Hive的数据存储
Hive的数据分为表数据和元数据,表数据是Hive中表格(table)具有的数据;而元数据是用来存储表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。下面分别来介绍。
一、Hive的数据存储
在让你真正明白什么是hive 博文中我们提到Hive是基于Hadoop分布式文件系统的,它的数据存储在Hadoop分布式文件系统中。Hive本身是没有专门的数据存储格式,也没有为数据建立索引,只需要在创建表的时候告诉Hive数据中的列分隔符和行分隔符,Hive就可以解析数据。所以往Hive表里面导入数据只是简单的将数据移动到表所在的目录中(如果数据是在HDFS上;但如果数据是在本地文件系统中,那么是将数据复制到表所在的目录中)。
Hive中主要包含以下几种数据模型:Table(表),External Table(外部表),Partition(分区),Bucket(桶)(本博客会专门写几篇博文来介绍分区和桶)。
1、表:Hive中的表和关系型数据库中的表在概念上很类似,每个表在HDFS中都有相应的目录用来存储表的数据,这个目录可以通过${HIVE_HOME}/conf/hive-site.xml配置文件中的 hive.metastore.warehouse.dir属性来配置,这个属性默认的值是/user/hive/warehouse(这个目录在 HDFS上),我们可以根据实际的情况来修改这个配置。如果我有一个表wyp,那么在HDFS中会创建/user/hive/warehouse/wyp 目录(这里假定hive.metastore.warehouse.dir配置为/user/hive/warehouse);wyp表所有的数据都存放在这个目录中。这个例外是外部表。
2、外部表:Hive中的外部表和表很类似,但是其数据不是放在自己表所属的目录中,而是存放到别处,这样的好处是如果你要删除这个外部表,该外部表所指向的数据是不会被删除的,它只会删除外部表对应的元数据;而如果你要删除表,该表对应的所有数据包括元数据都会被删除。
3、分区:在Hive中,表的每一个分区对应表下的相应目录,所有分区的数据都是存储在对应的目录中。比如wyp 表有dt和city两个分区,则对应dt=20131218,city=BJ对应表的目录为/user/hive/warehouse /dt=20131218/city=BJ,所有属于这个分区的数据都存放在这个目录中。
4、桶:对指定的列计算其hash,根据hash值切分数据,目的是为了并行,每一个桶对应一个文件(注意和分区的区别)。比如将wyp表id列分散至16个桶中,首先对id列的值计算hash,对应hash值为0和16的数据存储的HDFS目录为:/user /hive/warehouse/wyp/part-00000;而hash值为2的数据存储的HDFS 目录为:/user/hive/warehouse/wyp/part-00002。
来看下Hive数据抽象结构图

从上图可以看出,表是在数据库下面,而表里面又要分区、桶、倾斜的数据和正常的数据等;分区下面也是可以建立桶的。
二、Hive的元数据
Hive中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。 由于Hive的元数据需要不断的更新、修改,而HDFS系统中的文件是多读少改的,这显然不能将Hive的元数据存储在HDFS中。目前Hive将元数据存储在数据库中,如Mysql、Derby中。我们可以通过以下的配置来修改Hive元数据的存储方式
javax.jdo.option.ConnectionURL jdbc:mysql://localhost:3306/hive_hdp?characterEncoding=UTF-8 - &createDatabaseIfNotExist=true
JDBC connect string for a JDBC metastore javax.jdo.option.ConnectionDriverName com.mysql.jdbc.Driver Driver class name for a JDBC metastore javax.jdo.option.ConnectionUserName root username to use against metastore database javax.jdo.option.ConnectionPassword 123456 password to use against metastore database
当然,你还需要将相应数据库的启动复制到${HIVE_HOME}/lib目录中,这样才能将元数据存储在对应的数据库中。
Hive数据仓库的系统结构。
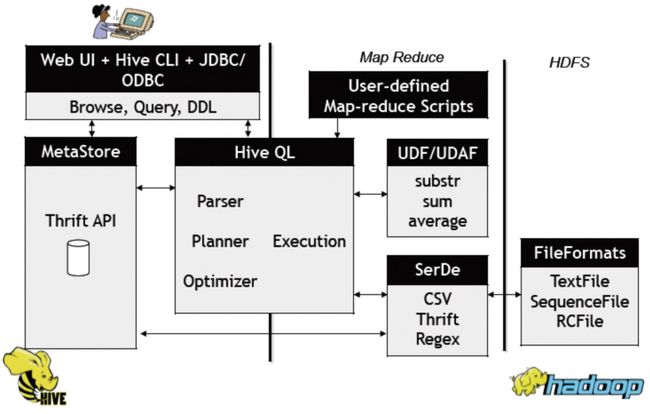
图1 Hive数据仓库的系统结构
基于MapReduce的数据仓库在超大规模数据分析中扮演了重要角色,对于典型的Web服务供应商,这些分析有助于它们快速理解动态的用户行为及变化的用户需求。
