hadoop,zookeeper,kafka集群搭建(详细)
hadoop,zookeeper,kafka集群搭建
- 准备工作
- ifcfg-ens33
- hostname
- hosts
- 解压并改名
- 配置集群(jdk)环境及密钥
- 配置jdk环境
- 配置密钥
- hadoop配置
- hadoop 环境变量配置
- 格式化hdfs
- zookeeper 配置
- 文件配置
- zookeeper 环境变量配置
- Kafka配置
- server.properties配置
- kafka环境变量配置
- 脚本文件
- 修改另外2台电脑配置文件
- 修改zookeeper的myid文件
- 修改kafka的broker.id的值
- 脚本文件内容
本文以3台机器进行集群搭建。
准备工作
配置好 每台机器的IP hostname hosts
ifcfg-ens33
# ifcfg-ens33
vi /etc/sysconfig/network-scripts/ifcfg-ens33
IPADDR=192.168.48.211
IPADDR=192.168.48.212
IPADDR=192.168.48.213
hostname
# hostname
hostnamectl set-hostname ???
c11
c12
c13
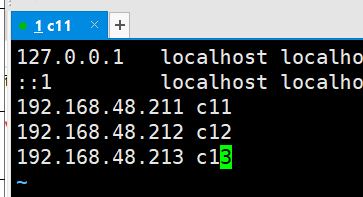
hosts
ps:这个必须每台机器都要写全!!!
# hosts
vi /etc/hosts
192.168.48.211 c11
192.168.48.212 c12
192.168.48.213 c13
拷贝需要安装的软件到c11中
[root@c11 ~]# cd /opt
[root@c11 opt]# mkdir install
[root@c11 opt]# mkdir bigdata

解压并改名
[root@c11 ~]# cd /opt/
[root@c11 opt]# ls
bigdata install
[root@c11 opt]# cd install/
[root@c11 install]# ll
total 689288
-rw-r--r--. 1 root root 433895552 Jun 3 23:44 hadoop-2.6.0-cdh5.14.2.tar.gz
-rw-r--r--. 1 root root 181442359 Jun 3 23:44 jdk-8u111-linux-x64.tar.gz
-rw-r--r--. 1 root root 55751827 Jun 3 23:43 kafka_2.11-2.0.0.tgz
-rw-r--r--. 1 root root 34731946 Jun 3 23:43 zookeeper-3.4.5-cdh5.14.2.tar.gz
[root@c11 install]# tar -zxf hadoop-2.6.0-cdh5.14.2.tar.gz -C ../bigdata/
[root@c11 install]# tar -zxf jdk-8u111-linux-x64.tar.gz -C ../bigdata/
[root@c11 install]# tar -zxf kafka_2.11-2.0.0.tgz -C ../bigdata/
[root@c11 install]# tar -zxf zookeeper-3.4.5-cdh5.14.2.tar.gz -C ../bigdata/
[root@c11 install]# cd ../bigdata/
[root@c11 bigdata]# ls
hadoop-2.6.0-cdh5.14.2 kafka_2.11-2.0.0
jdk1.8.0_111 zookeeper-3.4.5-cdh5.14.2
[root@c11 bigdata]# mv jdk1.8.0_111/ jdk180
[root@c11 bigdata]# mv hadoop-2.6.0-cdh5.14.2/ hadoop260
[root@c11 bigdata]# mv zookeeper-3.4.5-cdh5.14.2/ zk345
[root@c11 bigdata]# mv kafka_2.11-2.0.0/ kafka211
[root@c11 bigdata]# ls
hadoop260 jdk180 kafka211 zk345
配置集群(jdk)环境及密钥
配置jdk环境
[root@c11 bigdata]# cd /etc/profile.d/
[root@c11 profile.d]# touch env.sh
[root@c11 profile.d]# vi ./env.sh
# 在env.sh 文件中配置java jdk 环境
export JAVA_HOME=/opt/bigdata/jdk180
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
# 记得 source 一下
[root@c11 profile.d]# source ./env.sh
配置密钥
密钥在c11(211) c12(212)
[root@c11 profile.d]# ssh-keygen -t rsa
## 然后进行两次回车就行,就生成了,效果图如下图。
## 接下来就是将密钥拷贝到每台机器上
[root@c11 profile.d]# ssh-copy-id c11
[root@c11 profile.d]# ssh-copy-id c12
[root@c11 profile.d]# ssh-copy-id c13
[root@c12 profile.d]# ssh-keygen -t rsa
[root@c12 profile.d]# ssh-copy-id c11
[root@c12 profile.d]# ssh-copy-id c12
[root@c12 profile.d]# ssh-copy-id c13

