=/home/zookeeper/zookeeper-3.4.14/logs
clientPort=2181
#创建上面配置的目录
[root@localhost zookeeper-3.4.14]# mkdir data logs(4)集群模式需要配置
#集群模式zoo.cfg还需要配置的内容
server.1=ki1:2287:3387
server.2=ki2:2288:3388
server.3=ki3:2289:3389
#在data目录下创建myid,并分别配置1、2、3,和上面的server.1、server.2、server.3对应
[root@localhost zookeeper-3.4.14]# vi data/myid(5)启动命令说明
/home/zookeeper/zookeeper-3.4.14/bin/zkServer.sh start
/home/zookeeper/zookeeper-3.4.14/bin/zkServer.sh stop
/home/zookeeper/zookeeper-3.4.14/bin/zkServer.sh restart
/home/zookeeper/zookeeper-3.4.14/bin/zkServer.sh status二、hbase安装
(1)hbase下载
[root@localhost ~]# cd /usr/local/src/
[root@localhost src]# wget http://archive.apache.org/dist/hbase/1.3.1/hbase-1.3.1-bin.tar.gz
[root@localhost src]# tar -zxvf hbase-1.3.1-bin.tar.gz -C /home/hbase(2)修改配置文件
hadoop配置文件拷贝(需要将hadoop中的配置,core-site.xml、hdfs-site.xml拷贝到hbase安装目录下的conf文件夹中)
[root@localhost src]# cd /home/hadoop/hadoop-2.7.2/etc/hadoop
[root@localhost hadoop]# cp core-site.xml hdfs-site.xml /home/hbase/hbase-1.3.1/conf/(3)配置hbase-env.sh
[root@localhost hadoop]# cd /home/hbase/hbase-1.3.1/conf/
[root@localhost conf]# vim hbase-env.sh
#添加java环境变量
export JAVA_HOME=/usr/lib/jvm/jre-1.8.0-openjdk-1.8.0.252.b09-2.el7_8.x86_64
#指定使用外部的zk集群
export HBASE_MANAGES_ZK=false(4)配置hbase-site.xml
[root@localhost conf]# vim hbase-site.xml
hbase.rootdir
hdfs://ki1:9000/hbase
hbase.cluster.distributed
true
hbase.zookeeper.quorum
ki1:2181,ki2:2181,ki3:2181
hbase.master.info.port
16010
(5)配置regionservers
[root@localhost conf]# vim regionservers
#指定regionserver节点
ki1
ki2
ki3(6)配置backup-masters
[root@localhost conf]# vi backup-masters #新创建该文件
#添加如下内容
ki3(7)其他节点配置同上
将配置文件拷贝到其他两台机器上,不用再分别下载安装了(注意差异配置)。但需要机器间进行ssh互通
[root@localhost conf]# cd /home/hbase
#需要分别在192.168.127.129和192.168.127.130两台机器上建立文件夹 mkdir /home/hbase -p
[root@localhost hbase]# scp -r /home/hbase/hbase-1.3.1 192.168.127.129:/home/hbase/hbase-1.3.1
[root@localhost hbase]# scp -r /home/hbase/hbase-1.3.1 192.168.127.130:/home/hbase/hbase-1.3.1(8)配置hbase的环境变量
所有节点都要配置
[root@localhost conf]# vim /etc/profile
#添加如下内容
#set hbase environment
export HBASE_HOME=/home/hbase/hbase-1.3.1
export PATH=$PATH:$HBASE_HOME/bin
#使环境变量生效
[root@localhost conf]# source /etc/profile(9)启停命令说明
/home/hbase/hbase-1.3.1/bin/start-hbase.sh #启动命令
/home/hbase/hbase-1.3.1/bin/stop-hbase.sh #停止命令(10)安装成功展示页面
在哪台机器启动就要访问对应的ip
http://192.168.127.130:16010/master-statu