数据存储结构是影响数据仓库性能的关键因素之一。Hadoop系统中常用的文件存储格式有支持文本的TextFile和支持二进制的SequenceFile等,它们都属于行存储方式。Facebook工程师发表的RCFile: 《A Fast and Spaceefficient Data Placement Structure in MapReduce based Warehouse Systems》一文,介绍了一种高效的数据存储结构——RCFile(Record Columnar File),并将其应用于Facebook的数据仓库Hive中。与传统数据库的数据存储结构相比,RCFile更有效地满足了基于MapReduce的数据仓库的四个关键需求,即Fast data loading、Fast query processing、Highly efficient storage space utilization和Strong adaptivity to highly dynamic workload patterns。
数据仓库的需求
基于Facebook系统特征和用户数据的分析,在MapReduce计算环境下,数据仓库对于数据存储结构有四个关键需求。
Fast data loading
对于Facebook的产品数据仓库而言,快速加载数据(写数据)是非常关键的。每天大约有超过20TB的数据上传到Facebook的数据仓库,由于数据加载期间网络和磁盘流量会干扰正常的查询执行,因此缩短数据加载时间是非常必要的。
Fast query processing
为了满足实时性的网站请求和支持高并发用户提交查询的大量读负载,查询响应时间是非常关键的,这要求底层存储结构能够随着查询数量的增加而保持高速的查询处理。
Highly efficient storage space utilization
高速增长的用户活动总是需要可扩展的存储容量和计算能力,有限的磁盘空间需要合理管理海量数据的存储。实际上,该问题的解决方案就是最大化磁盘空间利用率。
Strong adaptivity to highly dynamic workload patterns
同一份数据集会供给不同应用的用户,通过各种方式来分析。某些数据分析是例行过程,按照某种固定模式周期性执行;而另一些则是从中间平台发起的查询。大多数负载不遵循任何规则模式,这需要底层系统在存储空间有限的前提下,对数据处理中不可预知的动态数据具备高度的适应性,而不是专注于某种特殊的负载模式。
MapReduce存储策略
要想设计并实现一种基于MapReduce数据仓库的高效数据存储结构,关键挑战是在MapReduce计算环境中满足上述四个需求。在传统数据库系统中,三种数据存储结构被广泛研究,分别是行存储结构、列存储结构和PAX混合存储结构。上面这三种结构都有其自身特点,不过简单移植这些数据库导向的存储结构到基于MapReduce的数据仓库系统并不能很好地满足所有需求。
行存储
如图2所示,基于Hadoop系统行存储结构的优点在于快速数据加载和动态负载的高适应能力,这是因为行存储保证了相同记录的所有域都在同一个集群节点,即同一个HDFS块。不过,行存储的缺点也是显而易见的,例如它不能支持快速查询处理,因为当查询仅仅针对多列表中的少数几列时,它不能跳过不必要的列读取;此外,由于混合着不同数据值的列,行存储不易获得一个极高的压缩比,即空间利用率不易大幅提高。尽管通过熵编码和利用列相关性能够获得一个较好的压缩比,但是复杂数据存储实现会导致解压开销增大。

图2 HDFS块内行存储的例子
列存储
图3显示了在HDFS上按照列组存储表格的例子。在这个例子中,列A和列B存储在同一列组,而列C和列D分别存储在单独的列组。查询时列存储能够避免读不必要的列,并且压缩一个列中的相似数据能够达到较高的压缩比。然而,由于元组重构的较高开销,它并不能提供基于Hadoop系统的快速查询处理。列存储不能保证同一记录的所有域都存储在同一集群节点,例如图2的例子中,记录的4个域存储在位于不同节点的3个HDFS块中。因此,记录的重构将导致通过集群节点网络的大量数据传输。尽管预先分组后,多个列在一起能够减少开销,但是对于高度动态的负载模式,它并不具备很好的适应性。除非所有列组根据可能的查询预先创建,否则对于一个查询需要一个不可预知的列组合,一个记录的重构或许需要2个或多个列组。再者由于多个组之间的列交叠,列组可能会创建多余的列数据存储,这导致存储利用率的降低。
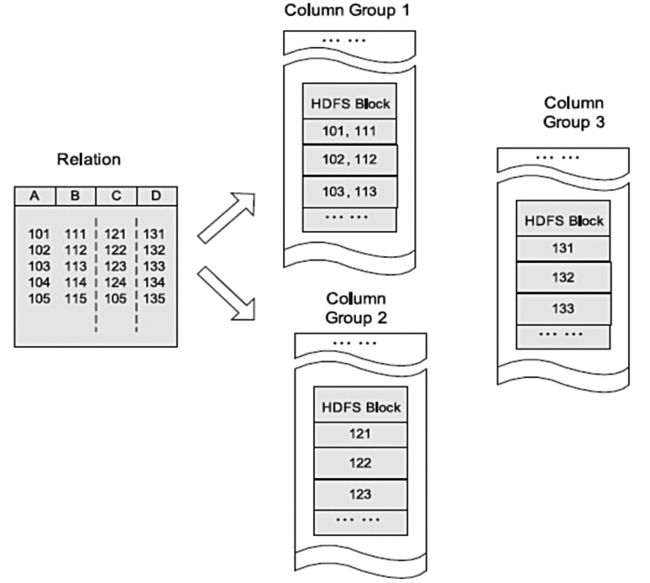
图3 HDFS块内列存储的例子
PAX混合存储
PAX存储模型(用于Data Morphing存储技术)使用混合存储方式,目的在于提升CPU Cache性能。对于记录中来自不同列的多个域,PAX将它们放在一个磁盘页中。在每个磁盘页中,PAX使用一个迷你页来存储属于每个列的所有域,并使用一个页头来存储迷你页的指针。类似于行存储,PAX对多种动态查询有很强的适应能力。然而,它并不能满足大型分布式系统对于高存储空间利用率和快速查询处理的需求,原因在于:首先,PAX没有数据压缩的相关工作,这部分与Cache优化关系不大,但对于大规模数据处理系统是非常关键的,它提供了列维度数据压缩的可能性;其次,PAX不能提升I/O性能,因为它不能改变实际的页内容,该限制使得大规模数据扫描时不易实现快速查询处理;再次,PAX用固定的页作为数据组织的基本单位,按照这个大小,在海量数据处理系统中,PAX将不会有效存储不同大小类型的数据域。
Hive文件存储格式
1.textfile
textfile为默认格式
存储方式:行存储
磁盘开销大 数据解析开销大
压缩的text文件 Hive无法进行合并和拆分
2.sequencefile
二进制文件,以
存储方式:行存储
可分割 压缩
一般选择block压缩