hadoop配置
需要配置如下文件:
hadoop-env.sh
mapred-env.sh
yarn-env.sh
slaves
core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml
[root@c11 hadoop260]# mkdir hadoop2
[root@c11 hadoop260]# cd ./etc/hadoop
hadoop-env.sh
[root@c11 hadoop]# vi hadoop-env.sh
export JAVA_HOME=/opt/bigdata/jdk180
mapred-env.sh
[root@c11 hadoop]# vi mapred-env.sh
export JAVA_HOME=/opt/bigdata/jdk180
yarn-env.sh
[root@c11 hadoop]# vi yarn-env.sh
export JAVA_HOME=/opt/bigdata/jdk180
slaves
[root@c11 hadoop]# vi ./slaves
c11
c12
c13
core-site.xml
[root@c11 hadoop]# vi core-site.xml
fs.defaultFS
hdfs://c11:9000
hadoop.tmp.dir
/opt/bigdata/hadoop260/hadoop2
hadoop.proxyuser.root.hosts
*
hadoop.proxyuser.root.groups
*
hdfs-site.xml
[root@c11 hadoop]# vi hdfs-site.xml
dfs.replication
3
dfs.namenode.secondary.http-address
c13:50090
mapred-site.xml
[root@c11 hadoop]# cp mapred-site.xml.template mapred-site.xml
[root@c11 hadoop]# vi mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
c11:10020
mapreduce.jobhistory.webapp.address
c11:19888
yarn-site.xml
[root@c11 hadoop]# vi yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
yarn.resourcemanager.hostname
c11
yarn.log-aggregation-enable
true
yarn.log-aggregation.retain-seconds
604800
hadoop 环境变量配置
[root@c11 hadoop]# vi /etc/profile.d/env.sh
export HADOOP_HOME=/opt/bigdata/hadoop260
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
[root@c11 hadoop]# source /etc/profile.d/env.sh
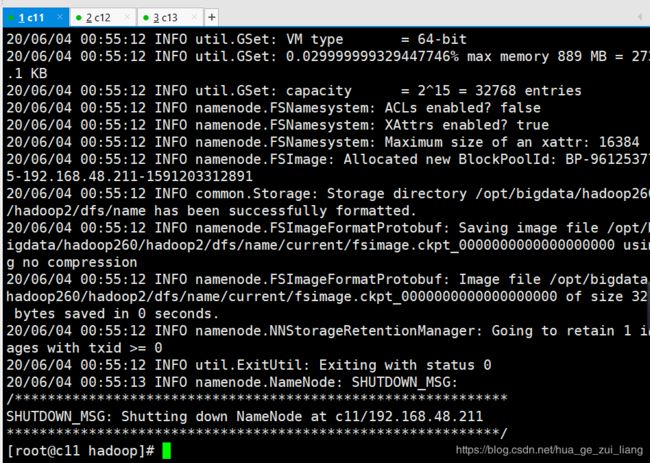
格式化hdfs
[root@c11 hadoop]# hadoop namenode -format
效果图:
zookeeper 配置
文件配置
# 创建zkData文件夹
[root@c11 zk345]# mkdir zkData
[root@c11 zk345]# cd zkData/
[root@c11 zkData]# ll
total 0
# 在zkData中创建myid文件,给定数字
[root@c11 zkData]# touch myid
[root@c11 zkData]# vi myid
1
[root@c11 zkData]# cd ../conf/
[root@c11 conf]# ls
configuration.xsl log4j.properties zoo_sample.cfg
[root@c11 conf]# cp zoo_sample.cfg zoo.cfg
[root@c11 conf]# vi ./zoo.cfg
dataDir=/opt/bigdata/zk345/zkData
server.1=c11:2287:3387
server.2=c12:2287:3387
server.3=c13:2287:3387
zookeeper 环境变量配置
[root@c11 conf]# vi /etc/profile.d/env.sh
export ZOOKEEPER_HOME=/opt/bigdata/zk345
export PATH=$PATH:$ZOOKEEPER_HOME/bin
[root@c11 conf]# source /etc/profile.d/env.sh
Kafka配置
server.properties配置
[root@c11 conf]# cd /opt/bigdata/kafka211/config/
[root@c11 config]# ls
connect-console-sink.properties consumer.properties
connect-console-source.properties log4j.properties
connect-distributed.properties producer.properties
connect-file-sink.properties server.properties
connect-file-source.properties tools-log4j.properties
connect-log4j.properties trogdor.conf
connect-standalone.properties zookeeper.properties
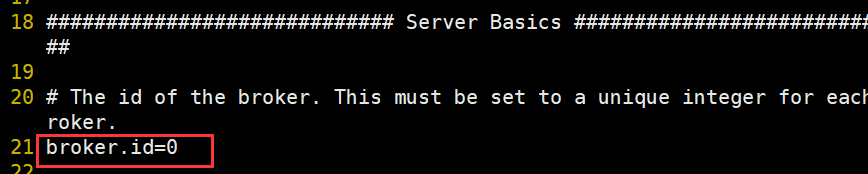
[root@c11 config]# vi server.properties
broker.id=0 # 每台机器的的id不能相同
log.dirs=/opt/bigdata/kafka211/logs
zookeeper.connect=c11:2181,c12:2181,c13:2181
delete.topic.enable=true
[root@c11 kafka211]# mkdir logs
[root@c11 kafka211]# ls
bin config libs LICENSE logs NOTICE site-docs
如果单配kafka也可以参考kafka配置,因为此处是集群,所以需要改动一点



