python数据降维的几个常用操作
一、基于特征选择的降维
基于sklearn的feature_selection进行特征选择
SelectPercentile
将变量集中的特征变量与目标变量根据指定函数进行分析打分,只保留用户指定百分比的最高得分的特征
from sklearn import feature_selection
from sklearn.feature_selection import f_classif
# 默认使用f_classif进行分析打分,precentile=30表示只保留30%的特征
selector_1 = feature_selection.SelectPercentile(score_func=f_classif,percentile=30)
# x为输入的变量集,y为目标变量
sel_features1 = selector_1.fit_transform(x, y)
VarianceThreshold
保留高于指定**阈值(方差)**的特征
from sklearn import feature_selection
selector_2 = feature_selection.VarianceThreshold(1) # 保留阈值即方差大于1的特征
sel_features2 = selector_2.fit_transform(x)
RFE
添加一个评估器计算各特征的权重分配,递推地去掉不重要的特征,最后保留指定数量特征
from sklearn import feature_selection
from sklearn.svm import SVC
model_svc = SVC(kernel="linear") # 增加评估器
selector_3 = feature_selection.RFE(model_svc, 3) # 代入评估器,并指定保留3个最高分的特征
sel_features3 = selector_3.fit_transform(x, y)
SelectFromModel
指定一个模型,通过设置特征重要性阈值选择特征
from sklearn import feature_selection
from sklearn.linear_model import LogisticRegression
model = LogisticRegression() # 建立模型对象
# 代入模型,并设置阈值
selector_4 = feature_selection.SelectFromModel(estimator=LogisticRegression(),threshold=0.5)
sel_features4 = selector_4.fit_transform(x, y)
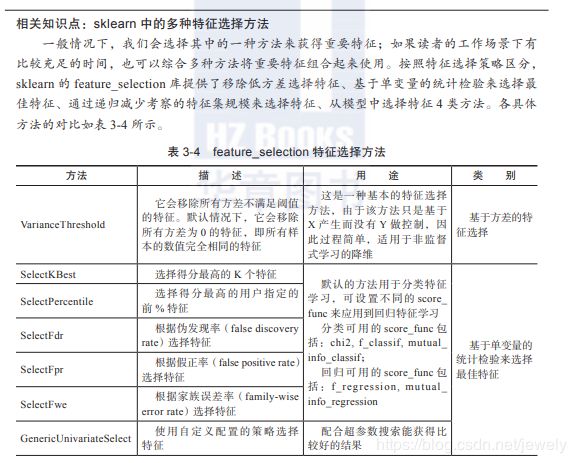

二、基于特征转换的降维
LDA
线性判别式分析,数据集带有Label(分类标志),使用LDA进行特征转换,得到新的特征,新特征的数量≤Label中唯一值的个数,若目标变量唯一值数量有n个,可指定的特征个数最多为n-1个
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA
model_lda = LDA() # 建立LDA模型对象
model_lda.fit(x, y) # 将数据集输入模型并训练
convert_features = model_lda.transform(x) # 转换数据
三、基于特征组合的降维
GBDT
from sklearn.ensemble import GradientBoostingClassifier as GBDT
model_gbdt = GBDT()
model_gbdt.fit(x, y)
conbine_features = model_gbdt.apply(x)[:, :, 0]
PolynomialFeatures
生成多项式,先指定多项式的项数(degree)
n个特征的变量集,转换后的得到的多项式第1列的值为1,第2列到第n+1列为原始特征值,后面的列为原始特征之间的乘积,若指定的多项式项数为3,则为两个特征之间所有可能的相互乘积和三个特征之间所有可能的相互乘积
from sklearn.preprocessing import PolynomialFeatures as plf
model_plf = plf(2)
plf_features = model_plf.fit_transform(x)
model_plf.get_feature_names() # 查看每个特征的名称,即由哪些原始特征进行了相互乘积
gplearn.genetic
Gplearn的库主要有以下2个:
- SymbolicRegressor(符号回归)是一种机器学习技术,旨在识别最能描述关系的基础数学表达式。它首先建立一个简单随机公式的数量来表示已知的自变量与其因变量目标之间的关系,以预测新数据。它可以利用遗传算法得到的公式,直接预测目标变量的值,因此属于回归应用的一种方法。
- SymbolicTransformer(符号转换器)是一种监督式的特征处理技术,它首先建立一组简单的随机公式来表示关系,然后通过从群体中选择最适合的个体进行遗传操作,最终找出最适合彼此相关性最小的个体。本例就用了该方法,它是在特征工程过程中,非常有效的做特征转换和组合的方法。
- n_components:设置组合后的特征数
- generations:设置演变迭代的次数
- function_set:设置特征组合函数,默认功能函数包括add、sub、mul、div
- max_samples:设置从x中每次抽取的样本的比例
- meric:设置拟合指标,该指标可设置为pearson(默认)或spearman,当组合的特征后面使用树分类器(例如随机森林、GBDT等)时,建议设置为spearman;如果后面使用线性模型做拟合时,建议设置为pearson
- random_state:用来控制每次随机时使用相同的初始化种子,避免由于初始随机的不同导致结果的差异
- n_jobs:用来控制参与计算的CPU核心的个数,-1表示全部CPU资源
from gplearn.genetic import SymbolicTransformer
from sklearn import datasets
raw_data = datasets.load_boston() # 加载数据集
x, y = raw_data.data, raw_data.target # 分割形成x和y
model_symbolic = SymbolicTransformer(n_components=5, generations=18,
function_set=(
'add', 'sub', 'mul', 'div', 'sqrt', 'log', 'abs', 'neg',
'inv','max', 'min'),
max_samples=0.9, metric='pearson',
random_state=0, n_jobs=2)
model_symbolic.fit(x, y) # 训练数据
symbolic_features = model_symbolic.transform(x) # 转换数据
print(symbolic_features.shape) # 打印形状
print(symbolic_features[0]) # 打印第1条数据
print(model_symbolic) # 输出公式