11-无监督学习之K-Means
tags: python,机器学习,KMeans,花式索引
文章目录
- K-Means算法含义
- K-Means主要最重大的缺陷:都和初始值有关:
- 总结:K-Means算法步骤:
- K-Means例程1
- K-Means进行图片压缩
- ndarray的花式索引(Fancy Indexing)与布尔索引
- 花式索引
- 布尔索引
K-Means算法含义
聚类的概念:一种无监督的学习,事先不知道类别,自动将相似的对象归到同一个簇中。
K-Means算法是一种无监督学习中聚类分析(cluster analysis)的算法,其主要是来计算数据聚集的算法,主要通过不断地取离种子点最近均值的算法。
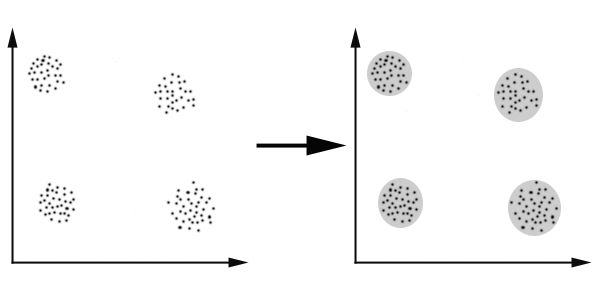
K-Means算法主要解决的问题如下图所示。我们可以看到,在图的左边有一些点,我们用肉眼可以看出来有四个点群,但是我们怎么通过计算机程序找出这几个点群来呢?于是就出现了我们的K-Means算法
K-Means主要最重大的缺陷:都和初始值有关:
K是事先给定的,这个K值的选定是非常难以估计的。很多时候,事先并不知道给定的数据集应该分成多少个类别才最合适。(解决方法:ISODATA算法通过类的自动合并和分裂,得到较为合理的类型数目K)
K-Means算法需要用初始随机种子点来搞,这个随机种子点太重要,不同的随机种子点会有得到完全不同的结果。(解决方法:K-Means++算法可以用来解决这个问题,其可以有效地选择初始点)
总结:K-Means算法步骤:
- 从数据中选择k个对象作为初始聚类中心;
- 计算每个聚类对象到聚类中心的距离来划分;
- 再次计算每个聚类中心
- 计算标准测度函数,直到达到最大迭代次数,则停止,否则,继续操作。
- 确定最优的聚类中心
K-Means例程1
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
data, target = make_blobs(random_state=3)
# 其中的n_clusters为类别个数,默认为8,此处应为3
# init为选择中心点的算法
kmeans = KMeans(n_clusters=3)
kmeans.fit(data)
# 分类的中心点
center = kmeans.cluster_centers_
# 分类之后的标签
labels = kmeans.labels_
x,y = np.linspace(data[:,0].min(),data[:,0].max(),1000), np.linspace(data[:,1].min(),data[:,1].max(),1000)
X, Y = np.meshgrid(x, y)
XY = np.c_[X.ravel(), Y.ravel()]
y_ = kmeans.predict(XY)
plt.pcolormesh(X, Y, y_.reshape(1000,1000))
plt.scatter(data[:,0],data[:,1],c=labels,cmap='rainbow')
plt.scatter(center[:,0],center[:,1],marker='o',s=200,c=['y','r','b'],alpha=0.7)
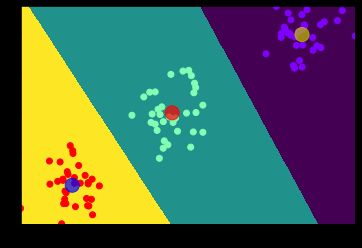
步骤:
- 导包,使用
make_blobs生成随机点 - 建立模型,训练数据,并进行数据预测,使用相同数据
- 无监督的情况下进行计算,预测 现在机器学习没有目标
- 绘制图形,显示聚类结果,如中心点:
kmeans.cluster_centers,分类标签:kmeans.labels_
K-Means进行图片压缩
import matplotlib.pyplot as plt
from sklearn.datasets import load_sample_image
from sklearn.utils import shuffle
from sklearn.cluster import KMeans
image = load_sample_image(image_name='china.jpg')
data = image.reshape(-1, 3)
# 使用无放回取样,从273280中取1000个
data_shuffle = shuffle(data)
kmeans = KMeans(64)
kmeans.fit(data_shuffle[:1000])
# 获取64种中心颜色
main_colors = kmeans.cluster_centers_
# 将原照片中所有的像素点的颜色进行分组,分到训练好的模型中的64种颜色中
labels = kmeans.predict(data)
img64 = main_colors[labels].reshape(* image.shape)/255
plt.figure(figsize=(20,18))
plt.subplot(1,2,1,title='origin img')
plt.imshow(image)
plt.subplot(1,2,2,title='ziped img')
plt.imshow(img64)

思路:
- 将颜色作为需要分类的特征值,所以需要将原来的图片中的所有像素点(427, 640, 3)变为2维的,使用