kafka环境变量配置
[root@c11 hadoop]# vi /etc/profile.d/env.sh
export KAFKA_HOME=/opt/bigdata/kafka211
export PATH=$PATH:$KAFKA_HOME/bin
记得source一下
[root@c11 hadoop]# source /etc/profile.d/env.sh
脚本文件
[root@c11 kafka211]# cd
[root@c11 ~]# pwd
/root
[root@c11 ~]# mkdir bin
[root@c11 ~]# cd ./bin/
[root@c11 bin]# ls
kfkop.sh showjps.sh xrsync zkop.sh

可以点击此处去下载bin文件夹(也可以在本文最后面有脚本文件内容)

[root@c11 bin]# chmod 777 showjps.sh
[root@c11 bin]# chmod 777 kfkop.sh
[root@c11 bin]# chmod 777 xrsync
[root@c11 bin]# chmod 777 zkop.sh
[root@c11 bin]# yum install rsync -y
[root@c12 ~]# yum install rsync -y
[root@c13 ~]# yum install rsync -y
[root@c11 bin]# xrsync /opt/bigdata/jdk180/
[root@c11 bin]# xrsync /opt/bigdata/hadoop260/
[root@c11 bin]# xrsync /opt/bigdata/zk345/
[root@c11 bin]# xrsync /opt/bigdata/kafka211/
修改另外2台电脑配置文件
修改zookeeper的myid文件
[root@c12 zk345]# cd ./zkData/
[root@c12 zkData]# ld
ld: no input files
[root@c12 zkData]# ls
myid
[root@c12 zkData]# vi myid
2
[root@c13 zkData]# vi myid
3
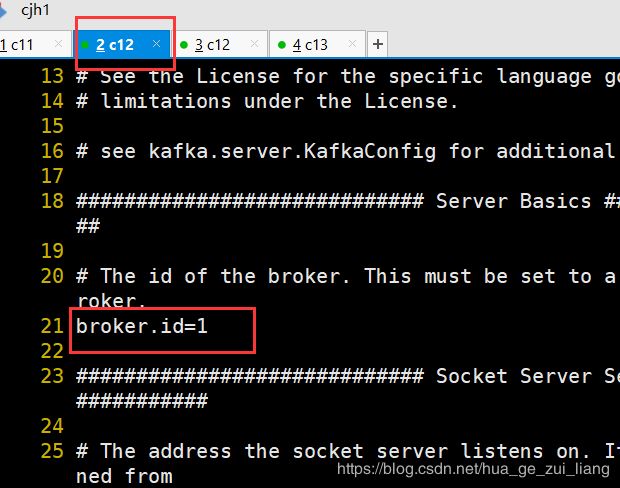
修改kafka的broker.id的值
21 broker.id=1
21 broker.id=2

脚本文件内容
ps:要是没找到bin下载文件夹,下面为内容:

[root@c11 bin]# vi xrsync
#!/bin/bash
#1 获取输入参数个数,如果参数个数没有,退出
pcount=$#
if((pcount==0));then
echo no agrs;
exit;
fi
#2 获取文件名
p1=$1
fname=`basename $p1`
echo fname=$fname
#3 获取上级目录的绝对路径
pdir=`cd -P $(dirname $p1);pwd`
echo pdir=$pdir
#4 获取当前用户名字
user=`whoami`
#5 将文件拷贝到目标机器
for host in c11 c12 c13
do
echo ---------- $host --------------
rsync -av $pdir/$fname $user@$host:$pdir
done
[root@c11 bin]# vi showjps.sh
#!/bin/bash
for host in c11 c12 c13
do
echo --------- $host ----------
ssh $host "$*"
done
[root@c11 bin]# vi zkop.sh
#!/bin/bash
# start stop status
case $1 in
"start"){
for i in c11 c12 c13
do
ssh $i "/opt/bigdata/zk345/bin/zkServer.sh start"
done
};;
"stop"){
for i in c11 c12 c13
do
ssh $i "/opt/bigdata/zk345/bin/zkServer.sh stop"
done
};;
"status"){
for i in c11 c12 c13
do
ssh $i "/opt/bigdata/zk345/bin/zkServer.sh status"
done
};;
esac
[root@c11 bin]# vi kfkop.sh
#!/bin/bash
case $1 in
"start"){
for i in c11 c12 c13
do
echo ------$i 启动KAFKA---------
ssh $i "/opt/bigdata/kafka211/bin/kafka-server-start.sh -daemon /opt/bigdata/kafka211/config/server.properties"
done
};;
"stop"){
for i in c11 c12 c13
do
echo ------$i 关闭KAFKA---------
ssh $i "/opt/bigdata/kafka211/bin/kafka-server-stop.sh"
done
};;
esac
ps:此三种集群搭建完成~
ps:望多多支持,后续更新中…