优势是文件和Hadoop api中的mapfile是相互兼容的。
3.rcfile
存储方式:数据按行分块 每块按照列存储
压缩快 快速列存取
读记录尽量涉及到的block最少
读取需要的列只需要读取每个row group 的头部定义。
读取全量数据的操作 性能可能比sequencefile没有明显的优势
4.orc
存储方式:数据按行分块 每块按照列存储
压缩快 快速列存取
效率比rcfile高,是rcfile的改良版本
5.自定义格式
用户可以通过实现inputformat和 outputformat来自定义输入输出格式。
Apache Parquet
源自于google Dremel系统(可下载论文参阅),Parquet相当于Google Dremel中的数据存储引擎,而Apache顶级开源项目Drill正是Dremel的开源实现。
Apache Parquet 最初的设计动机是存储嵌套式数据,比如Protocolbuffer,thrift,json等,将这类数据存储成列式格式,以方便对其高效压缩和编码,且使用更少的IO操作取出需要的数据,这也是Parquet相比于ORC的优势,它能够透明地将Protobuf和thrift类型的数据进行列式存储,在Protobuf和thrift被广泛使用的今天,与parquet进行集成,是一件非容易和自然的事情。 除了上述优势外,相比于ORC, Parquet没有太多其他可圈可点的地方,比如它不支持update操作(数据写成后不可修改),不支持ACID等。
Apache ORC
ORC(OptimizedRC File)存储源自于RC(RecordColumnar File)这种存储格式,RC是一种列式存储引擎,对schema演化(修改schema需要重新生成数据)支持较差,而ORC是对RC改进,但它仍对schema演化支持较差,主要是在压缩编码,查询性能方面做了优化。RC/ORC最初是在hive中得到使用,最后发展势头不错,独立成一个单独的项目。Hive 1.x版本对事务和update操作的支持,便是基于ORC实现的(其他存储格式暂不支持)。ORC发展到今天,已经具备一些非常高级的feature,比如支持update操作,支持ACID,支持struct,array复杂类型。你可以使用复杂类型构建一个类似于parquet的嵌套式数据架构,但当层数非常多时,写起来非常麻烦和复杂,而parquet提供的schema表达方式更容易表示出多级嵌套的数据类型。
总结:
textfile 存储空间消耗比较大,并且压缩的text 无法分割和合并 查询的效率最低,可以直接存储,加载数据的速度最高
sequencefile 存储空间消耗最大,压缩的文件可以分割和合并 查询效率高,需要通过text文件转化来加载
rcfile 存储空间最小,查询的效率最高 ,需要通过text文件转化来加载,加载的速度最低
相比传统的行式存储引擎,列式存储引擎具有更高的压缩比,更少的IO操作而备受青睐(注:列式存储不是万能高效的,很多场景下行式存储仍更加高效),尤其是在数据列(column)数很多,但每次操作仅针对若干列的情景,列式存储引擎的性价比更高。
在互联网大数据应用场景下,大部分情况下,数据量很大且数据字段数目很多,但每次查询数据只针对其中的少数几行,这时候列式存储是极佳的选择
Hive & Impala 中内置有对 Avro,Parquet 文件格式支持。在存储的过程中,也可以使用压缩编码器对数据进行压缩。
- Hive 常用文件格式: http://www.cnblogs.com/Richardzhu/p/3613661.html
- RCFile 介绍(翻译于 《Programing Hive》) :http://flyingdutchman.iteye.com/blog/1871025
- Hive 中的数据压缩(翻译于 《Programing Hive》):http://flyingdutchman.iteye.com/blog/1870878
Hive 中的常见数据格式的存储及压缩格式可以参考以上链接,以下将着重介绍 如何在 Hive 中使用Avro, Parquet 数据格式,以及使用 Snappy 压缩方法对数据进行压缩。
1 Avro 格式:Avro是一个数据序列化系统,设计用于支持大批量数据交换的应用。它的主要特点有:支持二进制序列化方式,可以便捷,快速地处理大量数据;动态语言友好,Avro提供的机制使动态语言可以方便地处理Avro数据。
Hive 0.9.1 版本新绑定 Avro SerDe (序列化器/反序列化器的简称),它允许 Hive 从表中读取数据和写回表.
|
Hive Versions
|
Avro Version
|
|---|---|
| Hive 0.9.1 | Avro 1.5.3 |
| Hive 0.10, 0.11, and 0.12 | Avro 1.7.1 |
| Hive 0.13 and 0.14 | Avro 1.7.5 |
你需要将Avro的schema复制到HDFS上, 并创建一个目录包含一些 Avro 股票记录的示例:
$ hadoop fs -put $HIP_HOME/schema schema
$ hadoop fs -mkdir stock_hive
$ hip hip.ch3.avro.AvroStockFileWrite \
--input test-data/stocks.txt \
--output stock_hive/stocks.avro