.reshape(-1, 3),压缩原有数据,重新分为n行3列,其中行数n,系统后自己计算。 - 由于直接使用上面的数据进行训练数据量太大,所以可以在其中随机获取1000个点,进行训练,使用
sklearn.utils中的shuffle,此方法不改变原有的数据,所以需要接收其返回值。 - 分好类之后,需要将64个类别中的所有类别的中心点的颜色,作为这64类的主颜色,压缩后的图片,将由这64种颜色组成。使用
kmeans.cluster_centers_获取中心点。 - 将原来的图片数据变为2维,分为3列,放入训练好的模型中进行预测,获取原来图片中所有点对应的类别,使用
kmeans.predict(data)预测 - 使用64个颜色中心点数据
main_colors和原图片的预测类别labels获取对应预测类别中对应的64种颜色。获取方法main_colors[labels]。获取后的数据大小和原始图片分为x行3列的数据大小一样。所以将该数据按照原图片的shape进行重新reshape,方法main_colors[labels].reshape(* image.shape)。但是由于模型计算的中心点颜色不是整数,并且这些数大于1,而图片颜色显示rgb如果是小数的话需要在0-1之间,或者是0-255直接的整数,所以可以将所有转换好的数据除以255。
上面步骤中的第5步是理解重点,尤其是
main_colors[labels]。其实这是ndarray的一种切片方法,类似与main_colors[[1,1,2,3,5,2,3],:],其也可以简化为main_colors[[1,1,2,3,5,2,3]],这种索引方法,叫花式索引。
ndarray的花式索引(Fancy Indexing)与布尔索引
来源:简书。链接:https://www.jianshu.com/p/743b3bb340f6
作者:大聖Jonathan
花式索引
花式索引是NumPy用来描述使用整型数组(这里的数组,可以是NumPy的数组,也可以是python自带的list)作为索引的术语,
其意义是根据索引数组的值作为目标数组的某个轴的下标来取值。
对于使用一维整型数组作为索引,如果目标是一维数组,那么索引的结果就是对应位置的元素;如果目标是二维数组,那么就是对应下标的行。
对于使用两个整型数组作为索引的时候,那么结果是按照顺序取出对应轴的对应下标的值。
特别注意,这两个整型数组的shape应该一致,或者其中一个数组应该是长度为1的一维数组(与NumPy的Broadcasting机制于关系)。例如,以[1,3,5],[2,4,6]这两个整型数组作为索引,那么对于二维数组,则取出(1,2),(3,4),(5,6)这些坐标对应的元素。
与花式索引类似的还有布尔索引。
布尔索引
布尔索引即给定一组布尔数据组成的数组,作为目标数据的索引值,来获取对应数据的方法。
使用时一定要注意,用来作为索引的布尔数组,其长度一定要和需要索引的维度长度一致。
例如:
arr = np.array([0,0,0,0,0,0]) + np.array([[0],[1],[2],[3],[4]])
arr
输出值如下:
array([[0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1],
[2, 2, 2, 2, 2, 2],
[3, 3, 3, 3, 3, 3],
[4, 4, 4, 4, 4, 4]])
其行长度为5,列宽度为6。
如果我们想只获取其第零行、第四行,组需要构建索引布尔数组为:[True,False,False,False,True],数组长度为5,和行长度一致。
如果想获取其第零列、第五列,则需要构建索引布尔数组为:[True,False,False,False,False,True],数组长度为6,和列宽度一致。
获取第零行、第四行数据代码:arr[[True,False,False,False,True]]
结果为:
array([[0, 0, 0, 0, 0, 0],
[4, 4, 4, 4, 4, 4]])
获取第零列、第五列数据代码:arr[:,[True,False,False,False,False,True]]
结果为:
array([[0, 0],
[1, 1],
[2, 2],
[3, 3],
[4, 4]])
另外布尔索引数组中的布尔值,可以为逻辑运算式。
代码
arr2 = np.array([0,1,2,3,4,5]) + np.array([[0],[1],[2],[3],[4]])
arr2
输出结果:
array([[0, 1, 2, 3, 4, 5],
[1, 2, 3, 4, 5, 6],
[2, 3, 4, 5, 6, 7],
[3, 4, 5, 6, 7, 8],
[4, 5, 6, 7, 8, 9]])
获取其中大于4的值:arr2[arr2>4]
结果:array([5, 5, 6, 5, 6, 7, 5, 6, 7, 8, 5, 6, 7, 8, 9])
同样可以将获取到的结果在原数组中对应的位置做修改:
arr2[arr2>4]=0
arr2
输出结果为:
array([[0, 1, 2, 3, 4, 0],
[1, 2, 3, 4, 0, 0],
[2, 3, 4, 0, 0, 0],
[3, 4, 0, 0, 0, 0],
[4, 0, 0, 0, 0, 0]])