需要注意的是,以下创建表的格式是 Hive 通用的格式,但是在 Hive 0.14 及以后的版本里,在DDL语句中可以直接使用"STORED AS AVRO" 来指定表为Avro格式。AvroSerDe 会根据 Hive 表的Schema 来创建适合的 Avro Schema。这大大增加了 Avro 在 Hive 中的可用性。
详细请参考:https://cwiki.apache.org/confluence/display/Hive/AvroSerDe
 2.1 在定义中指定 schema
2.1 在定义中指定 schemahive> CREATE EXTERNAL TABLE tweets
> COMMENT "A table backed by Avro data with the
> Avro schema embedded in the CREATE TABLE statement"
> ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.avro.AvroSerDe'
> STORED AS
> INPUTFORMAT 'org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat'
> OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat'
> LOCATION '/user/wyp/examples/input/'
> TBLPROPERTIES (
> 'avro.schema.literal'='{
> "type": "record",
> "name": "Tweet",
> "namespace": "com.miguno.avro",
> "fields": [
> { "name":"username", "type":"string"},
> { "name":"tweet", "type":"string"},
> { "name":"timestamp", "type":"long"}
> ]
> }'
> );
Time taken: 0.076 secondshive> describe tweets;OK username string from deserializer tweet string from deserializer timestamp bigint from deserializer
将avro.schema.literal中的 schame 定义存放在一个文件中,比如:twitter.avsc
{
"type": "record",
"name": "Tweet",
"namespace": "com.miguno.avro",
"fields": [
{
"name": "username",
"type": "string"
},
{
"name": "tweet",
"type": "string"
},
{
"name": "timestamp",
"type": "long"
}
]
}
-- Create 外部表 tweets
CREATE
EXTERNAL
TABLE
tweets
COMMENT
"A table backed by Avro data with the Avro schema stored in HDFS"
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.avro.AvroSerDe'
STORED
AS
INPUTFORMAT
'org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat'
LOCATION
'/user/wyp/examples/input/'
TBLPROPERTIES (
'avro.schema.url'
=
'hdfs:///user/wyp/examples/schema/twitter.avsc'
);
-- Create 外部表 stocks
hive>
CREATE
EXTERNAL
TABLE
stocks
COMMENT
"An Avro stocks table"
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.avro.AvroSerDe'
STORED
AS
INPUTFORMAT
'org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat'
LOCATION
'/user/YOUR-HDFS-USERNAME/stock_hive/'
TBLPROPERTIES (
'avro.schema.url'
=
'hdfs:///user/YOUR-HDFS-USERNAME/schema/stock.avsc'
);
hive> describe tweets;
OK
username string from deserializer
tweet string from deserializer
timestamp bigint from deserializer
AvroSerDe 实际上支持4种方法来为 Avro Tasble 定义一个 Schema: (详细参考:https://cwiki.apache.org/confluence/display/Hive/AvroSerDe.)
- Use avro.schema.url -- 如上例 2.2
- Use schema.literal and embed the schema in the create statement
- Use avro.schema.literal and pass the schema into the script -- 如上例 2.1
- Use none to ignore either avro.schema.literal or avro.schema.url
你可以通过 Describe 关键词来查询一个 Hive 表的 Schema :
hive> describe stocks;
symbol string
date
string
open
double
high
double
low
double
close
double
volume
int
adjclose
double
运行一个 query 来确认是否完成了,可以通过如下的 hive Query Language (HiveQL) 来记录每个股票代码的数量 -- stock symbol:
hive>
SELECT
symbol,
count
(*)
FROM
stocks
GROUP
BY
symbol;
AAPL 10
CSCO 10
GOOG 5
MSFT 10
2 Parquet 格式:
Hive 要求数据已经存在于目录里面,所有你需要创建一个目录 并且将股票的Parquet格式文件复制过去 :
$ hadoop fs -mkdir parquet_avro_stocks $ hadoop fs -cp stocks.parquet parquet_avro_stocks
接下来,您将创建一个Hive外部表并且定义它的模式。如果你不能确定结构模式, 你可以通过以下方法来查看需要处理 Parquet 文件的 Schema 信息(使用 Parquet tools 中的 Schema 命令):
2.1. 使用 Parquet tools 来查看 Parquet文件的 schema 信息:
$ hip --nolib parquet.tools.Main schema stocks.parquet
message hip.ch3.avro.gen.Stock {
required binary symbol (UTF8);
required binary date (UTF8);
required double open;
required double high;
required double low;
required double close;
required int32 volume;
required double adjClose;
}
比如说 Avro, 使用元数据来存储 Avro的Schema,你可以通过以下命令查看输出:
$ hip --nolibparquet.tools.Main meta stocks.parquetcreator: parquet-mr(build 3f25ad97f20...)extra: avro.schema = {"type":"record","name":"Stock","namespace"...file schema: hip.ch3.avro.gen.Stock---------------------------------------------------------------------symbol: REQUIRED BINARY O:UTF8R:0 D:0date: REQUIRED BINARY O:UTF8R:0 D:0open: REQUIRED DOUBLER:0 D:0high: REQUIRED DOUBLER:0 D:0low: REQUIRED DOUBLER:0 D:0close: REQUIRED DOUBLER:0 D:0volume: REQUIRED INT32R:0 D:0adjClose: REQUIRED DOUBLER:0 D:0rowgroup1: RC:45 TS:2376---------------------------------------------------------------------symbol: BINARY SNAPPY DO:0 FPO:4 SZ:85/84/0.99 VC:45 ENC:PD ...date: BINARY SNAPPY DO:0 FPO:89 SZ:127/198/1.56 VC:45 ENC ...open: DOUBLE SNAPPY DO:0 FPO:216 SZ:301/379/1.26 VC:45 EN ...high: DOUBLE SNAPPY DO:0 FPO:517 SZ:297/379/1.28 VC:45 EN ...low: DOUBLE SNAPPY DO:0 FPO:814 SZ:292/379/1.30 VC:45 EN ...close: DOUBLE SNAPPY DO:0 FPO:1106 SZ:299/379/1.27 VC:45 E ...volume: INT32 SNAPPY DO:0 FPO:1405 SZ:203/199/0.98 VC:45 EN ...adjClose: DOUBLE SNAPPY DO:0 FPO:1608 SZ:298/379/1.27 VC:45 E ...
2.3.将 Hive 中的数据存储为 Parquet 格式 -- Hive 0.13
hive>
CREATE
EXTERNAL
TABLE
parquet_stocks(
symbol string,
date
string,
open
double
,
high
double
,
low
double
,
close
double
,
volume
int
,
adjClose
double
) STORED
AS
PARQUET
LOCATION
'/user/YOUR_USERNAME/parquet_avro_stocks'
;
hive> select distinct(symbol) from parquet_stocks; AAPL CSCO GOOG MSFT YHOO
You can use the same syntax to create the table in Impala.
3. 使用 Sanppy 压缩编码来将数据写入到新表中 / 或者可以将压缩后的数据文件 copy 到 HDFS 中数据定义目录下面。
3.1 从旧表进行复制数据“:
hive>
SET
hive.
exec
.compress.
output
=
true
;
hive>
SET
avro.
output
.codec =
snappy
;
hive>
CREATE
TABLE
google_stocks
COMMENT
"An Avro stocks table containing just Google stocks"
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.avro.
AvroSerDe
'
STORED
AS
INPUTFORMAT
'org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat'
TBLPROPERTIES (
'avro.schema.url'
=
'hdfs:///user/YOUR-USERNAME/schema/stock.avsc'
);
OK
hive>
INSERT
OVERWRITE
TABLE
google_stocks
SELECT
*
FROM
stocks
WHERE
symbol =
'GOOG'
;
OK
读取新表数据:
hive>
select
*
from
google_stocks limit 5;
OK
GOOG 2009-01-02 308.6 321.82 305.5 321.32 3610500 321.32
GOOG 2008-01-02 692.87 697.37 677.73 685.19 4306900 685.19
GOOG 2007-01-03 466.0 476.66 461.11 467.59 7706500 467.59
GOOG 2006-01-03 422.52 435.67 418.22 435.23 13121200 435.23
GOOG 2005-01-03 197.4 203.64 195.46 202.71 15844200 202.71
3.2 压缩前我们的数据:
{
"username": "miguno",
"tweet": "Rock: Nerf paper, scissors is fine.",
"timestamp": 1366150681
},
{
"username": "BlizzardCS",
"tweet": "Works as intended. Terran is IMBA.",
"timestamp": 1366154481
},
{
"username": "DarkTemplar",
"tweet": "From the shadows I come!",
"timestamp": 1366154681
},
{
"username": "VoidRay",
"tweet": "Prismatic core online!",
"timestamp": 1366160000
}
3.3 压缩完的数据假如存放在/home/wyp/twitter.avsc文件中,我们将这个数据复制到HDFS中的/user/wyp/examples/input/目录下:
Hadoop fs -put /home/wyp/twitter.avro /user/wyp/examples/input/
3.4 读取压缩后的数据:
hive> select * from tweets limit 5;;OKmiguno Rock: Nerf paper, scissors is fine. 1366150681BlizzardCS Works as intended. Terran is IMBA. 1366154481DarkTemplar From the shadows I come! 1366154681VoidRay Prismatic core online! 1366160000Time taken: 0.495 seconds, Fetched: 4 row(s)